






在当今数据驱动的时代,掌握爬虫技术并利用数据进行预测分析是一项很实用的技能。对于新手小白来说,可能会觉得无从下手,但借助 AI 的强大能力,这个过程可以变得简单许多。本文将详细介绍如何利用 AI 完成从简单爬虫获取数据到最终实现预测的完整流程,希望能帮助大家快速入门。
一、整体流程概述
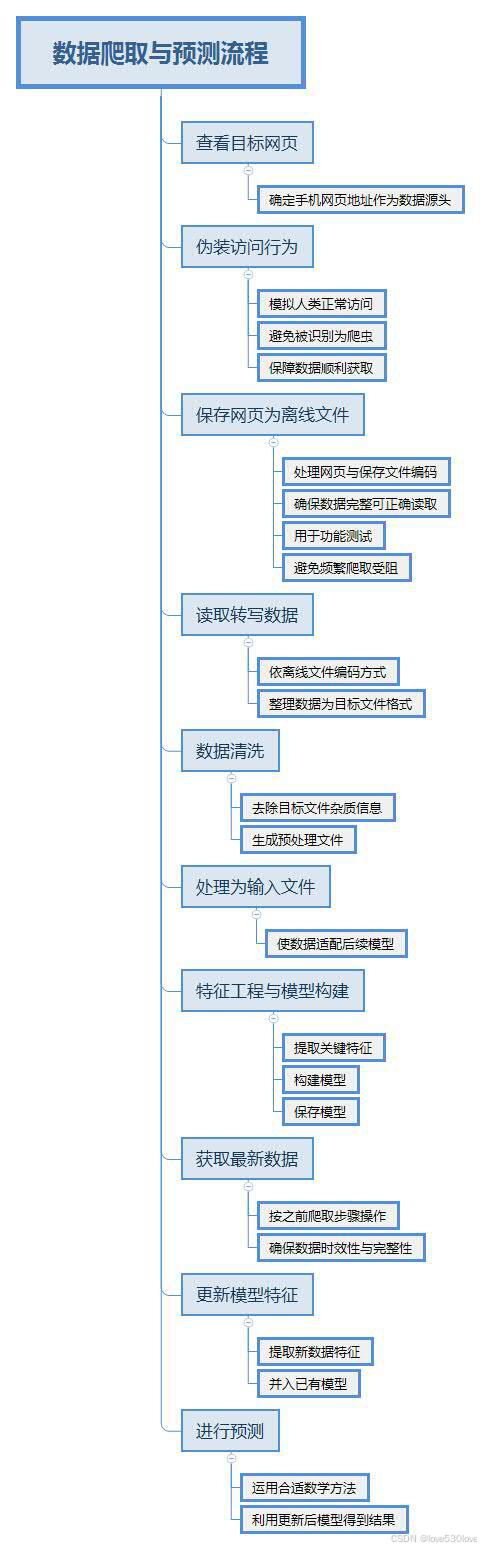
我们要实现的目标是通过爬虫获取网页上的数据,经过一系列的数据处理步骤后,构建模型进行预测分析。整个流程大致可分为以下几个关键步骤:
- 查看数据所在的手机网页,确定目标网页地址,由于手机网页地址相对较易爬取,可以优选考虑以此作为数据源头。
- 伪装、模拟人类正常访问行为,避免被服务器识别为爬虫而受阻,保障数据能顺利获取。
- 保存整个数据网页为离线文件到本地,同时注意处理网页编码和保存文件的编码,确保数据完整且可正确读取。离线网页为后续全部流程跑通也起到功能测试的作用,此步是为避免频繁使用相同IP执行爬取操作导致的被封、受阻。
- 根据离线文件的编码方式,读取并转写数据表格内容为目标文件,将网页数据整理成便于后续处理的格式。
- 对目标文件进行数据清洗,去除杂质信息,生成预处理文件,为后续分析做准备。
- 从预处理文件进一步处理为符合模型输入要求的输入文件,使其适配后续模型。
- 开展特征工程处理,提取关键特征并构建模型,随后保存该模型。
- 按照之前的爬取步骤获取最新的数据,确保数据的时效性和完整性。
- 提取最新数据的特征并入已有的模型,让模型能及时更新适应新数据。
- 运用合适的数学方法,利用更新后的模型进行预测,得到最终结果。
步骤详解:
步骤一:查看数据所在的手机网页
通常情况下,手机网页的地址相对比较容易进行数据爬取工作。我们首先需要确定包含目标数据的手机网页链接,这是整个流程的起始点,后续所有操作都将围绕从该网页获取的数据展开。
步骤二:伪装、模拟人类正常访问行为
为了避免在访问网页时被服务器识别为异常的爬虫行为,进而导致访问受限甚至被封禁,我们需要采取一些手段来伪装自己,使其看起来像是正常人类在用一些常规设备和浏览器访问网页。例如,可以通过设置合理的请求头信息,模拟不同的浏览器标识、用户代理、访问时间间隔等,让服务器认为这些请求是来自真实用户正常浏览网页所发出的,以此确保能够顺利获取网页数据。
步骤三:保存整个数据网页为离线文件到本地,并处理编码问题
在成功访问到目标手机网页后,要将整个网页内容保存为离线文件存储在本地电脑上。离线网页为后续全部流程跑通也起到功能测试的作用,此步是为避免频繁使用相同IP执行爬取操作导致的被封、受阻。使用IP代理的可以根据实际情况修改这步。这一步需要特别注意网页编码以及保存文件时所采用的编码方式,确保二者之间的兼容性,避免出现乱码等数据读取和处理方面的问题。只有正确处理好编码问题,后续才能顺利地从保存的离线文件中提取出准确的数据信息。
步骤四:依据离线文件的编码方式,读取并转写数据表格内容为目标文件
根据之前确定好的离线文件编码方式,使用相应的工具或编程语言提供的功能,读取该离线文件中的数据表格内容,并将其转写为我们所需要的目标文件格式。这个过程涉及到对网页数据结构的解析以及格式转换,目的是把杂乱的网页数据整理成便于后续处理的结构化数据形式,存储在目标文件中。
步骤五:从目标文件清洗数据到预处理文件
目标文件中的数据可能包含一些不符合我们分析要求的杂质信息,例如重复数据、缺失值、错误格式的数据等。所以需要对其进行清洗操作,通过诸如去除重复记录、填充缺失值、纠正数据格式等一系列数据清洗手段,将原始的目标文件数据转化为相对干净、规整的预处理文件,为后续更深入的数据处理奠定良好基础。
步骤六:从预处理文件进一步处理为需要的输入文件
在完成数据清洗后,预处理文件中的数据还需要根据具体的分析需求和模型要求,进行进一步的加工处理,比如数据归一化、标准化、数据类型转换等操作,使其最终成为符合模型输入要求的输入文件,确保后续模型能够准确地对这些数据进行处理和分析。
步骤七:进行特征工程处理,提取特征并保存模型
利用已经准备好的输入文件中的数据,开展特征工程相关工作。这包括运用合适的数学方法和算法,从大量的数据中挖掘并提取出对预测结果有重要影响的特征信息,然后基于这些特征构建相应的模型,最后将训练好的模型保存下来,以便后续重复使用或者进一步优化完善。
步骤八:同样的爬取步骤,获取最新的数据加入分析
为了使模型能够保持对最新情况的适应性和准确性,我们需要定期重复之前的数据爬取步骤,获取最新的数据内容。同样要注意伪装访问行为以及处理编码等问题,确保新获取的数据与之前的数据具有一致性和可比性,以便后续能够将其融入到整体的分析流程中。
步骤九:提取最新数据的特征并入已有的模型
针对新获取的最新数据,按照之前的特征工程处理方法,从中提取出相应的特征信息,然后将这些新特征合理地融入到已经保存好的现有模型当中,使得模型能够及时更新知识,适应数据的动态变化,保证预测的准确性和可靠性。
步骤十:用合适的数学方法进行预测
在完成最新数据的特征融入后,运用合适的、与模型相匹配的数学方法,利用更新后的模型对相关目标进行预测,最终得到我们期望的预测结果,为决策等相关活动提供参考依据。
通过以上这一系列严谨且有序的步骤,我们能够充分利用从手机网页爬取的数据,构建有效的分析模型,并实现对目标的准确预测。
二、借助 AI 完成各步骤的操作方法及指令示例
(一)查找目标手机网页(步骤一)
- 操作思路:向 AI 描述你想要获取的数据大致类型或者所属领域,让它帮忙推荐一些可能包含此类数据且易于爬取的手机网页地址。
- AI 指令示例:“我想获取一些关于 [具体数据类型,比如电子产品销售价格信息] 的数据用于分析和预测,希望你能推荐几个容易爬取数据的手机网页地址,最好是在该领域比较权威、数据量相对丰富的网站,谢谢。”
(二)伪装访问行为(步骤二)
- 操作思路:向 AI 咨询如何在 Python(常用的爬虫编程语言,你也可以指定其他语言)中设置请求头、调整访问频率等方式来模拟人类正常访问网页,使其给出具体的代码示例和相关解释。
- AI 指令示例:“我正在使用 Python 编写一个爬虫程序,需要伪装成正常人类访问网页(具体网址为 [目标网址]),避免被识别为爬虫,麻烦你帮我写一下如何设置请求头信息(包含常见的浏览器标识、用户代理等)以及控制合理的访问时间间隔的代码示例,并简单解释一下每部分代码的作用,非常感谢。”
(三)保存网页为离线文件及处理编码(步骤三)
- 操作思路:告知 AI 使用的编程语言以及想要保存网页的相关需求,让它提供完整的代码来实现网页保存以及编码处理的功能,确保能正确保存离线文件。
- AI 指令示例:“我用 Python 来做爬虫,现在已经成功访问到了网页(网址是 [网页地址]),我想把整个网页内容保存为本地的离线文件,同时要注意处理好网页编码和保存文件的编码,防止出现乱码情况,请你帮我写一下相应的代码,详细说明每一步在做什么,以及代码中涉及到的关键函数和参数的含义,多谢。”
(四)读取并转写数据表格内容(步骤四)
- 操作思路:向 AI 说明离线文件的格式(比如 HTML、XML 等)以及目标文件期望的格式(如 CSV、Excel 等),请求它提供将数据从离线文件中解析并转换格式的代码实现方式,同时解释关键代码逻辑。
- AI 指令示例:“我有一个保存为 HTML 格式的离线文件(是之前爬取网页保存下来的),里面包含了我需要的数据表格内容,我想把这些数据读取出来转写成 CSV 格式的目标文件,我使用 Python 的相关库来操作,希望你能帮我写一下具体的代码实现过程,并且对代码中涉及到的解析 HTML 表格以及写入 CSV 文件的关键部分做详细解释,感激不尽。”
(五)数据清洗(步骤五)
- 操作思路:描述目标文件中数据的大致情况(比如可能存在哪些类型的杂质信息)以及期望达到的数据清洗后的效果,让 AI 给出对应的数据清洗代码示例,并阐述每个清洗步骤的原理和作用。
- AI 指令示例:“我现在有一个 CSV 格式的目标文件,里面的数据存在一些重复记录、部分字段有缺失值,还有些数据格式不太规范,我希望用 Python 来进行数据清洗,把重复的数据去除,缺失值用合适的方法填充(比如用均值填充数值型字段等),将数据格式统一规范,你能帮我写一下完整的数据清洗代码吗?同时详细解释一下每一步数据清洗操作是如何实现的以及为什么要这样做,谢谢。”
(六)处理为输入文件(步骤六)
- 操作思路:告知 AI 模型对输入数据的要求(例如数据的维度、数据类型等),请它帮忙编写代码将预处理文件中的数据进行相应的转换和处理,生成符合模型输入的文件,同时讲解代码的功能和关键参数含义。
- AI 指令示例:“我准备用一个机器学习模型(比如简单的线性回归模型)来进行预测分析,该模型要求输入的数据是二维数组形式,数据类型为浮点型,并且要进行归一化处理。我现在有经过预处理的文件(数据格式为 [具体格式]),请你用 Python 帮我写一下代码,将这些数据转换为符合模型输入要求的文件,同时对代码里涉及的数据归一化操作以及格式转换部分详细解释一下,谢谢。”
(七)特征工程与模型构建保存(步骤七)
- 操作思路:向 AI 说明要使用的模型类型(比如决策树、神经网络等)以及想要提取的特征大致方向(可以结合数据本身特点描述),让它提供特征工程及模型构建、保存的完整代码示例,并解释代码中各个环节的意义和作用。
- AI 指令示例:“我想基于现有的输入文件数据(数据详情为 [简单描述数据情况,比如包含哪些字段等])构建一个决策树模型来进行预测,在这之前需要进行特征工程提取对预测结果有帮助的特征,你能帮我用 Python 写一下从数据中提取特征、构建决策树模型以及保存模型的完整代码吗?同时详细解释一下特征选择的依据、模型构建过程中各个参数的含义以及模型保存的方式和作用,多谢啦。”
(八)获取最新数据(步骤八)
- 操作思路:参考步骤二伪装访问行为的指令思路,再次向 AI 说明要重新爬取最新数据,按照之前的方法但可能需要更新一些网址等信息,让它提供相应代码示例以及解释如何确保新数据与之前数据的一致性等方面内容。
- AI 指令示例:“之前我按照你提供的方法成功爬取了数据,现在我想再次获取最新的数据(目标网址更新为 [新网址]),同样需要伪装成正常人类访问网页,避免被识别为爬虫,并且要保证新获取的数据和之前的数据在格式等方面能保持一致,方便后续整合分析,麻烦你帮我更新一下爬取代码,同时说明一下这次代码与之前的区别以及需要注意的地方,谢谢。”
(九)更新模型特征(步骤九)
- 操作思路:告知 AI 最新数据的情况以及已有的模型信息,让它给出将最新数据特征融入已有模型的代码示例,并解释融入过程中的关键步骤和原理,确保模型能正确更新。
- AI 指令示例:“我已经获取到了最新的数据(数据格式和之前类似,具体为 [简单描述新数据格式]),并且之前保存了一个 [具体模型名称] 模型,现在需要提取新数据的特征并入到这个已有的模型当中,你能用 Python 帮我写一下相应的代码吗?同时详细解释一下如何提取新数据特征以及怎样将这些特征融入到已有模型中,保证模型能准确更新,谢谢。”
(十)进行预测(步骤十)
- 操作思路:向 AI 说明要使用的预测模型以及输入数据的准备情况,让它提供运用该模型进行预测的代码示例,并解释代码中调用模型、传入数据以及获取预测结果等关键步骤的原理和操作方式。
- AI 指令示例:“我现在已经将最新数据的特征融入到了之前保存的模型(模型名称为 [具体模型名])当中,现在准备用这个更新后的模型进行预测,输入数据已经按照模型要求准备好了(具体的数据格式和内容为 [简单描述输入数据情况]),请你用 Python 帮我写一下利用该模型进行预测并输出结果的代码,同时详细解释一下代码里是如何调用模型、传入数据以及如何处理预测结果的,多谢。”
三、部分关键代码示例
(一)Python 中使用 requests 库伪装访问行为示例
python
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import tensorflow as tf
import chardet
# 设置 Chrome 启动选项,模拟人类正常访问
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--disable-infobars")
options.add_argument("--disable-notifications")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-browser-side-navigation")
options.add_argument("--disable-gpu")
options.add_argument("--no-sandbox")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option("useAutomationExtension", False)
# 创建 WebDriver 对象
driver = webdriver.Chrome(options=options)
# 设置等待时间,模拟人类正常访问
driver.implicitly_wait(10)
# 访问网页
url = "https://XXXXXXXXXXXXXXX.com/ssq/history/newinc/history.php?start=00001&end=25001"
driver.get(url)
#以上链接需把“=23119”修改为最新的期号,比如=23120
# 等待网页加载完成
time.sleep(5) # 可根据实际情况调整等待时间
# 获取网页内容
page_source = driver.page_source
# 检测编码格式
result = chardet.detect(page_source.encode())
encoding = result['encoding']
# 保存文件
with open("webpage.html", "w", encoding="utf-8") as f:
f.write(page_source)
# 保存网页内容到本地文件
#with open("webpage.html", "w", encoding="utf_8_sig") as f:
# f.write(page_source)
# 关闭浏览器
driver.quit()
print("数据抓取成功,结果已保存至webpage.html")(二)使用 Python 的 pandas 库进行简单数据清洗示例(假设目标文件为 CSV 格式,处理重复值和缺失值)
python
import pandas as pd
# 读取 CSV 文件
data = pd.read_csv('target_file.csv')
# 去除重复行
data = data.drop_duplicates()
# 填充缺失值,这里以数值型字段为例,用均值填充
numeric_columns = data.select_dtypes(include=['float', 'int']).columns
for col in numeric_columns:
data[col].fillna(data[col].mean(), inplace=True)
# 可以将清洗后的数据保存为新的文件,这里打印查看一下清洗后的数据
print(data.head())
上述代码只是部分关键步骤的简单示例,实际应用中你可能需要根据具体的数据情况和需求进行更多的调整和完善。
总之,作为小白,借助 AI 的强大功能,按照上述步骤以及对应的指令示例,逐步操作,就能完成从简单爬虫获取数据到最终实现预测的完整流程啦。希望大家在实践中不断积累经验,深入掌握这一实用技能哦。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











