







特殊语句
- 创建约束
- 删除约束


general
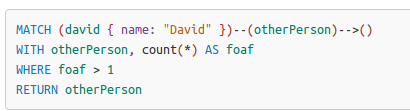
- return
- as改变列名
- RETURN DISTINCT b(返回不重复)
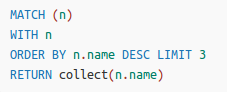
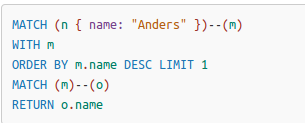
- order by
- 默认升序(desc 逆序)
- 升序排序中null在最后,逆序null在最前
- limit
LIMIT toInt(3 * rand())+ 1//也可以是表达式
- skip
- with
-
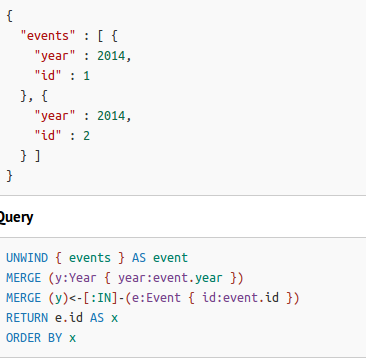
- unwind(展开)
UNWIND[1,2,3] AS x
RETURN xWITH [1,1,2,2] AS coll UNWIND coll AS x
WITH DISTINCT x
RETURN collect(x) AS SET-
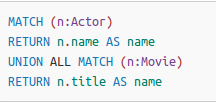
- union
- union all 对结果进行并运算
- union对结果去重
- union all 对结果进行并运算
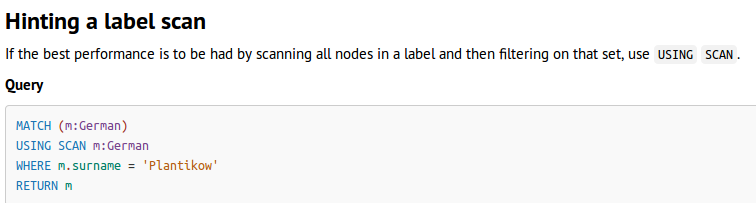
- using
- 强制制定开始点
USING INDEX -
- 强制制定开始点








reading
- match
--查询所有相关节点(跳过关系),忽略类型和方向- 关系中存在空格等特殊字符,则用
` (backtick)引用 - 变长路径用属性match
id(r)=0//取id(节点或者是关系),比较的等号是单等号- 单条最短路径
所有最短路径(等长)
- where
- 属性存在
注:The HAS() function has been superseded by EXISTS() and will be removed in a future release. - 字符串匹配
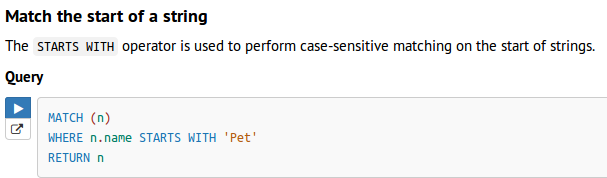
- start with
- end with
- contains
- start with
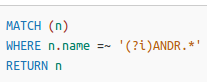
- 正则表达式
- 设置大小写不敏感,通过(?i)
- 设置大小写不敏感,通过(?i)
- is null (is not null)
- 属性存在
- start
注:需要保证存在一个索引 - aggregation
- count(*|ider)
- sum(ider)
- avg(ider)
- percentileDisc(x,x)(实例求中位数)
- percentileCont(x,x)(线性插值)
- stdev(x)(标准差n-1作为标准)
- sedevp(x)(标准差n作为标准)
- max(x) , min(x)
- collect(x) 形成一个list
- LOAD CSV
- csv格式
- 导入
- 导入数据包含头(with headers)
- 导入,如果分解符不是默认的逗号(fieldterminator)
- 如果导入大量数据(commit 后边可以加数字,表示每次commit的数量)
- csv格式
















writing
- create
- 创建节点和关系
create (n1{num:1}),(n2{num:2}),...//这里n是变量名
create (n1)-[:rel]->(n2) //rel表示某种关系 - 删除节点和关系
delete n//如果是删除节点,只删除节点,不删除关系,因此要保证关系已经被删除再删除节点 - 显示所有节点和关系
start n=node(*),r=relationship(*)
return n,r - 创建一条路径
- 使用参数创建(可一次创建多个节点等)
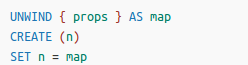
- 创建节点和关系
- merge
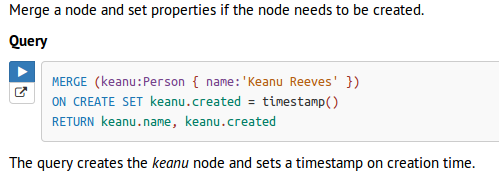
- merge … on create
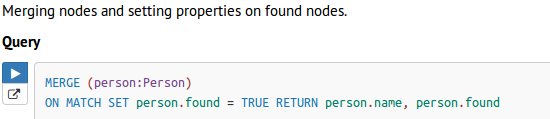
- merge … on match
- Merge with ON CREATE and ON MATCH
- merge … on create
- set
- 可以通过set pro=null删除属性
- 复制属性,但是被接受的元素原有的属性会被删除
- 添加属性使用+=
- delete
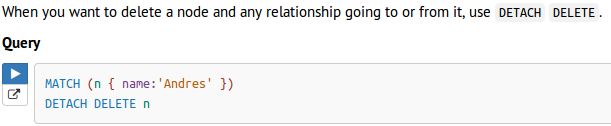
- 删除带有关系的节点
- 删除带有关系的节点
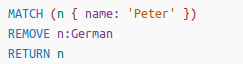
- remove
- 移除label
- 移除label
- foreach
1. 处理路径上的所有节点
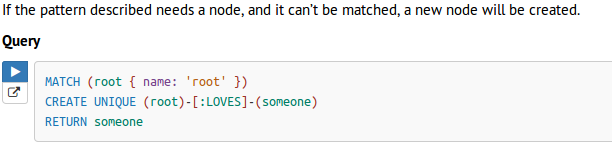
- create unique
- 如果不是完全匹配,则穿件一个新节点
- 如果不是完全匹配,则穿件一个新节点








索引
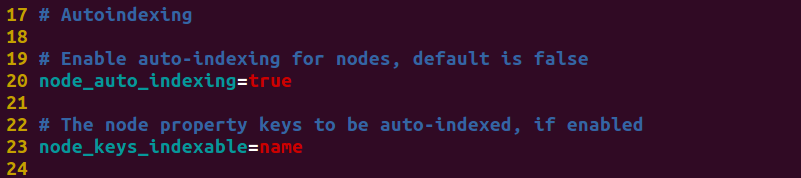
- 配置
先在neo4j.properties配置一下
- 在neo4j的console页面进行设置
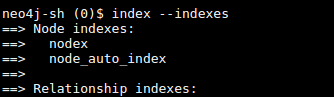
(1)index --create node_auto_index -t Node
(2)index --indexes
(3) 最终效果:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









