







1. YARN概述
1.1 YARN在Hadoop生态圈中的定位
- Hadoop 1.x,MR既要负责分布式计算,还需要负责计算过程中的资管管理和任务调度
- Hadoop2.x,更新了Hadoop的架构,使用YARN(
Yet Another Resource Negotiator,另一种资源判决者/调度者)进行专门的资源组管理和任务调度,而MR通过调用YRN的API实现分布式计算,减轻了MR的压力 - 同时,YARN还具备足够的通用性,除了能支持MR之外,它还能支持其他的分布式计算模式,如Spark、Tez等
- 可以说,YARN是一种通用的资源管理和任务调度框架。
- 大部分时候,用户并不是直接使用YARN请求和使用集群资源的API,而是调用构建在YARN之上的分布式计算框架的API实现分布式计算。
- YARN很好地向用户隐藏了资源管理的细节,书中将HDF、HBase称为集群中的存储层,YARN称为是集群中的计算层。而像MR、Spark这样的分布式计算框架,是集群中的应用层。

1.2 YARN的两种守护进程及application master
守护进程1:
Resource Manager,一个全局的资源管理器,负责管理和分配整个集群中的计算资源
守护进程2:
Node Manager,运行在所有的节点上,是YARN在每个节点上的代理,管理集群中的单个计算节点,负责启动和监控container- container是有资源限制的(如内存和CPU)、用于执行特定应用程序的进程
应用程序中Application master
- 应用程序级别(
application-specified)的进程,负责管理运行在YARN上的应用程序
1.3 YARN应用的运行机制
- 书中给出了一幅很简单的图,用于描述YARN应用的运行机制
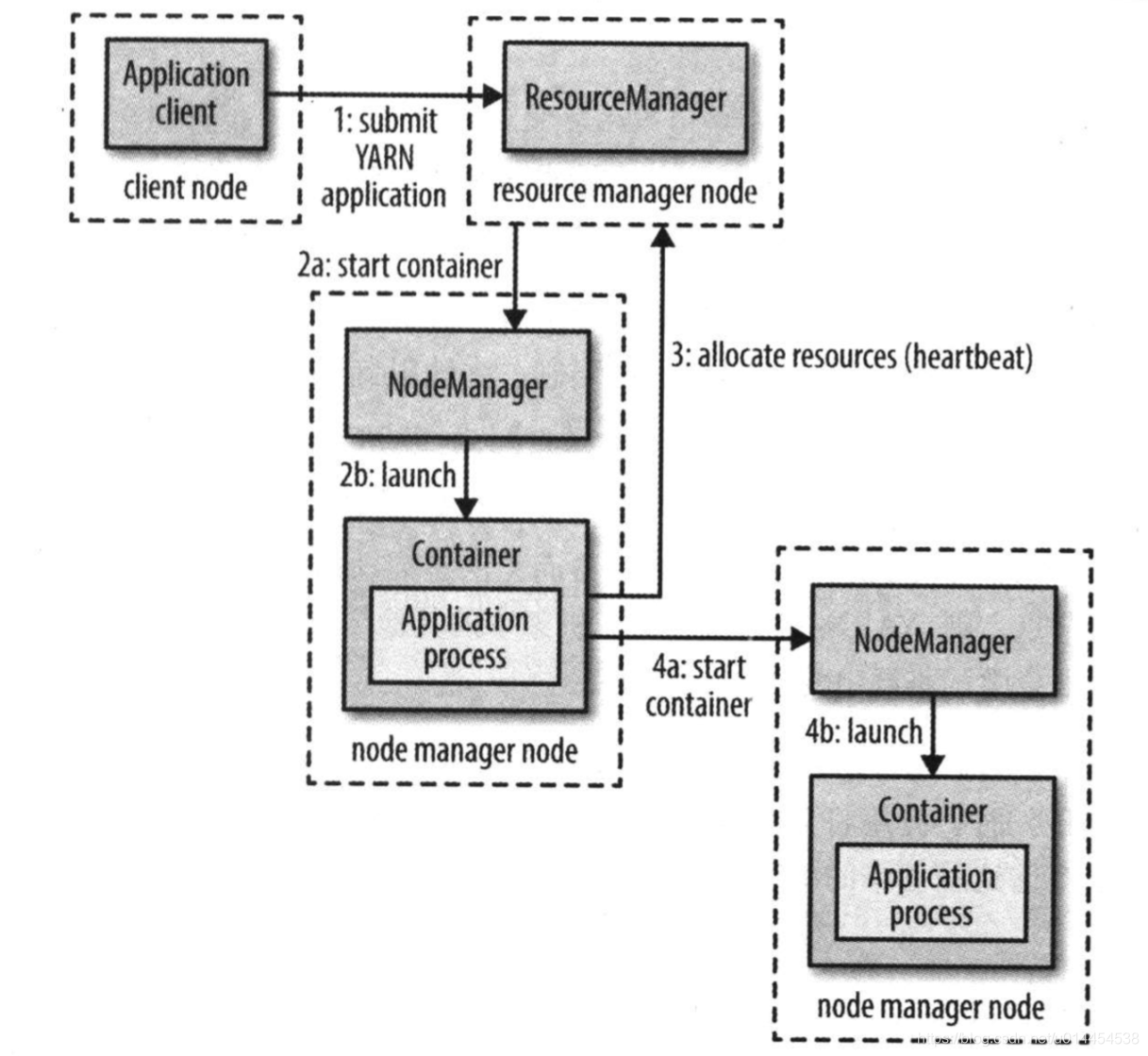
- 相对详细的图,如果需要了解更多的内部机制可以参考:yarn详解
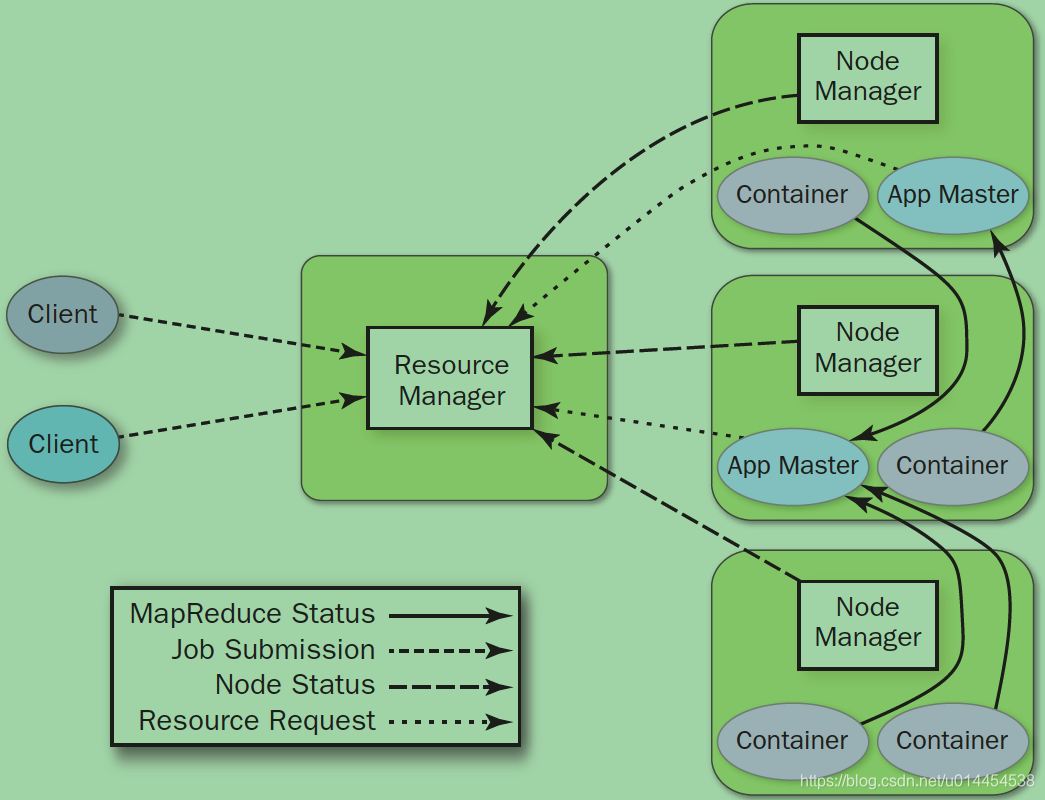
YARN应用的运行流程如下:
-
client向YARN的
Resource Manager提交应用程序,包括启动Application master的必需信息,如Application master程序、启动命令和用户程序等。 -
Resource manager为该应用程序分配第一个container,并与container所在的Node manager通信,要求Node manager启动container并在container中运行Application master。 -
Application master首先向Resource manager注册自己,并与Resource maneger保持心跳。 —— 用户可以通过Resource maneger获取应用程序的运行状态。 -
Application master采用轮询的方式、通过RPC向Resource manager申请更多的container -
申请到container后,
Application master会与container所在的Node manager建立通信,要求Node manager启动container,从而运行具体的应用程序任务 -
各个任务会通过RPC向
Application master上报自己的进度和运行状态,这样Application master便可以对任务进行监控和管理- 当任务运行失败时,
Application master可以向Resource manager申请新的container,以重新运行该任务 - client也可以通过RPC直接访问
Application master,获取任务的运行状态
- 当任务运行失败时,
-
应用程序运行完成后,
Application master向Resource manager注销并关闭自己。这时,Application master分配到的container,可以被Resource manager回收
1.4 通过运行机制,总结三种角色的作用
Resource maneger
- 与client交互,处理来自client的请求(提交作业、查询应用程序状态等)
- 启动并管理
Application master:Application master运行失败,会重启Application master。 - 资源管理与调度: 接收
Application master的资源请求,并为之分配资源 ( 其实就是分配container) - 管理
Node Manager: 接收来自Node Manager的资源汇报信息,并向Node Manager下达管理指令 —— 这条我没有啥体会 😂
Node manager
- 接收并处理来自
Application master启动/停止container的各种请求 - 启动和监控container
- 以心跳的形式向
Resource manager汇报本节点上的资源使用情况和各个Container的运行状态 —— 这条我没有啥体会 😂
Application master
- 向
Resource maneger申请container - 将申请到的contianer进一步分配给应用程序中的任务 (资源的二次分配)
- 与
Node manager通信,从而启动/停止container - 监控任务的运行状态,在任务运行失败时,重新申请资源以重试任务。
2. YARN的一些其他知识
-
需要用户实现各部分的通信:
① YARN本身不会为应用的各部分提供通信,需要自己去实现client、Application master和守护进程之间的通信。
② YARN的Distributed shell应用,是一个很好的示例。 -
本博客中,如无特殊说明,container和资源概念是等同的。
2.1 资源请求
- YARN有这灵活的资源组请求模型:既可以指定每个container的计算机资源数量(如内存的CPU),还可以指定对container的本地限制
- 本地限制可以申请位于指定节点或机架,甚至是集群中任意节点(机架外)的container
- 本地限制的目的: 充分利用本地化,实现对分布式集群带宽的高效使用。
MR中的本地限制:
- 在拥有block副本的节点上为map任务申请container
- 申请失败,则向副本所在机架的其他节点申请container
- 申请失败,则向集群中的任意节点申请container
资源申请的时间:
- 在应用程序开始运行前,就申请好所有需要的资源
- 在应用程序的运行过程中,动态的申请所需资源:MR程序,先申请map任务的资源,后续再申请reduce任务的资源
2.2 YARN应用的生命周期
按照作业与YARN应用的映射关系进行分类:
- 一个用户作业对应一个YARN应用,如MR
- 作业的每个工作流或每个用户对话,对应一个YARN应用,如Spark
- 多个用户共享一个长期运行的YARN应用:Impala通过长期运行(always on)的
Application master,以提供低延迟的查询响应
2.3 YARN与MR 1
- 之前,我们提到过Hadoop架构的变化,我们将
Hadoop 1.x中的MapReduce框架叫做MR 1,以区别使用了YARN后的MapReduce框架MR 2
(1) MR 1 中的两类守护进程:一个jobtracker、一个或若干个tasktracker,共同控制着作业的执行过程
jobtracker通过调度tasktracker上运行的任务来协调所有运行在系统上的作业tasktraker在任务运行的同时,将进度报告发送给jobtracker,jobtracker由此记录每项作业任务的整体进度情况- 如果其中一个任务失败,
jodtracker可以在另一个tasktracker节点上重新调度该任务。
- 总结来说:
jobtracker是MR 1中,作业调度、资源管理的master节点;tasktracker是MR 1中,任务运行、进度上报的slave节点
(2)在tasktracker上,都会配置若干固定长度的slot。
- 这些slot是静态配置的,在配置时就被划分成了map slot以及reduce slot,只能运行对应的map任务或reduce任务。
- 例如,tasktracker上的map slot有剩余,但reduce slot无剩余,则reduce任务需要等待reduce slot空闲才能执行,而不能去使用空闲的map slot
- 这样的资源分配策略非常不灵活,大大降低了资源组的利用率
(3) MR 1和YARN在组成上的比较:
-
通过了解MR 1,我们不难发现MR 1的各种组件,与YARN可以形成对比:
MapReduce 1 作用 YARN jobtracker 作业调度(任务与tasktracker的结合)、进度监控(跟踪任务、重启失败或迟缓的任务)、记录任务流水 1. 作业调度和进度监控:Resource manager和Application manager;
2. 记录任务流水:时间轴服务器(timeline server)tasktracker 任务运行以及进度上报 Node manager slot 静态配置,只能运行对应的map任务或slot任务 container
(4)YARN的优势:
- 可扩展性:
① 在MR 1中,jobtracker必须同时管理作业和任务,使得当节点达到 4000 4000 4000,任务数达到 40000 40000 40000时,MR 1将会遇到源于jobtracker的可扩展性瓶颈;
② YARN利用Resource manager和Application master分离的架构,克服了这个局限性,使得Hadoop集群可以扩展到 10000 10000 10000个节点和 10 万 10万 10万个任务
③ 基于Application master的设计,与google MapReduce论文中的描述更接近:有一个master进程负责协调运行在一系列worker上的map任务和reduce任务。 - 可用性:
① 高可用性(HA)要求:当服务的守护进程失败时,通过为另一个守护进程复制接管工作所需的状态以继续提供服务。
②jobtracker的内存中有大量快速变化的复杂状态,想要为jobtracker提供HA是非常困难的。
③ YARN中,jobtracker的HA变成一个分而治之的问题:为Resource manager提供HA,为Application master提供HA - 利用率:
① 前面,提到过MR 1中基于slot的资源配置利用非常低
② YARN的一个Node manager管理一个资源池,当资源有空闲时都可以分配给新的任务进行使用,而不是固定只能某种任务才能使用
③ 也就是说,YARN中资源是精细化管理的:任务所需的资源是按需请求,而非请求一个不可分割的、对特定任务而言太大或太小的slot - 多租户: YARN不仅支持MR,还支持其他的分布式应用。
3. 总结
-
Hadoop 1.x和2.x的架构变化:使用YARN(Yet Another Resource Negotiator)进行资源管理和任务调度,减轻了MR的压力 -
YARN是一种通用的资源管理和任务调度框架,处于计算层,可以支持多种分布式应用 ( 三层结构)
-
两种守护进程:
Resource manager、Node manager, 一个应用程序级别的进程:Application masterResource manager:全局的资源管理器,负责管理和分配集群中的计算资源Node manager:YARN在每个节点上的代理,管理单个计算节点,负责启动和监控ocntainer- container:执行特定应用程序的进程,有一定的资源(如内存或CPU)
Application master:负责管理应用程序
-
YARN应用的运行机制:
Resource manager负责分配container,监控Application masterApplication master负责申请container,与Node manager通信以启动/停止container,管理和监控运行在container中的任务(失败重启、client的RPC查询等)Node manager维护着一个资源池,接收Application master的命令,以启动/停止container
-
从运行机制看三种角色的具体功能:
Resource manager:与client交互,管理Application master,资源管理与调度,管理Node managerNode manager:接收Application master的命令,启动和监控container,维护资源池、向Resource Manager上报container状态Application master: 向Resource manager申请资源,资源二次分配至任务,与Node manager通信、管理和监控任务的运行(任务失败重启)
-
container申请时,可以指定资源数量和本地限制(尽最大可能的通过本地化高效使用集群带宽),以MR为例看container的创建策略
-
注意事项: YARN本身不为应用的各部分提供通信机制
-
YARN生命周期的分类:
- 一个用户作业对应一个应用
- 作业的工作流或用户会话对应一个应用
- 多用户共享长期运行的应用:Impale always on的Application master,提供低延迟的查询响应
-
YARN与MR 1:
- jobtracker和tasktracker的是如何相互配合,实现资源管理和任务调度的
- jobtacker的作业调度、进度跟踪 ⟶ YARN的Resource manager、Application master; jobtracker的任务记录 ⟶ YARN的时间轴服务器
- tasktracker ⟶ YARN的Node manager
- slot(固定长度、静态配置、不可混用 ) ⟶ YARN的container
-
YARN的优势:
- 可扩展性(分离架构克服了jobtracker的扩展性瓶颈,Application master与Google的MapReduce论文更接近)
- 可用性:jobtracker难以提供HA,YARN中分而治之的HA
- 利用率(slot方式的利用率低,基于Node manager的资源池实现资源的灵活分配)
- 多租户:YARN是一种通用的资源管理和任务调度框架,并非仅支持MR














 4776
4776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









