







唠一唠
在做项目的时候觉得自己还有很多MyBatis基础不牢,于是下定决心从头开始复习。先整理一下之前java课上的知识点。
Java工作原理
Java既是编译型语言也是解释型语言
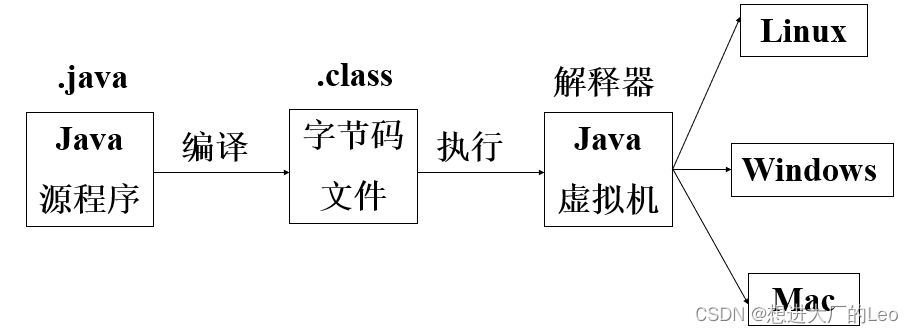
编译器先将**.java程序编译为.class字节码文件**,JVM对字节码文件解释执行
数组
声明方式
int x[ ] = new int[2];
int a[][] = new int [2][3];
类和对象
构造方法没有返回值,也没有void
初始化代码块直接就是{},在new的时候就先执行了,先定义的先执行,后定义的后执行
静态变量和静态方法 static
一个类共用一个静态变量,访问需要类名.变量,不要声明类即可使用
一个类的静态方法不需要声明类即可使用,可以访问静态成员,包括静态变量和静态方法,因为不依赖于对象,所以不能访问非静态的成员,也不能使用this
也有静态的初始化代码块
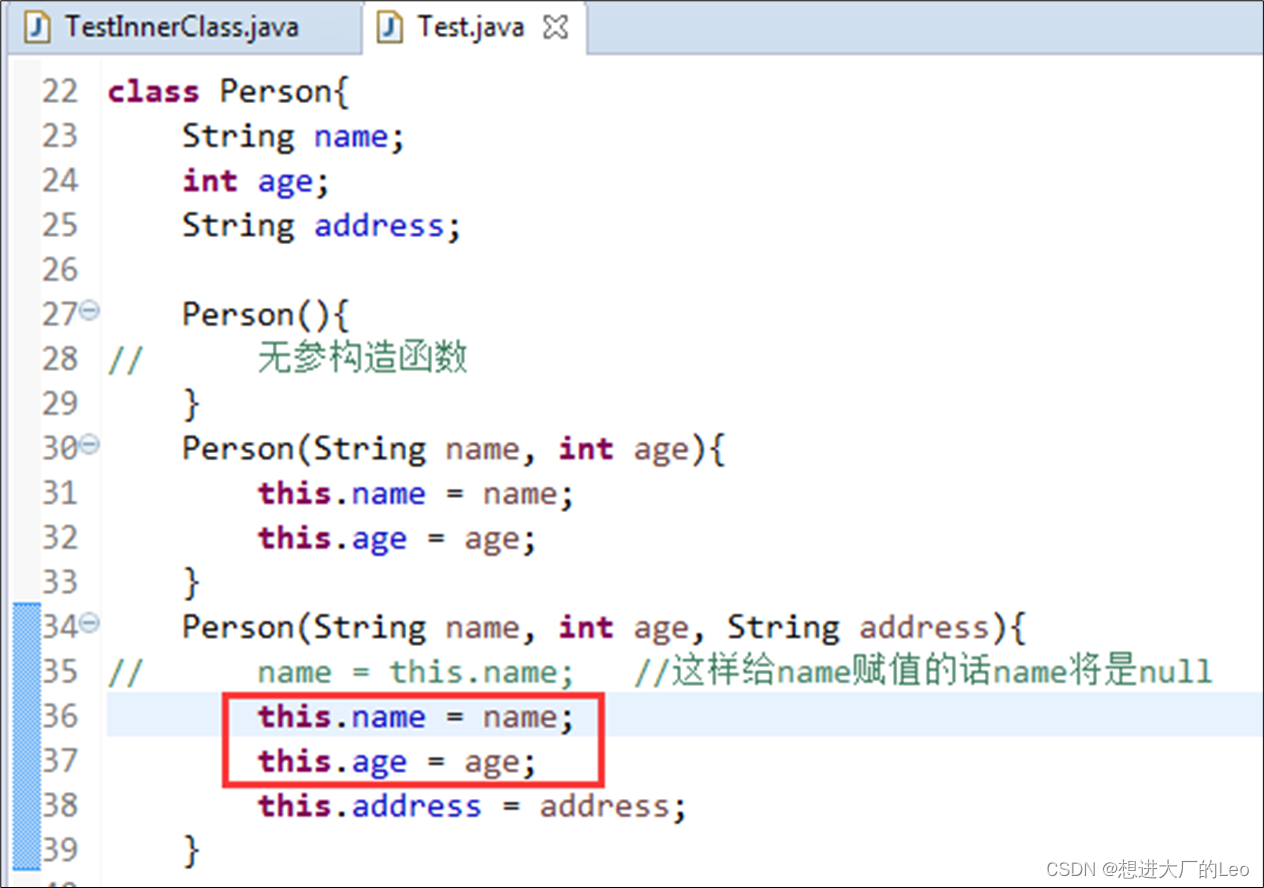
this
-
函数参数或者函数中的局部变量和成员变量同名的情况下,成员变量被屏蔽,此时要访问成员变量则需要用“this.成员变量名”的方式来引用成员变量。
-
一个构造方法中调用另一个构造方法。
-
表示当前对象
继承
在子类中调用父类构造方法的语法格式为:super ( );
用super.调用父类成员
Class类
Class类封装一个对象和接口运行时的状态,当装载类时,Class类型的对象自动创建。有以下3种方法可以获取Class的对象。
方法1:调用Object类的getClass()方法。
方法2:使用Class类的forName()方法。
方法3:如果T是一个Java类型,那么T.class就代表了与该类型匹配的Class对象。例如,String.class代表字符串类型,int.class代表整数类型。
一般用来得到类名,getName()
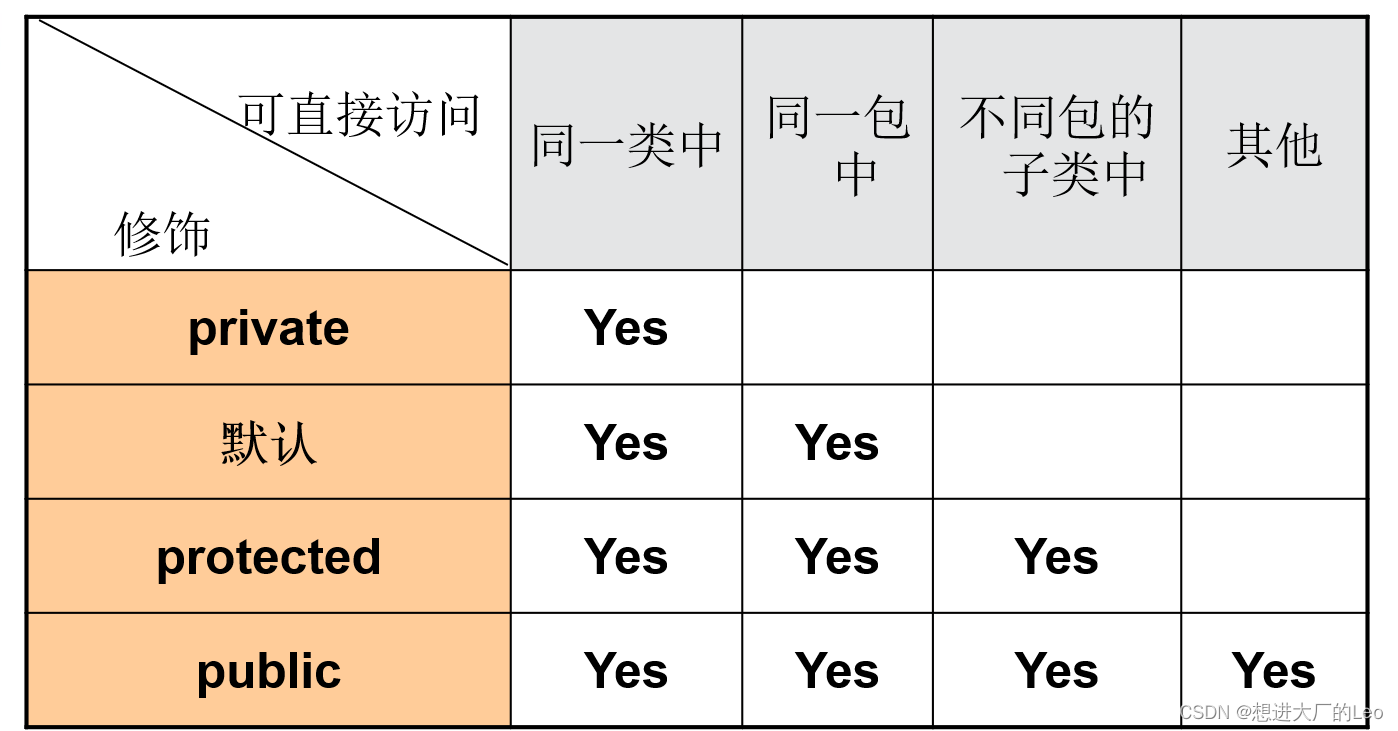
访问修饰符
引用类型转换
Java 中引用类型之间的类型转换(前提是两个类是父子关系)主要有两种,分别是向上转型和向下转型
Animal animal = new Animal();
等号左边是类型声明,等号右边是对象实例
向上转型
父类引用指向子类的对象
特点
- 编译类型看左边,运行类型看右边
- 可以调用父类中的所有成员,但是要遵守访问权限
- 不能调用子类的特有成员
- 最终的运行效果要看运行类型(子类)的具体实现,即调用方法时,要按照从子类(运行类型)开始查找
Animal animal = new Dog();
父类引用指向子类的对象,这样做没有问题
向下转型
- 只能强转父类的引用,不能强转父类的对象
- 父类的引用必须指向的时当前目标类型的对象
- 当向下转型后,可以调用子类类型中的所有成员
Animal animal = new Dog();
Dog dog = (Dog)animal;//强制类型转换
集合
相比于数组:
- 定义时无需定义长度;
- 可以动态扩展容量;
- 存放不同类型的数据
List
ArrayList类
List<String> patterns = new ArrayList<>();
list.add("北京");
Iterator接口
三种方法
hasNext()、next()、remove()
List<String> list = new ArrayList<>();
// 添加元素到集合中
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
// 处理元素
iterator.remove();
}
Set
HashSet类
public static void main(String[] args) {
HashSet<String> hs=new HashSet<String>();
hs.add("苹果");
hs.add("苹果");
hs.add("香蕉");
hs.add("葡萄");
hs.add("芒果");
Iterator<String> iterator=hs.iterator();
while(iterator.hasNext( )){
System.out.println(iterator.next());
}
}
Collections类
包含针对集合操作的静态方法
addAll(Collection<? super T> c, T... elements): 将指定元素添加到指定集合中。
sort(List<T> list): 根据元素的自然顺序对指定列表按升序进行排序。
sort(List<T> list, Comparator<? super T> c): 根据指定比较器产生的顺序对指定列表进行排序。
max(Collection<? extends T> coll):根据元素的自然顺序,返回给定集合的最大元素。
min(Collection<? extends T> coll): 根据元素的自然顺序返回给定集合的最小元素。
disjoint(Collection<?> c1, Collection<?> c2): 如果两个指定集合中没有相同的元素,则返回 true,否则返回false
frequency(Collection<?> c, Object o):返回指定集合中等于指定对象的元素数。
举个例子
import java.util.*;
public class CollectionsTest {
public static void main(String[ ] args) {
List<String> mylist = new ArrayList<String>( );
for (char i = 'a'; i < 'g'; i++) {
mylist.add(String.valueOf(i));
}
Collections.addAll(mylist, "S", "12");
Collections.sort(mylist);
System.out.println(mylist);
Collections.sort(mylist, new Comparator1( ));
System.out.println(mylist);
}
}
Map
HashMap类
常用方法
public void clear(): 清空整个数据集合;
public V get(K key):根据关键字得到对应值;
public V put(K key,V value):加入新的“关键字-值”;
public V remove(Object key):删除Map中关键字所对应的映射关系;
public boolean equals(Object obj): 判断Map对象与参数对象是否等价,两个Map相等,当且仅当其entrySet()得到的集合是一致的。
public boolean containsKey(Object key):判断在Map中是否存在与关键字匹配的映射关系。
public boolean containsValues(Object value):判断在Map中是否存在与键值匹配的映射关系。
举个例子
public class Demo {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>( );
map.put("鲁B11111", "奔驰");
map.put("鲁B22222", "宝马");
map.put("鲁B33333", "法拉利");
map.put("鲁B44444", "福特");
map.put("鲁B55555", "法拉利");
System.out.println(map.get("鲁B55555"));
}
}
枚举Enum
比如说季节,只有春夏秋冬四个固定的季节,不能添加修改,要体现季节是固定的四个对象的话就要用到枚举
枚举是一种特殊的类,里面只包含一组有限的特定的对象
自定义枚举类
public class Season {
private String name;
private String description;
//1.可以get,不要set
public String getName() {
return name;
}
public String getDescription() {
return description;
}
//2.构造器私有化
private Season(String name, String description) {
this.name = name;
this.description = description;
}
//3.内部创建一组对象,对外暴露对象
public final static Season SPRING = new Season("春天","温暖");
public final static Season SUMMWE = new Season("夏天","炎热");
public final static Season AUTUMN = new Season("秋天","凉爽");
public final static Season WINTER = new Season("冬天","寒冷");
}
使用enum关键字
public enum SeasonEnum {
/**
* 1.使用关键字 enum 替代 class
* 2.使用对象名(”“)来替代之前public static final Season
* 3.常量对象写在最前面
* 4.多个常量用逗号间隔
*/
SPRING("春天","温暖"),SUMMER("夏天","炎热");
private String name;
private String description;
//1.可以get
public String getName() {
return name;
}
public String getDescription() {
return description;
}
//2.构造器私有化
private SeasonEnum(String name, String description) {
this.name = name;
this.description = description;
}
}
枚举类的方法
- ordinal()方法:该方法获取的是枚举变量在枚举类中声明的顺序,下标从0开始,如日期中的MONDAY在第一个位置,那么MONDAY的ordinal值就是0,如果MONDAY的声明位置发生变化,那么ordinal方法获取到的值也随之变化,注意在大多数情况下我们都不应该首先使用该方法,毕竟它总是变幻莫测的。
- compareTo(E o)方法:则是比较枚举的大小,注意其内部实现是根据每个枚举的ordinal值大小进行比较的。
- name()方法与toString():几乎是等同的,都是输出变量的字符串形式。
- getDeclaringClass(): 返回该枚举变量所在的枚举类。
注解
注解可以被编译或运行,在JavaSE中,注解的使用目的比较简单,在JavaEE中注解占据了更重要的角色,可以用来配置应用程序。代替JavaEE旧版中遗留的冗余代码和XML配置
javaEE和javaSE的区别:
java SE:Standard Edition主要做桌面Java的应用开发
Java EE:Enterprise Edition主要做企业级应用、解决方案的开发
还有一个
Java ME:Micro Edition主要面向嵌入式等设备的应用开发
三个基本的注解
@Override 重写 进行校验,如果写了这个注解,编译器就回去检查该方法是否是重写,如果没有构成重写,则编译不通过
@Deprecated 表示已过时,不推荐使用,但是可以使用
@Suppress Warnings 抑制编译器警告
代码块
-
static代码块是类加载时执行,只会执行一次
-
普通代码块时在创建对象时调用的,创建一次,调用一次
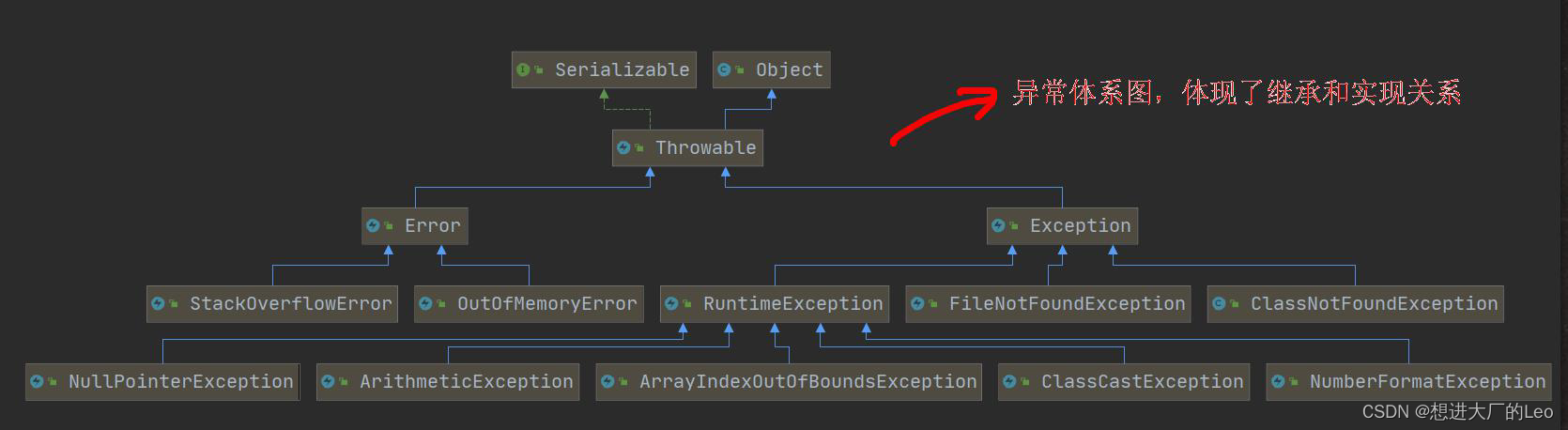
异常
分为两大类
-
Error
Java虚拟机无法解决的严重错误,如JVM系统内部错误,资源耗尽,栈溢出
-
Exception
因编程错误或者偶然的外在因素导致的一般性问题,可以使用代码处理,比如空指针访问们试图读取不存在的文件,网络连接中断
异常体系图
try catch机制
try{
一旦遇到异常,剩下的代码不运行,运行catch
}catch(Exception e){
当异常发生时,系统将异常封装成Exception对象e,传递给catch
之后程序员可以自己处理
}
也可以单独捕获某种异常,要求子类异常写在前面
try {
String str = "123";
int a = Integer.parseInt(str);
System.out.println(a);
User user = new User();
user=null;
System.out.println(user.getUsername());
} catch (NumberFormatException e) {
;
} catch (NullPointerException){
;
}
throws机制
向上一级方法抛出去
上一级也可以继续抛出,也可以try catch来处理,也就是try catch和throws二选一,默认throws
注意
子类抛出的异常不能是父类抛出异常的父类
不必既try catch 又throws
编译异常与运行异常
- 对于编译异常,程序中必须进行处理
- 对于运行时异常,可以不显式进行处理,默认是throws
自定义异常
一般情况下,自定义异常是继承RuntimeException,即运行时异常,好处是可以使用默认的处理机制
class AgeException extends RuntimeException{
public AgeException(String message){
super(message);
}
}
throw VS throws
| 意义 | 位置 | 后面跟的东西 | |
|---|---|---|---|
| throws | 异常处理的一种方式 | 方法声明处 | 异常类型 |
| throw | 手动生成异常对象的关键字 | 方法体中 | 异常对象 |
常用类
包装类Wrapper
针对八种基本定义的数据类型相应的引用类型
| 基本数据类型 | 包装类 |
|---|---|
| boolean | Boolean |
| char | Character |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
出了Boolean和Character以外,其余的包装类的父类都是Number
Integer
自动装箱和自动拆箱(JDK5之后)
int a = 100;
Integer integer = a;//自动装箱
int a2 = integer;//自动拆箱
面试
下列输出什么
Object ob1 = true?new Interger(1):new Double(2.0);
输出的是1.0,因为三元运算符是一个整体,会提升精度
包装类转成String
Integer i = 100;
//方式1
String str1 = i + "";
//方式2
String str2 = i.toString();
//方式3
String str3 = String.valueOf(i);
String转包装类
String str4 = "12345";
Integer i2 = Integer.parseInt(str4);
Integer i3 = new Integer(str4);
Intager和Character类的常用方法
System.out.println(Integer.MIN_VALUE); //返回最小值
System.out.println(Integer.MAX_VALUE);//返回最大值
System.out.println(Character.isDigit('a'));//判断是不是数字
System.out.println(Character.isLetter('a'));//判断是不是字母
System.out.println(Character.isUpperCase('a'));//判断是不是大写
System.out.println(Character.isLowerCase('a'));//判断是不是小写
System.out.println(Character.isWhitespace('a'));//判断是不是空格
System.out.println(Character.toUpperCase('a'));//转成大写
System.out.println(Character.toLowerCase('A'));//转成小写
面试
Integer i = new Integer(1);
Integer j = new Integer(1);
System.out.println(i ==j); //False,因为是两个对象
Integer m = 1; //底层Integer.valueOf(1); -> 阅读源码
Integer n = 1;//底层Integer.valueOf(1);
System.out.println(m ==n); //T
//true,这里主要是看范围-128 ~ 127 就是直接返回
/*
//1. 如果i 在IntegerCache.low(-128)~IntegerCache.high(127),就直接从数组返回
//2. 如果不在-128~127,就直接new Integer(i)
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
*/
//,否则,就new Integer(xx);
Integer x = 128;//底层Integer.valueOf(1);
Integer y = 128;//底层Integer.valueOf(1);
System.out.println(x ==y);//False
String类
-
字符串的字符采用Unicode编码,一个字符占两个字节
-
所实现的接口
-
Serialization 可以串行化,可以网络传输
-
Comparable 可以相互比较
-
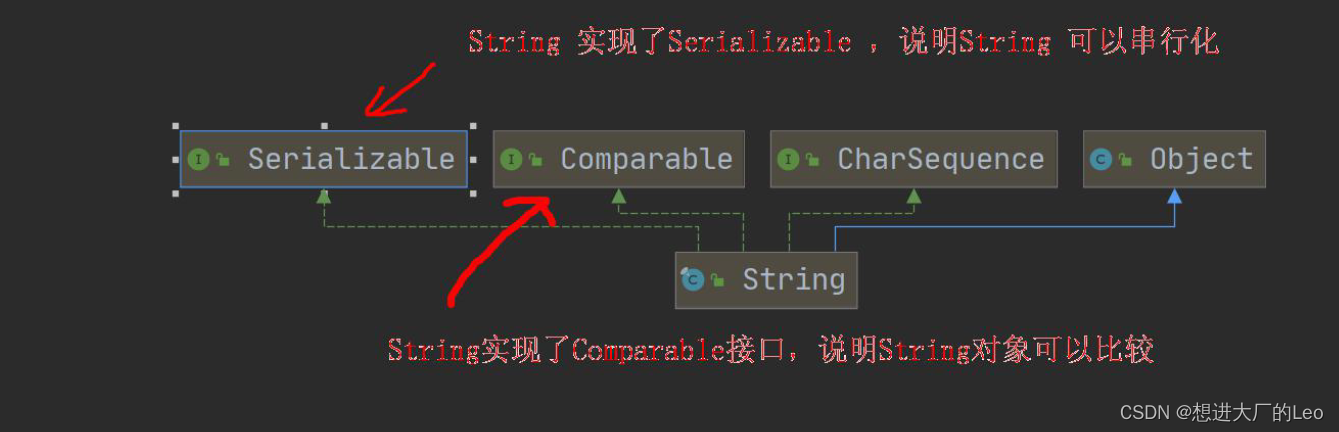
- 有很多构造器,常见的构造器
String s1 = new String();
String s2 = new String(String original);
String s3 = new String(char[] a);
String s4 = new String(char[] a,int startIndex,int count)
String s5 = new String(byte[] b)
-
是final类,不能被其他的类继承
-
有属性private final char value[],用于存放字符串内容,是fianl类型
-
String a = “hsp”;中a是指向常量池"hasp"
String b = new String(“hsp”); b指向堆中对象,再指向向量池
-
常见方法:
equals:区分大小写,判断内容是否相等 equalslgnoreCase:忽略大小写,判断是否相等 length:获取字符个数,字符串长度 indexOf:获取子串在字符串中第一次出现的索引,找不到返回-1 lastIndexOf:获取子串最后一次在字符串出现的索引,找不到返回-1 substring:截取指定范围的子串,(0,5)是截取从0开始,0到4,5不截取 trim:去前后空格 charAt:获取某索引处的字符 format:格式化输出 String formatStr = "我的姓名是%s 年龄是%d,成绩是%.2f 性别是%c.希望大家喜欢我!"; String info2 = String.format(formatStr, name, age, score, gender);
StringBuffer类
直接父类是AbstractStringBuilder
实现了Serializable接口,可以串行化
与String相比,value不是final类,但是StringBuffer还是final类,不能被继承
-
String vs StringBuffer
String保存的是字符串常量,里面的值不能更改,每次String类的更新实际上就是更改地址,效率较低
StringBuffer保存的是字符串变量,里面的值可以更改,不需要更新地址,效率较高,放在堆里
-
构造器
//1. 创建一个 大小为 16的 char[] ,用于存放字符内容 StringBuffer stringBuffer = new StringBuffer(); //2 通过构造器指定 char[] 大小 StringBuffer stringBuffer1 = new StringBuffer(100); //3. 通过 给一个String 创建 StringBuffer, char[] 大小就是 str.length() + 16 StringBuffer hello = new StringBuffer("hello"); -
String 和 StringBuffer转换
//看 String——>StringBuffer String str = "hello tom"; //方式1 使用构造器 //注意: 返回的才是StringBuffer对象,对str 本身没有影响 StringBuffer stringBuffer = new StringBuffer(str); //方式2 使用的是append方法 StringBuffer stringBuffer1 = new StringBuffer(); stringBuffer1 = stringBuffer1.append(str); //看看 StringBuffer ->String StringBuffer stringBuffer3 = new StringBuffer("韩顺平教育"); //方式1 使用StringBuffer提供的 toString方法 String s = stringBuffer3.toString(); //方式2: 使用构造器来搞定 String s1 = new String(stringBuffer3); -
常用方法
public class StringBufferMethod { public static void main(String[] args) { StringBuffer s = new StringBuffer("hello"); //增 s.append(',');// "hello," s.append("张三丰");//"hello,张三丰" s.append("赵敏").append(100).append(true).append(10.5);//"hello,张三丰赵敏100true10.5" System.out.println(s);//"hello,张三丰赵敏100true10.5" //删 /* * 删除索引为>=start && <end 处的字符 * 解读: 删除 11~14的字符 [11, 14) */ s.delete(11, 14); System.out.println(s);//"hello,张三丰赵敏true10.5" //改 //老韩解读,使用 周芷若 替换 索引9-11的字符 [9,11) s.replace(9, 11, "周芷若"); System.out.println(s);//"hello,张三丰周芷若true10.5" //查找指定的子串在字符串第一次出现的索引,如果找不到返回-1 int indexOf = s.indexOf("张三丰"); System.out.println(indexOf);//6 //插 //老韩解读,在索引为9的位置插入 "赵敏",原来索引为9的内容自动后移 s.insert(9, "赵敏"); System.out.println(s);//"hello,张三丰赵敏周芷若true10.5" //长度 System.out.println(s.length());//22 System.out.println(s); } }
StringBuilder类
此类提供一个与StringBuffer兼容的API,但不保证同步(StringBuilder不是线程安全),被设计用作StringBuffer的一个简易替换,用在字符串缓冲区中被单个线程使用的时候。比StringBuffer要快,建议优先使用
String vs StringBuffer vs StringBuilder
String:不可变字符序列,效率低,但是复用率高
StringBuffer:可变字符序列,效率较高,线程安全
StringBuilder:可变字符序列,效率最高,线程不安全
Math类
//看看Math常用的方法(静态方法)
//1.abs 绝对值
int abs = Math.abs(-9);
System.out.println(abs);//9
//2.pow 求幂
double pow = Math.pow(2, 4);//2的4次方
System.out.println(pow);//16
//3.ceil 向上取整,返回>=该参数的最小整数(转成double);
double ceil = Math.ceil(3.9);
System.out.println(ceil);//4.0
//4.floor 向下取整,返回<=该参数的最大整数(转成double)
double floor = Math.floor(4.001);
System.out.println(floor);//4.0
//5.round 四舍五入 Math.floor(该参数+0.5)
long round = Math.round(5.51);
System.out.println(round);//6
//6.sqrt 求开方
double sqrt = Math.sqrt(9.0);
System.out.println(sqrt);//3.0
//7.random 求随机数
// random 返回的是 0 <= x < 1 之间的一个随机小数
// 思考:请写出获取 a-b之间的一个随机整数,a,b均为整数 ,比如 a = 2, b=7
// 即返回一个数 x 2 <= x <= 7
// 老韩解读 Math.random() * (b-a) 返回的就是 0 <= 数 <= b-a
// (1) (int)(a) <= x <= (int)(a + Math.random() * (b-a +1) )
// (2) 使用具体的数给小伙伴介绍 a = 2 b = 7
// (int)(a + Math.random() * (b-a +1) ) = (int)( 2 + Math.random()*6)
// Math.random()*6 返回的是 0 <= x < 6 小数
// 2 + Math.random()*6 返回的就是 2<= x < 8 小数
// (int)(2 + Math.random()*6) = 2 <= x <= 7
// (3) 公式就是 (int)(a + Math.random() * (b-a +1) )
for(int i = 0; i < 100; i++) {
System.out.println((int)(2 + Math.random() * (7 - 2 + 1)));
}
//max , min 返回最大值和最小值
int min = Math.min(1, 9);
int max = Math.max(45, 90);
System.out.println("min=" + min);
System.out.println("max=" + max);
Arrays、System、大数
Date类 第一代日期类
-
Date:精确到毫秒,代表特定的瞬间
-
SimpleDateFormat:格式化和解析日期的具体类,可以日期变文本,也可以文本变日期
//老韩解读 //1. 获取当前系统时间 //2. 这里的Date 类是在java.util包 //3. 默认输出的日期格式是国外的方式, 因此通常需要对格式进行转换 Date d1 = new Date(); //获取当前系统时间 System.out.println("当前日期=" + d1); Date d2 = new Date(9234567); //通过指定毫秒数得到时间 System.out.println("d2=" + d2); //获取某个时间对应的毫秒数 // //老韩解读 //1. 创建 SimpleDateFormat对象,可以指定相应的格式 //2. 这里的格式使用的字母是规定好,不能乱写 SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 hh:mm:ss E"); String format = sdf.format(d1); // format:将日期转换成指定格式的字符串 System.out.println("当前日期=" + format); //老韩解读 //1. 可以把一个格式化的String 转成对应的 Date //2. 得到Date 仍然在输出时,还是按照国外的形式,如果希望指定格式输出,需要转换 //3. 在把String -> Date , 使用的 sdf 格式需要和你给的String的格式一样,否则会抛出转换异常 String s = "1996年01月01日 10:20:30 星期一"; Date parse = sdf.parse(s); System.out.println("parse=" + sdf.format(parse));
Calendar类 第二代日期类
Canlendar是一个抽象类,构造器是private,new不出来
可以通过getInstance()来获取实例
Calendar没有提供对应的格式化的类,因此需要程序员自己组合来输出(灵活)
如果我们需要按照 24小时进制来获取时间, Calendar.HOUR ==改成=> Calendar.HOUR_OF_DAY
Calendar c = Calendar.getInstance(); //创建日历类对象//比较简单,自由
System.out.println("c=" + c);
//2.获取日历对象的某个日历字段
System.out.println("年:" + c.get(Calendar.YEAR));
// 这里为什么要 + 1, 因为Calendar 返回月时候,是按照 0 开始编号
System.out.println("月:" + (c.get(Calendar.MONTH) + 1));
System.out.println("日:" + c.get(Calendar.DAY_OF_MONTH));
System.out.println("小时:" + c.get(Calendar.HOUR));
System.out.println("分钟:" + c.get(Calendar.MINUTE));
System.out.println("秒:" + c.get(Calendar.SECOND));
//Calender 没有专门的格式化方法,所以需要程序员自己来组合显示
System.out.println(c.get(Calendar.YEAR) + "-" + (c.get(Calendar.MONTH) + 1) + "-" + c.get(Calendar.DAY_OF_MONTH) +
" " + c.get(Calendar.HOUR_OF_DAY) + ":" + c.get(Calendar.MINUTE) + ":" + c.get(Calendar.SECOND) );
第三代日期类
LocalDate日期(年月日) \ LocalTime时间(时分秒) \ LocalDateTime日期时间(年月日时分秒)
public static void main(String[] args) {
//第三代日期
//老韩解读
//1. 使用now() 返回表示当前日期时间的 对象
LocalDateTime ldt = LocalDateTime.now(); //LocalDate.now();//LocalTime.now()
System.out.println(ldt);
//2. 使用DateTimeFormatter 对象来进行格式化
// 创建 DateTimeFormatter对象
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
String format = dateTimeFormatter.format(ldt);
System.out.println("格式化的日期=" + format);
System.out.println("年=" + ldt.getYear());
System.out.println("月=" + ldt.getMonth());
System.out.println("月=" + ldt.getMonthValue());
System.out.println("日=" + ldt.getDayOfMonth());
System.out.println("时=" + ldt.getHour());
System.out.println("分=" + ldt.getMinute());
System.out.println("秒=" + ldt.getSecond());
LocalDate now = LocalDate.now(); //可以获取年月日
LocalTime now2 = LocalTime.now();//获取到时分秒
//提供 plus 和 minus方法可以对当前时间进行加或者减
//看看890天后,是什么时候 把 年月日-时分秒
LocalDateTime localDateTime = ldt.plusDays(890);
System.out.println("890天后=" + dateTimeFormatter.format(localDateTime));
//看看在 3456分钟前是什么时候,把 年月日-时分秒输出
LocalDateTime localDateTime2 = ldt.minusMinutes(3456);
System.out.println("3456分钟前 日期=" + dateTimeFormatter.format(localDateTime2));
集合类
体系框架
集合主要是两组(单列集合 , 双列集合)
Collection 接口有两个重要的子接口 List Set , 他们的实现子类都是单列集合
Map 接口的实现子类 是双列集合,存放的 K-V
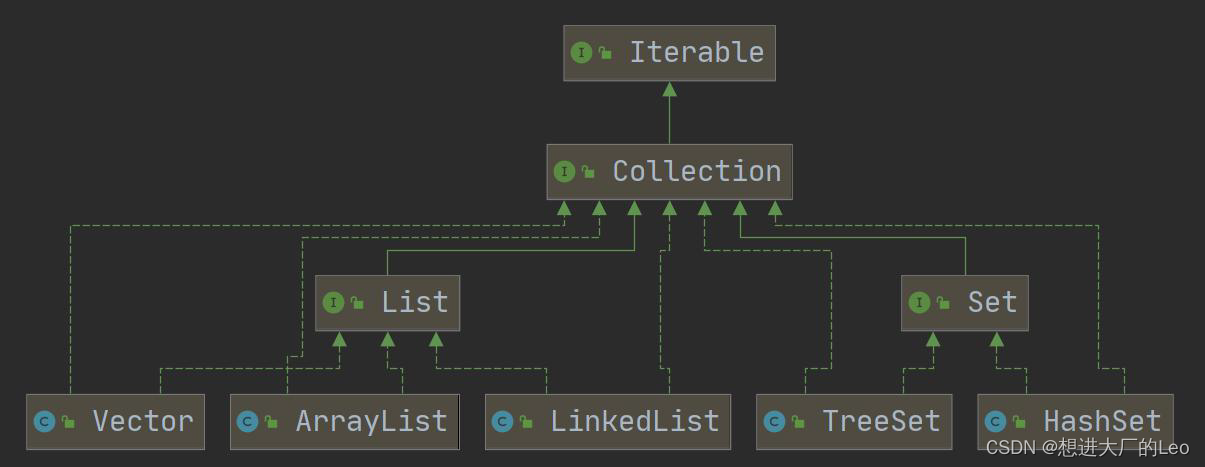
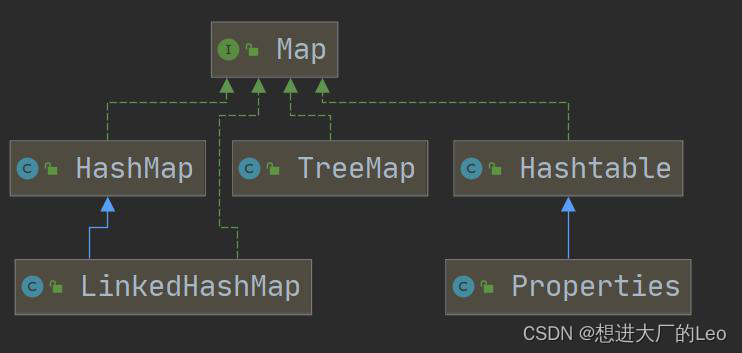
Colllection接口和常用方法
以实现子类ArrayList来掩饰
public class CollectionMethod {
@SuppressWarnings({"all"})
public static void main(String[] args) {
List list = new ArrayList();
// add:添加单个元素
list.add("jack");
list.add(10);//list.add(new Integer(10))自动装箱
list.add(true);
System.out.println("list=" + list);
// remove:删除指定元素
//list.remove(0);//删除第一个元素
list.remove(true);//指定删除某个元素
System.out.println("list=" + list);
// contains:查找元素是否存在
System.out.println(list.contains("jack"));//T
// size:获取元素个数
System.out.println(list.size());//2
// isEmpty:判断是否为空
System.out.println(list.isEmpty());//F
// clear:清空
list.clear();
System.out.println("list=" + list);
// addAll:添加多个元素
ArrayList list2 = new ArrayList();
list2.add("红楼梦");
list2.add("三国演义");
list.addAll(list2);
System.out.println("list=" + list);
// containsAll:查找多个元素是否都存在
System.out.println(list.containsAll(list2));//T
// removeAll:删除多个元素
list.add("聊斋");
list.removeAll(list2);
System.out.println("list=" + list);//[聊斋]
}
}
Iterator迭代器
用于遍历Collection集合中的元素
实现Collection接口的集合类都有iterator方法,可以返回一个实现了Iterator接口的对象,即返回一个迭代器
hasNext() 判断是否还有下一个元素
next() 1.下移 2.将下移以后集合位置上的元素返回
remove() 用的比较少
增强for循环
for(元素:集合或者数组){
}
List接口
List集合类中元素有序,且可重复
public static void main(String[] args) {
List list = new ArrayList();
list.add("张三丰");
list.add("贾宝玉");
list.add(1, "韩顺平");
System.out.println("list=" + list);
List list2 = new ArrayList();
list2.add("jack");
list2.add("tom");
list.addAll(1, list2);
System.out.println("list=" + list);
System.out.println(list.indexOf("tom"));
//只看tom第一次出现的位置
list.add("韩顺平");
System.out.println("list=" + list);
System.out.println(list.lastIndexOf("韩顺平"));
//最后一次出现的位置
list.remove(0);
//移除
System.out.println("list=" + list);
list.set(1, "玛丽");
System.out.println("list=" + list);
List returnlist = list.subList(0, 2);
System.out.println("returnlist=" + returnlist);
}
List的遍历方法
public static void main(String[] args) {
List list = new LinkedList();
list.add("jack");
list.add("tom");
list.add("鱼香肉丝");
list.add("北京烤鸭子");
Iterator iterator = list.iterator();
while(iterator.hasNext()) {
Object obj = iterator.next();
System.out.println(obj);
}
System.out.println("=====增强for=====");
Iterator var5 = list.iterator();
while(var5.hasNext()) {
Object o = var5.next();
System.out.println("o=" + o);
}
System.out.println("=====普通for====");
for(int i = 0; i < list.size(); ++i) {
System.out.println("对象=" + list.get(i));
}
}
ArrayList
- 可以加入null
- 底层是由数组实现数据存储的
- 基本等同于Vector,线程不安全,没有synchronized
- ArrayList中维护了一个Object类型的数组elementData,初始elementData容量为0,第一次添加扩容为10,之后每次扩容elementData1.5倍。
Vector
- 底层也是elementData
- 是线程同步的,类方法带有synchronized
- 每次2倍扩容
- 但是效率没有ArrayList
LinkedList
- 底层是一个双向链表
- 维护了两个属性first和last指向首节点和尾节点
- 每个节点(Node对象),里面维护prev、next、item三个属性,通过prev指向前一个,通过next指向后一个节点,实现双向链表
- 好处是增减和删除不是通过数组完成的,效率较高
ArrayList vs LinkedList
- 如果改查操作多,选择ArrayList
- 如果增删操作多,选择LinkedList
- 在项目中80%-90%都是查询,大部分情况下选择ArrayList
Set接口
-
无序,添加和取出的顺序不一致,没有索引
-
不允许有重复元素,所以最多包含一个null
public static void main(String[] args) { //老韩解读 //1. 以Set 接口的实现类 HashSet 来讲解Set 接口的方法 //2. set 接口的实现类的对象(Set接口对象), 不能存放重复的元素, 可以添加一个null //3. set 接口对象存放数据是无序(即添加的顺序和取出的顺序不一致) //4. 注意:取出的顺序的顺序虽然不是添加的顺序,但是他的固定. Set set = new HashSet(); set.add("john"); set.add("lucy"); set.add("john");//重复 set.add("jack"); set.add("hsp"); set.add("mary"); set.add(null);// set.add(null);//再次添加null for(int i = 0; i <10;i ++) { System.out.println("set=" + set); } //遍历 //方式1: 使用迭代器 System.out.println("=====使用迭代器===="); Iterator iterator = set.iterator(); while (iterator.hasNext()) { Object obj = iterator.next(); System.out.println("obj=" + obj); } set.remove(null); //方式2: 增强for System.out.println("=====增强for===="); for (Object o : set) { System.out.println("o=" + o); } //set 接口对象,不能通过索引来获取 }
HashSet
实质上是HashMap,而HashMap的底层是数组+链表+红黑树
对象能不能重复添加要看equals和hashcode
LinkedHashSet
底层是LinkedHashMap,底层是数组+双向链表
Map接口
- Map与Collection并列存在。用于保存具有映射关系的数据:Key-Value(双列元素)
- Map 中的 key 和 value 可以是任何引用类型的数据,会封装到HashMap$Node 对象中
- Map 中的 key 不允许重复,原因和HashSet 一样,前面分析过源码.
- Map 中的 value 可以重复
- Map 的key 可以为 null, value 也可以为null ,注意 key 为null只能有一个,value 为null ,可以多个
- 常用String类作为Map的 key
Map map = new HashMap();
map.put("no1", "韩顺平");//k-v
map.put("no2", "张无忌");//k-v
map.put("no1", "张三丰");//当有相同的k , 就等价于替换.
map.put("no3", "张三丰");//k-v
map.put(null, null); //k-v
map.put(null, "abc"); //等价替换
map.put("no4", null); //k-v
map.put("no5", null); //k-v
map.put(1, "赵敏");//k-v
map.put(new Object(), "金毛狮王");//k-v
// 通过get 方法,传入 key ,会返回对应的value
System.out.println(map.get("no2"));//张无忌
System.out.println("map=" + map);
常用方法
Map map = new HashMap();
map.put("邓超", new Book("", 100));//OK
map.put("邓超", "孙俪");//替换-> 一会分析源码
map.put("王宝强", "马蓉");//OK
map.put("宋喆", "马蓉");//OK
map.put("刘令博", null);//OK
map.put(null, "刘亦菲");//OK
map.put("鹿晗", "关晓彤");//OK
map.put("hsp", "hsp的老婆");
System.out.println("map=" + map);
// remove:根据键删除映射关系
map.remove(null);
System.out.println("map=" + map);
// get:根据键获取值
Object val = map.get("鹿晗");
System.out.println("val=" + val);
// size:获取元素个数
System.out.println("k-v=" + map.size());
// isEmpty:判断个数是否为0
System.out.println(map.isEmpty());//F
// clear:清除k-v
//map.clear();
System.out.println("map=" + map);
// containsKey:查找键是否存在
System.out.println("结果=" + map.containsKey("hsp"));//T
遍历
Map map = new HashMap();
map.put("邓超", "孙俪");
map.put("王宝强", "马蓉");
map.put("宋喆", "马蓉");
map.put("刘令博", null);
map.put(null, "刘亦菲");
map.put("鹿晗", "关晓彤");
//第一组: 先取出 所有的Key , 通过Key 取出对应的Value
Set keyset = map.keySet();
//(1) 增强for
System.out.println("-----第一种方式-------");
for (Object key : keyset) {
System.out.println(key + "-" + map.get(key));
}
//(2) 迭代器
System.out.println("----第二种方式--------");
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
//第二组: 把所有的values取出
Collection values = map.values();
//这里可以使用所有的Collections使用的遍历方法
//(1) 增强for
System.out.println("---取出所有的value 增强for----");
for (Object value : values) {
System.out.println(value);
}
//(2) 迭代器
System.out.println("---取出所有的value 迭代器----");
Iterator iterator2 = values.iterator();
while (iterator2.hasNext()) {
Object value = iterator2.next();
System.out.println(value);
}
//第三组: 通过EntrySet 来获取 k-v
Set entrySet = map.entrySet();// EntrySet<Map.Entry<K,V>>
//(1) 增强for
System.out.println("----使用EntrySet 的 for增强(第3种)----");
for (Object entry : entrySet) {
//将entry 转成 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
//(2) 迭代器
System.out.println("----使用EntrySet 的 迭代器(第4种)----");
Iterator iterator3 = entrySet.iterator();
while (iterator3.hasNext()) {
Object entry = iterator3.next();
//System.out.println(next.getClass());//HashMap$Node -实现-> Map.Entry (getKey,getValue)
//向下转型 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
泛型
使用泛型的好处
- 不能对加入到集合的中的数据类型进行约束,所以是不安全的
- 遍历的时候需要进行类型转换,影响效率
//使用传统的方法来解决
ArrayList arrayList = new ArrayList();
arrayList.add(new Dog("旺财", 10));
arrayList.add(new Dog("发财", 1));
arrayList.add(new Dog("小黄", 5));
//假如我们的程序员,不小心,添加了一只猫
arrayList.add(new Cat("招财猫", 8));
//遍历
for (Object o : arrayList) {
//向下转型Object ->Dog
Dog dog = (Dog) o;
System.out.println(dog.getName() + "-" + dog.getAge());
}
//使用泛型的方法来解决
ArrayList<Dog> arrayList = new ArrayList<Dog>();
arrayList.add(new Dog("旺财", 10));
arrayList.add(new Dog("发财", 1));
arrayList.add(new Dog("小黄", 5));
//假如我们的程序员,不小心,添加了一只猫,加不了
arrayList.add(new Cat("招财猫", 8));
//遍历
for (Dog dog : arrayList) {
//不需要向下转型
System.out.println(dog.getName() + "-" + dog.getAge());
}
//注意,特别强调: E具体的数据类型在定义Person对象的时候指定,即在编译期间,就确定E是什么类型
Person<String> person = new Person<String>("韩顺平教育");
person.show(); //String
/*
你可以这样理解,上面的Person类
class Person {
String s ;//E表示 s的数据类型, 该数据类型在定义Person对象的时候指定,即在编译期间,就确定E是什么类型
public Person(String s) {//E也可以是参数类型
this.s = s;
}
public String f() {//返回类型使用E
return s;
}
}
*/
Person<Integer> person2 = new Person<Integer>(100);
person2.show();//Integer
/*
class Person {
Integer s ;//E表示 s的数据类型, 该数据类型在定义Person对象的时候指定,即在编译期间,就确定E是什么类型
public Person(Integer s) {//E也可以是参数类型
this.s = s;
}
public Integer f() {//返回类型使用E
return s;
}
}
*/
}
}
//泛型的作用是:可以在类声明时通过一个标识表示类中某个属性的类型,
// 或者是某个方法的返回值的类型,或者是参数类型
class Person<E> {
E s ;//E表示 s的数据类型, 该数据类型在定义Person对象的时候指定,即在编译期间,就确定E是什么类型
public Person(E s) {//E也可以是参数类型
this.s = s;
}
public E f() {//返回类型使用E
return s;
}
public void show() {
System.out.println(s.getClass());//显示s的运行类型
}
}
注意事项
-
给泛型指向数据类型时,要求是引用类型,不能是基本数据类型
-
在给泛型指定具体类型后,可以传入该类型或者其子类类型
-
可以简写比如
ArrayList<Integer> list = new ArrayList<>(); -
如果不写泛型,默认是Object
自定义泛型
-
普通成员可以使用泛型
-
使用泛型的数组不能初始化
因为不知道要开多大的空间,所以不能实例化
T[] ts = new T[8];这样是不行的 -
静态方法中不能使用泛型
因为静态是和类相关的,在类加载时,对象还没有创建
-
泛型类的类型,是在创建对象时确认的
-
泛型接口的类型,在继承接口或者实现接口的时候确定
-
泛型方法可以定义在普通类中,也可以定义在泛型类中
-
泛型方法被调用的时候确认类型
-
像public void eat(E e){}这样的,不是泛型方法,而是使用了泛型















 523
523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









