







一、实现目标
获取京东网站上商品的评论统计数据,并使用该数据制作了一个简单的柱状图。
二、实现步骤
2.1 网页分析
首先打开链接https://www.jd.com/。在搜索框中输入巧克力关键词后,点击第一件商品打开商品网页,找到商品评价,在商品评价模块能够看到用户选择的评论标签。由于该商品的全部用户评论有50万+,数据量较大。我们需要收集商品特点,所以我们选择对评价标签进行分析。
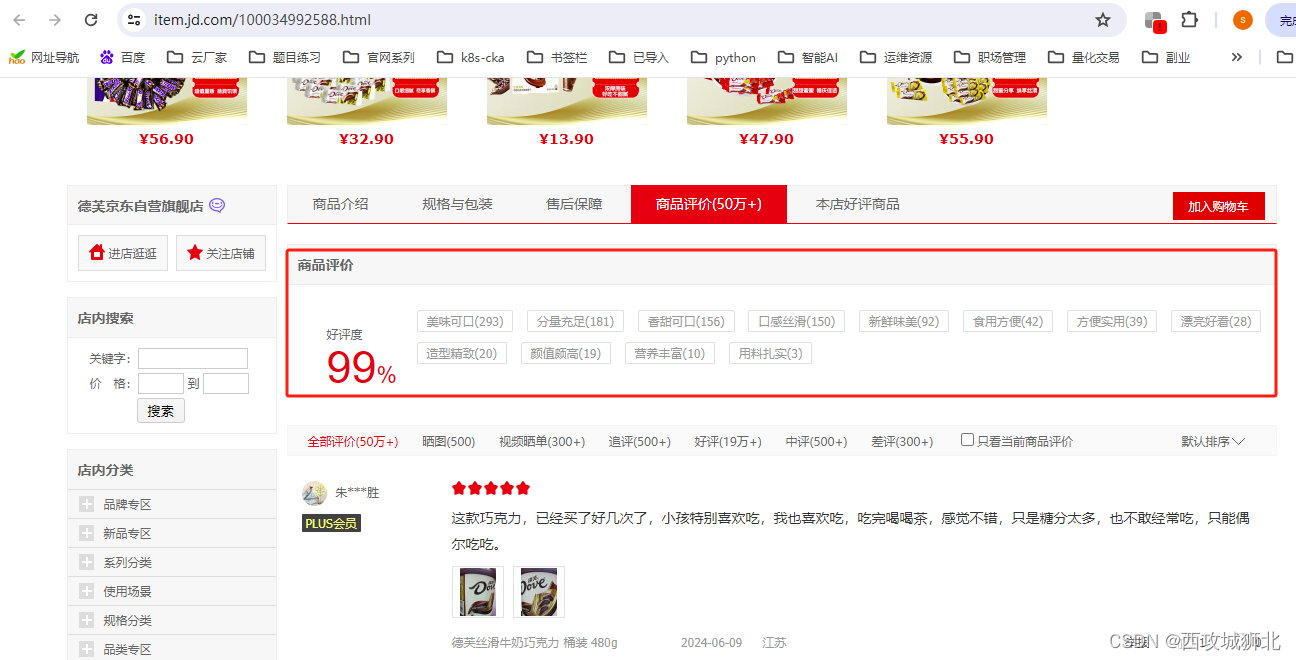
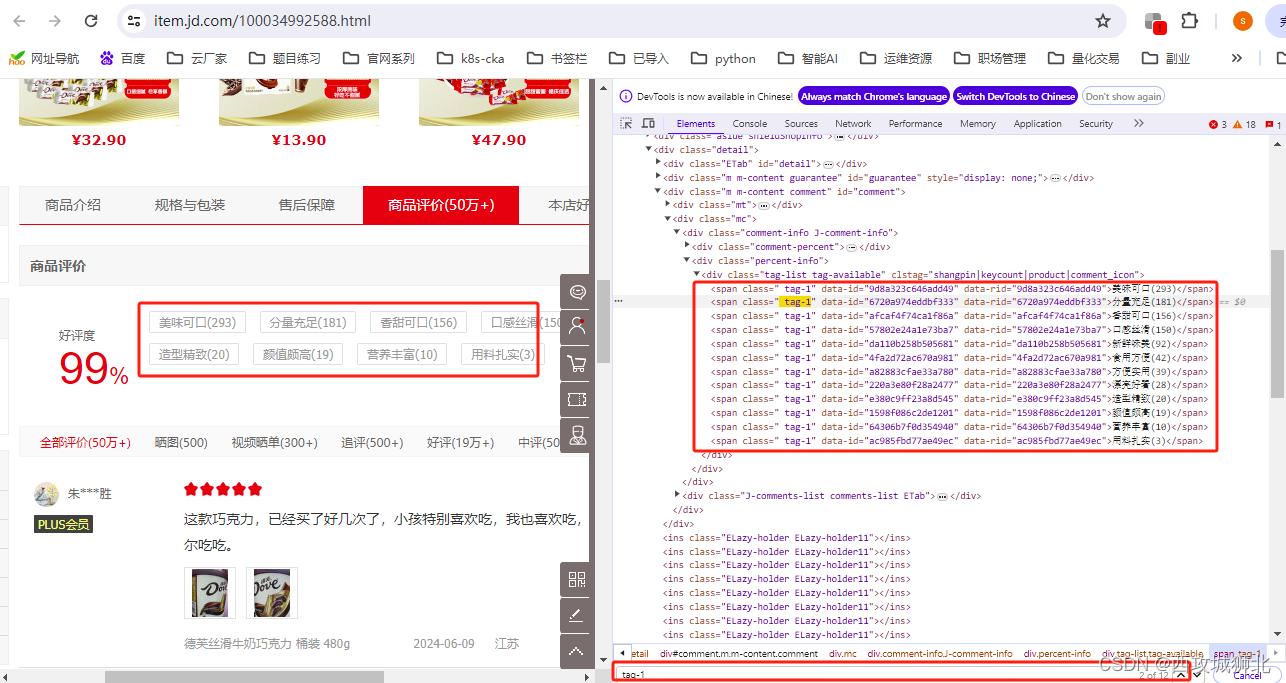
打开 https://item.jd.com/100034992588.html,查看网页源代码,使用鼠标定位法可以看到要提取的评论标签在节点 class="tag-1" 中。使用 Ctrl+F 打开搜索栏,输入 .tag-1 查看检索结果,如图所示,可以确定搜索到的数量为12,与评论数量一致,可以直接使用tag-1 进行筛选。
2.2 网页请求
复制商品链接"https://item.jd.com/1178886.html",导入requests模块对网页发出请求,从 bs4 模块中导入 BeautifulSoup 用于解析网页内容。使用 find_all() 查找满足条件 class="tag-1" 的节点并输出。
# 使用import导入requests模块
import requests
# 使用from...import从bs4模块中导入BeautifulSoup
from bs4 import BeautifulSoup
# 将"https://item.jd.com/1178886.html"赋值给url
url = "https://item.jd.com/100034992588.html"
# 将User-Agent以字典键对形式赋值给headers
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36"}
# 使用get()函数请求链接,并且带上headers,赋值给response
response = requests.get(url, headers=headers)
# 使用.text属性将服务器相应内容转换为字符串形式,赋值给html
html = response.text
# 使用BeautifulSoup()传入变量html和解析器lxml,赋值给soup
soup = BeautifulSoup(html, "lxml")
# 使用find_all()查询soup中class="tag-1"的节点,赋值给content_all
content_all = soup.find_all(class_="tag-1")
# 使用print()输出content_all
print(content_all)执行结果如下
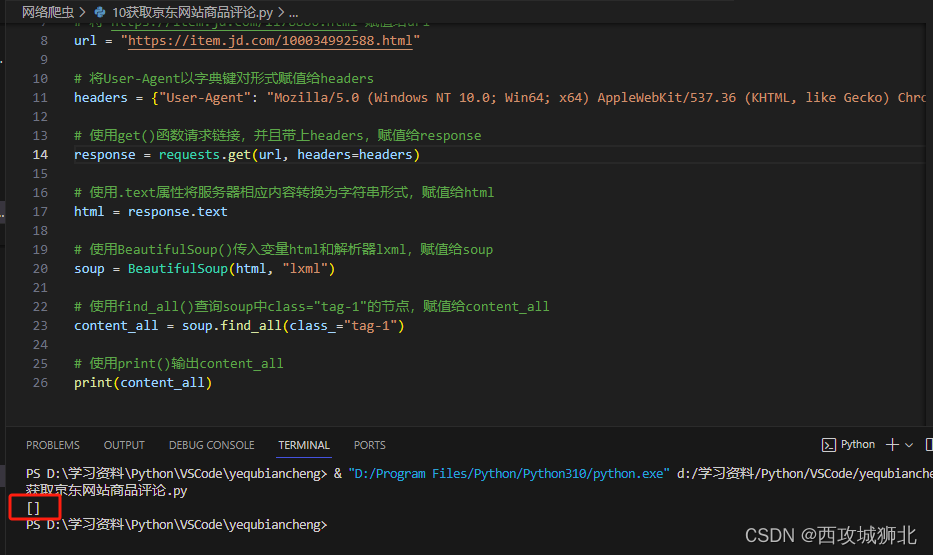 从上面的图中可以看到并没有获取到评论数据,我们先查看html源代码,在其中搜索评论内容,但是并未搜索到评论信息。
从上面的图中可以看到并没有获取到评论数据,我们先查看html源代码,在其中搜索评论内容,但是并未搜索到评论信息。
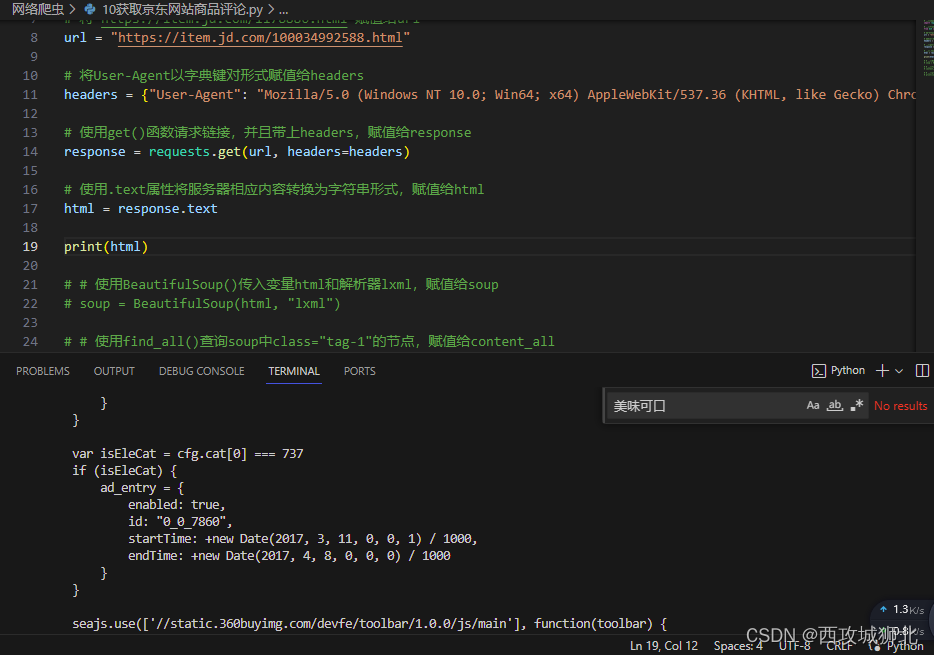
打开链接 https://item.jd.com/100034992588.html,找到商品详情页,在开发者模式中,查看商品编号100034992588对应的文件100034992588.html。点击文件,打开 Preview 预览文件内容,可以发现大部分信息都显示正在加载。所以说,原始的 HTML 代码提供的是一个框架,没有全部的信息,评论内容属于动态加载的数据。

如下图,我们重新选择文件类型为Fetch/XHR,可以筛选出动态加载的链接,然后点击商品评论,重新加载数据,查看新加载的链接,在Proview中可以找到商品评论,
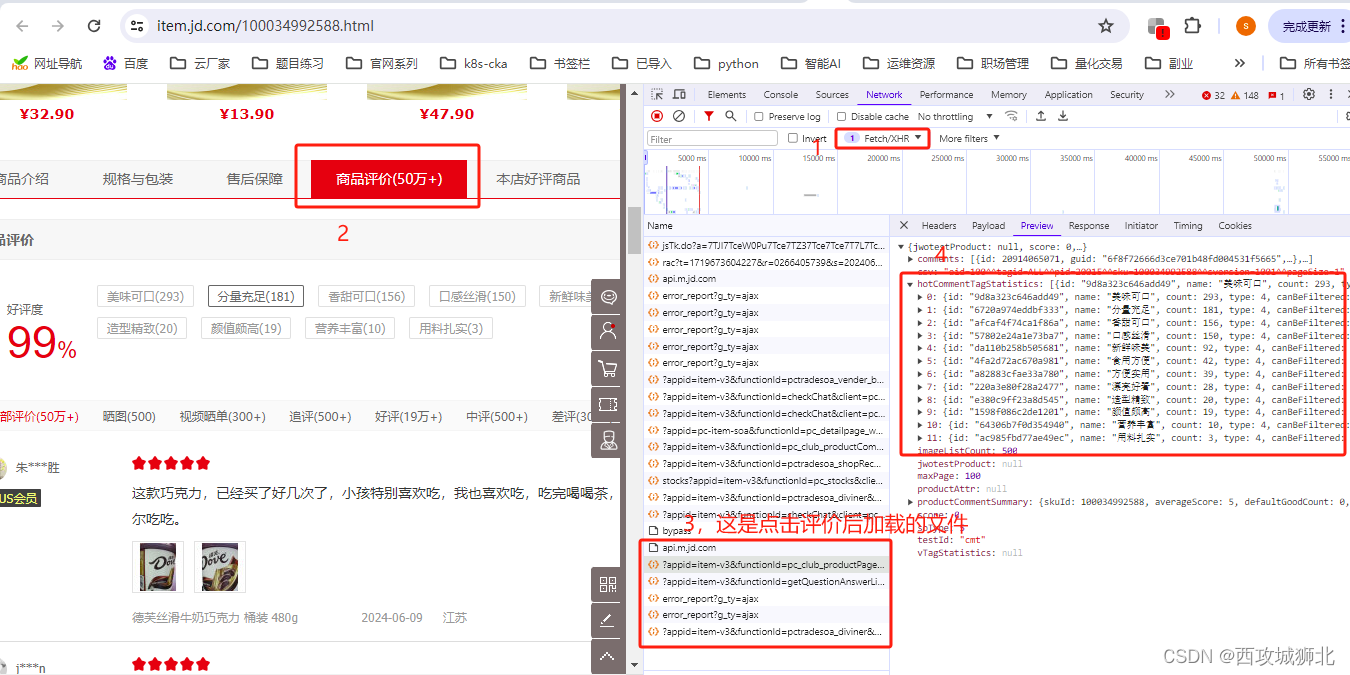 通过content-Type可以确定这是一个json类型的接口。
通过content-Type可以确定这是一个json类型的接口。
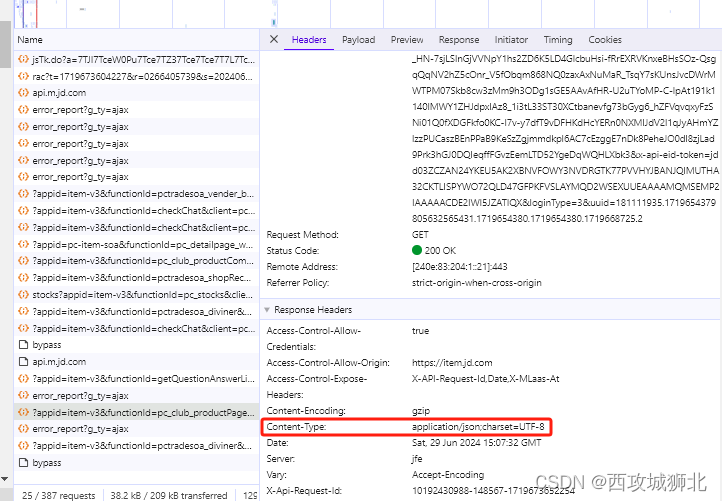
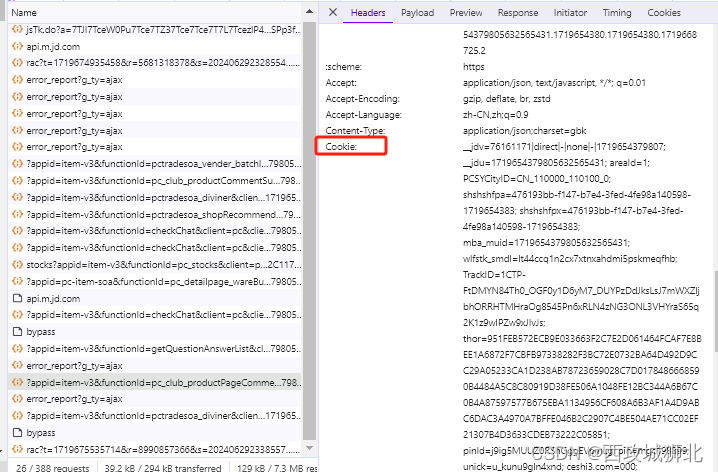
我们重新通过api接口请求json数据,这里我们要在headers中添加一个Cookie参数,Cookie的值从浏览器中获取(Cookie值时间长了就会过期,需要重新获取)。
# 使用import导入requests模块
import requests
# 使用from...import从bs4模块中导入BeautifulSoup
from bs4 import BeautifulSoup
# 将"https://item.jd.com/1178886.html"赋值给url
url = "https://api.m.jd.com/?appid=item-v3&functionId=pc_club_productPageComments&client=pc&clientVersion=1.0.0&t=1719673651911&body=%7B%22productId%22%3A100034992588%2C%22score%22%3A0%2C%22sortType%22%3A5%2C%22page%22%3A0%2C%22pageSize%22%3A10%2C%22isShadowSku%22%3A0%2C%22fold%22%3A1%2C%22bbtf%22%3A%22%22%2C%22shield%22%3A%22%22%7D&h5st=20240629230731927%3By9nnyng5itz99y64%3Bfb5df%3Btk03wb0641ce918nIUOHQp2cWCj8thAZ6NfnZk2ppsGEh2Db1dO_TXNoHNUcOKplYu_yNkyHpHd4UqBlobSwsxv7F9r4%3B0b2d31ee57e069b84721aaf5d88b28e295811d8ccc3206faeac5fe8bd393e0ed%3B4.7%3B1719673651927%3BTKmWblRC92mm0IeNArM6DQJS2sW6iUevdi1tNQHZHMshzmReyR5w4CmoHE9qZr_HN-7sjLSlnGjVVNpY1hs2ZD6K5LD4GlcbuHsi-fRrEXRVKnxeBHsSOz-QsgqQqNV2hZ5cOnr_V5fObqm868NQ0zaxAxNuMaR_TsqY7sKUnsJvcDWrMWTPM07Skb8cw3zMm9h3ODg1sGE5AAvAfHR-U2uTYoMP-C-lpAt191k1140lMWY1ZHJdpxlAz8_1i3tL33ST30XCtbanevfg73bGyg6_hZFVqvqxyFzSNi01Q0fXDGFkfo0KC-l7v-y7dfT9vDFHKdHcYERn0NXMIJdV2l1qJyAHmYZlzzPUCaszBEnPPaB9KeSzZgjmmdkpl6AC7cEzggE7nDk8PeheJO0dl8zjLad9Prk3hGJ0DQIeqffFGvzEemLTD52YgeDqWQHLXbk3&x-api-eid-token=jdd03ZCZAN24YKEU5AK2XBNVFOWY3NVDRGTK77PVVHYJBANJQIMUTHA32CKTLISPYWO72QLD47GFPKFVSLAYMQD2WSEXUUEAAAAMQMSEMP2IAAAAACDE2IWI5JZATIQX&loginType=3&uuid=181111935.1719654379805632565431.1719654380.1719654380.1719668725.2"
# 将User-Agent以字典键对形式赋值给headers
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36",
"Cookie": "__jdv=76161171|direct|-|none|-|1719654379807; __jdu=1719654379805632565431; areaId=1; PCSYCityID=CN_110000_110100_0; shshshfpa=476193bb-f147-b7e4-3fed-4fe98a140598-1719654383; shshshfpx=476193bb-f147-b7e4-3fed-4fe98a140598-1719654383; mba_muid=1719654379805632565431; wlfstk_smdl=lt44ccq1n2cx7xtnxahdmi5pskmeqfhb; TrackID=1CTP-FtDMYN84Th0_OGF0y1D6yM7_DUYPzDdJksLsJ7mWXZljbhORRHTMHraOg8545Pn6xRLN4zNG3ONL3VHYraS65q2K1z9wIPZw9xJIvJs; thor=951FEB572ECB9E033663F2C7E2D061464FCAF7E8BEE1A6872F7CBFB97338282F3BC72E0732BA64D492D9CC29A05233CA1D238AB78723659028C7D0178486668590B4484A5C8C80919D38FE506A1048FE12BC344A6B67C0B4A87597577B675EBA1134956CF608A6B3AF1A4D9ABC6DAC3A4970A7BFFE046B2C2907C4BE504AE71CC02EF21307B4D3633CDEB73222C05851; pinId=j9ig5MUUZ0RShGggEVpmLg; pin=mgc198899; unick=u_kunu9gln4xnd; ceshi3.com=000; _tp=Y95kYQuGiJXeazpQ0ijCkQ%3D%3D; _pst=mgc198899; jsavif=1; 3AB9D23F7A4B3C9B=ZCZAN24YKEU5AK2XBNVFOWY3NVDRGTK77PVVHYJBANJQIMUTHA32CKTLISPYWO72QLD47GFPKFVSLAYMQD2WSEXUUE; __jda=181111935.1719654379805632565431.1719654380.1719654380.1719668725.2; __jdc=181111935; ipLoc-djd=1-2805-55650-0; token=09eb21aa8facbedbfb3bbcfe91cf0a8c,3,955374; __tk=IiOIva5T0iz3uMXWyCKtOg5aJBb4OizUIDhpOB9K0IKsva5cIgbuwa5qHDK4IcaAyBhduVrC,3,955374; 3AB9D23F7A4B3CSS=jdd03ZCZAN24YKEU5AK2XBNVFOWY3NVDRGTK77PVVHYJBANJQIMUTHA32CKTLISPYWO72QLD47GFPKFVSLAYMQD2WSEXUUEAAAAMQMSORMZIAAAAADD5365PJC7MUCYX; _gia_d=1; __jdb=181111935.16.1719654379805632565431|2.1719668725; flash=2_kHSFBx92HseXmm5oEi5qyDZPx55FJJWYzvMOk_pgm5dCMfiI6_gVB1GOEPtAif-oIDMhEyXtNc8QCTQVFnQQgqXemeBdBFITGZteqXPYaIjO_tAiKrzgGJ4TXBIf-3GSQ4ArQtBMjMrboalvHFn44NiMptoqOTpjfLbMHnTKP7k*; shshshfpb=BApXc0LOVZ_VAlz2rAwBZUI0kJp4x0rRCBlskRKxo9xJ1MkrsYoC2"}
# 使用get()函数请求链接,并且带上headers,赋值给response
response = requests.get(url, headers=headers)
# 使用.text属性将服务器相应内容转换为字符串形式,赋值给html
html = response.text
print(html)以下是获取到的json数据
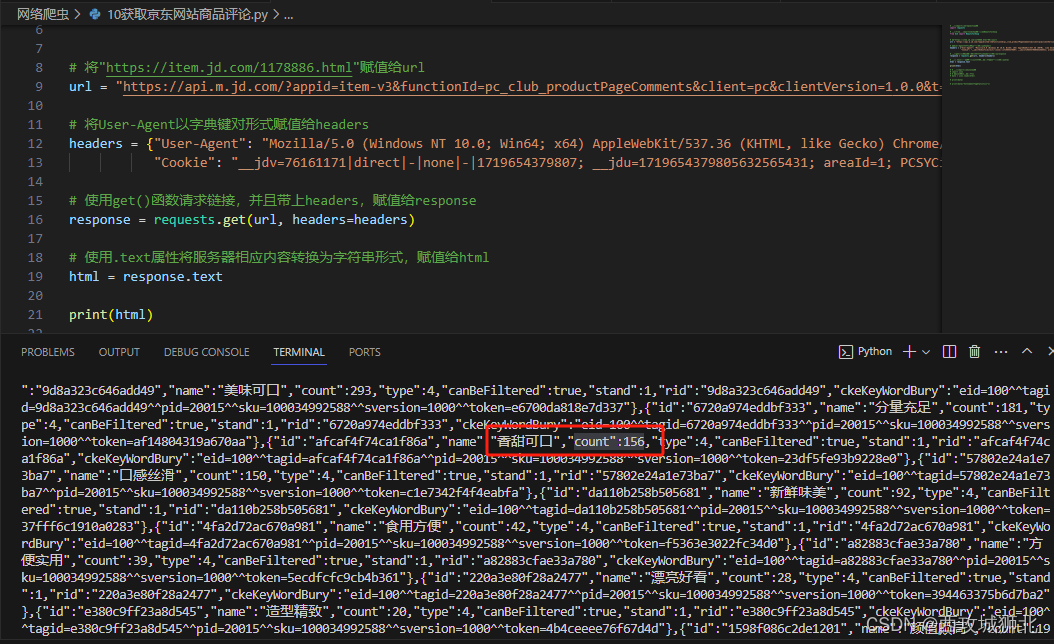
2.3 网页解析
接下来我们对获得的json数据进行解析,以下代码可以把json类型转化为字典,然后按照字典的使用规范来提取评论数据。
# 使用import导入json模块
import json
# 将json数据转换为字典
data = json.loads(html)
print(data) 转化后如下图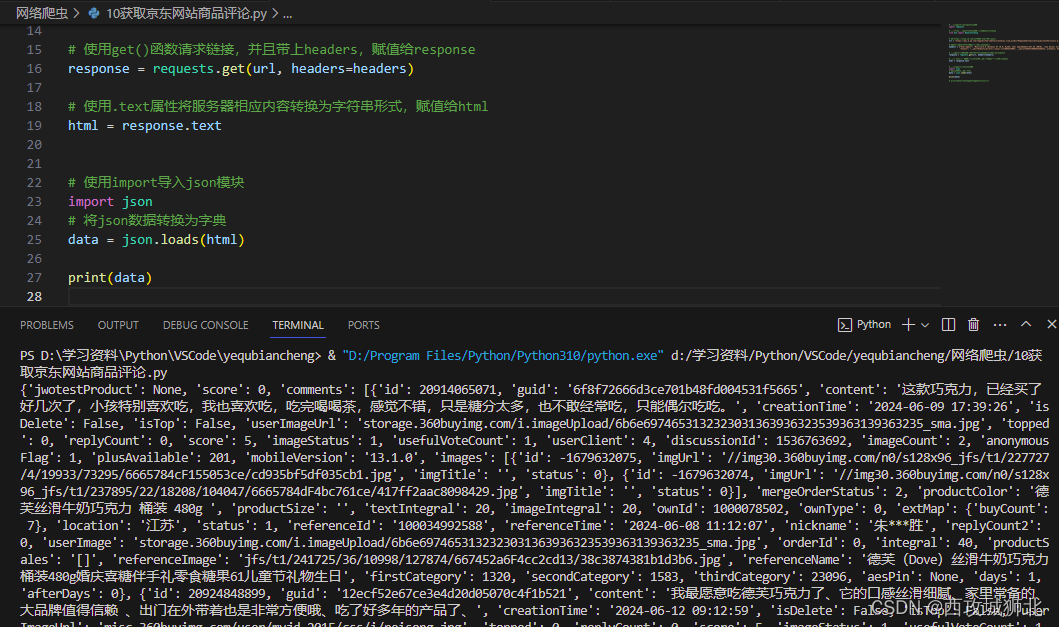
我们需要提取出字典中的hotCommentTagStatistics,提取结果为一个列表
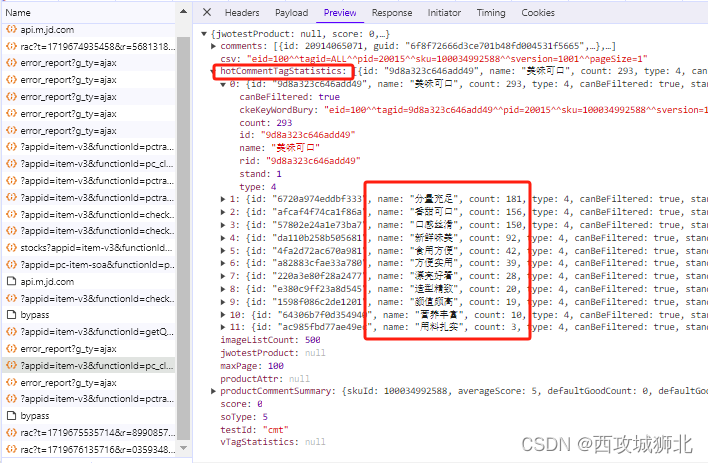
如下是获取到的数据列表
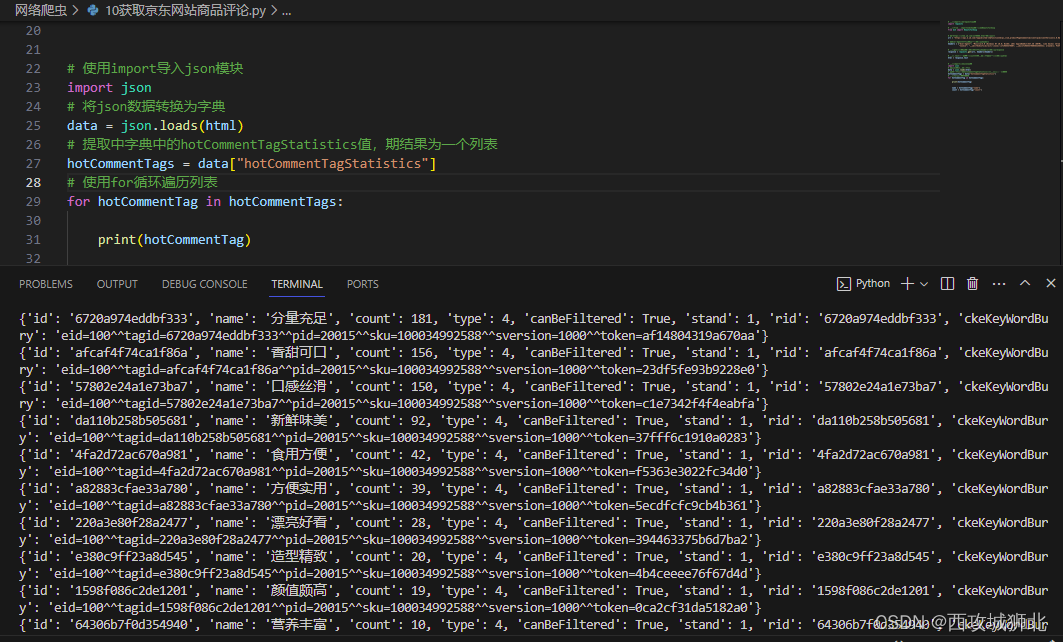
然后提取name和count的值
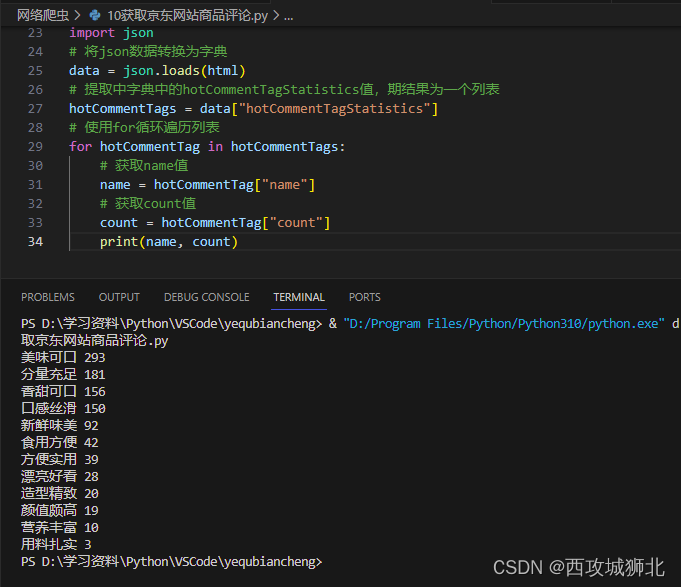
以下是接口解析的完整代码
# 使用import导入json模块
import json
# 将json数据转换为字典
data = json.loads(html)
# 提取中字典中的hotCommentTagStatistics值,期结果为一个列表
hotCommentTags = data["hotCommentTagStatistics"]
# 使用for循环遍历列表
for hotCommentTag in hotCommentTags:
# 获取name值
name = hotCommentTag["name"]
# 获取count值
count = hotCommentTag["count"]
print(name, count)2.4 保存数据
新建一个字典tagdict,将name和count的值保存到字典中。
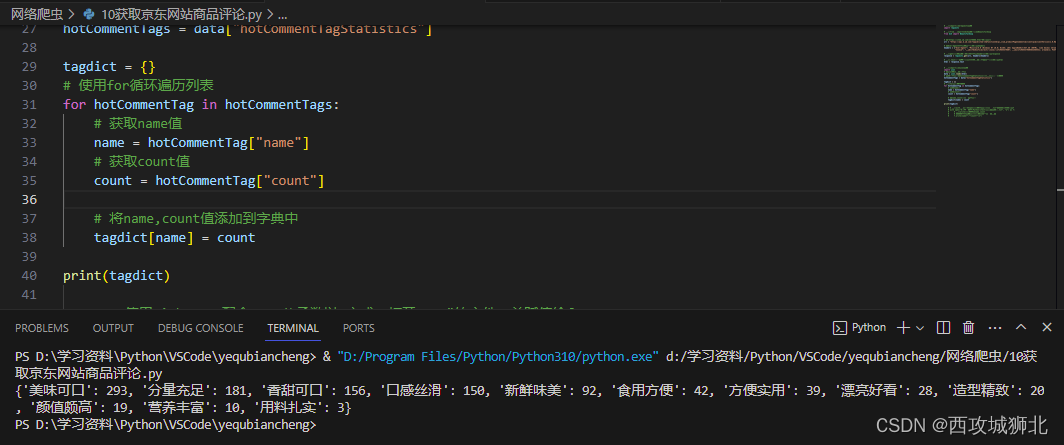
2.5 制作柱状图
最后使用pyecharts.charts 的Bar类制作一个柱状图
# 使用from...import从pyecharts.charts中导入Bar
from pyecharts.charts import Bar
# 使用Bar()创建bar对象,赋值给bar
bar = Bar()
# 使用list()将字典tagdict所有键转换成列表,传入add_xaxis()中
bar.add_xaxis(list(tagdict.keys()))
# 使用add_yaxis()函数,将数据统称设置为"评论"
# 将字典tagdict所有值,作为参数添加进函数中
bar.add_yaxis("评论", list(tagdict.values()))
# 使用render()函数存储文件,设置文件名为"tile.html"
bar.render("D:/学习资料/Python/stest/tile.html")执行后得到一个tile.html文件
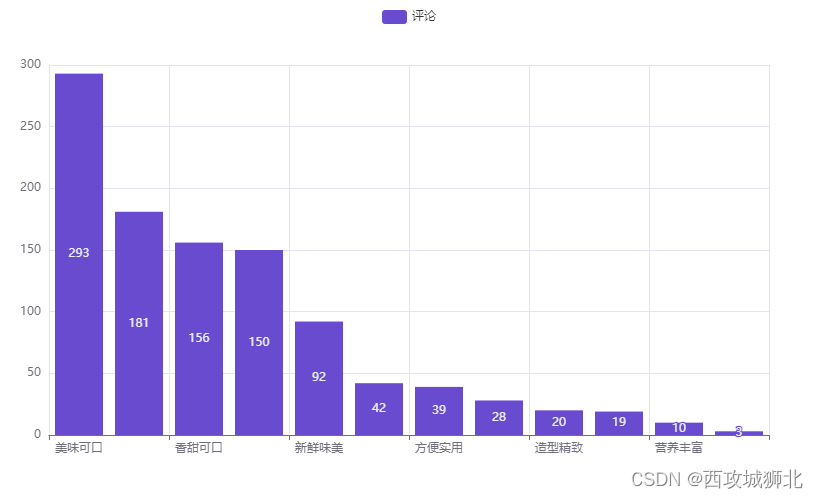
 使用浏览器打开后就是我们想要的商品评论柱状图
使用浏览器打开后就是我们想要的商品评论柱状图
 最后整理完善一下代码
最后整理完善一下代码
# 使用import导入requests模块
import requests
# 使用from...import从bs4模块中导入BeautifulSoup
from bs4 import BeautifulSoup
# 使用import导入json模块
import json
# 使用from...import从pyecharts.charts中导入Bar
from pyecharts.charts import Bar
# 将"https://item.jd.com/1178886.html"赋值给url
url = "https://api.m.jd.com/?appid=item-v3&functionId=pc_club_productPageComments&client=pc&clientVersion=1.0.0&t=1719673651911&body=%7B%22productId%22%3A100034992588%2C%22score%22%3A0%2C%22sortType%22%3A5%2C%22page%22%3A0%2C%22pageSize%22%3A10%2C%22isShadowSku%22%3A0%2C%22fold%22%3A1%2C%22bbtf%22%3A%22%22%2C%22shield%22%3A%22%22%7D&h5st=20240629230731927%3By9nnyng5itz99y64%3Bfb5df%3Btk03wb0641ce918nIUOHQp2cWCj8thAZ6NfnZk2ppsGEh2Db1dO_TXNoHNUcOKplYu_yNkyHpHd4UqBlobSwsxv7F9r4%3B0b2d31ee57e069b84721aaf5d88b28e295811d8ccc3206faeac5fe8bd393e0ed%3B4.7%3B1719673651927%3BTKmWblRC92mm0IeNArM6DQJS2sW6iUevdi1tNQHZHMshzmReyR5w4CmoHE9qZr_HN-7sjLSlnGjVVNpY1hs2ZD6K5LD4GlcbuHsi-fRrEXRVKnxeBHsSOz-QsgqQqNV2hZ5cOnr_V5fObqm868NQ0zaxAxNuMaR_TsqY7sKUnsJvcDWrMWTPM07Skb8cw3zMm9h3ODg1sGE5AAvAfHR-U2uTYoMP-C-lpAt191k1140lMWY1ZHJdpxlAz8_1i3tL33ST30XCtbanevfg73bGyg6_hZFVqvqxyFzSNi01Q0fXDGFkfo0KC-l7v-y7dfT9vDFHKdHcYERn0NXMIJdV2l1qJyAHmYZlzzPUCaszBEnPPaB9KeSzZgjmmdkpl6AC7cEzggE7nDk8PeheJO0dl8zjLad9Prk3hGJ0DQIeqffFGvzEemLTD52YgeDqWQHLXbk3&x-api-eid-token=jdd03ZCZAN24YKEU5AK2XBNVFOWY3NVDRGTK77PVVHYJBANJQIMUTHA32CKTLISPYWO72QLD47GFPKFVSLAYMQD2WSEXUUEAAAAMQMSEMP2IAAAAACDE2IWI5JZATIQX&loginType=3&uuid=181111935.1719654379805632565431.1719654380.1719654380.1719668725.2"
# 将User-Agent以字典键对形式赋值给headers
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36",
"Cookie": "__jdv=76161171|direct|-|none|-|1719654379807; __jdu=1719654379805632565431; areaId=1; PCSYCityID=CN_110000_110100_0; shshshfpa=476193bb-f147-b7e4-3fed-4fe98a140598-1719654383; shshshfpx=476193bb-f147-b7e4-3fed-4fe98a140598-1719654383; mba_muid=1719654379805632565431; wlfstk_smdl=lt44ccq1n2cx7xtnxahdmi5pskmeqfhb; TrackID=1CTP-FtDMYN84Th0_OGF0y1D6yM7_DUYPzDdJksLsJ7mWXZljbhORRHTMHraOg8545Pn6xRLN4zNG3ONL3VHYraS65q2K1z9wIPZw9xJIvJs; thor=951FEB572ECB9E033663F2C7E2D061464FCAF7E8BEE1A6872F7CBFB97338282F3BC72E0732BA64D492D9CC29A05233CA1D238AB78723659028C7D0178486668590B4484A5C8C80919D38FE506A1048FE12BC344A6B67C0B4A87597577B675EBA1134956CF608A6B3AF1A4D9ABC6DAC3A4970A7BFFE046B2C2907C4BE504AE71CC02EF21307B4D3633CDEB73222C05851; pinId=j9ig5MUUZ0RShGggEVpmLg; pin=mgc198899; unick=u_kunu9gln4xnd; ceshi3.com=000; _tp=Y95kYQuGiJXeazpQ0ijCkQ%3D%3D; _pst=mgc198899; jsavif=1; 3AB9D23F7A4B3C9B=ZCZAN24YKEU5AK2XBNVFOWY3NVDRGTK77PVVHYJBANJQIMUTHA32CKTLISPYWO72QLD47GFPKFVSLAYMQD2WSEXUUE; __jda=181111935.1719654379805632565431.1719654380.1719654380.1719668725.2; __jdc=181111935; ipLoc-djd=1-2805-55650-0; token=09eb21aa8facbedbfb3bbcfe91cf0a8c,3,955374; __tk=IiOIva5T0iz3uMXWyCKtOg5aJBb4OizUIDhpOB9K0IKsva5cIgbuwa5qHDK4IcaAyBhduVrC,3,955374; 3AB9D23F7A4B3CSS=jdd03ZCZAN24YKEU5AK2XBNVFOWY3NVDRGTK77PVVHYJBANJQIMUTHA32CKTLISPYWO72QLD47GFPKFVSLAYMQD2WSEXUUEAAAAMQMSORMZIAAAAADD5365PJC7MUCYX; _gia_d=1; __jdb=181111935.16.1719654379805632565431|2.1719668725; flash=2_kHSFBx92HseXmm5oEi5qyDZPx55FJJWYzvMOk_pgm5dCMfiI6_gVB1GOEPtAif-oIDMhEyXtNc8QCTQVFnQQgqXemeBdBFITGZteqXPYaIjO_tAiKrzgGJ4TXBIf-3GSQ4ArQtBMjMrboalvHFn44NiMptoqOTpjfLbMHnTKP7k*; shshshfpb=BApXc0LOVZ_VAlz2rAwBZUI0kJp4x0rRCBlskRKxo9xJ1MkrsYoC2"}
# 使用get()函数请求链接,并且带上headers,赋值给response
response = requests.get(url, headers=headers)
# 使用.text属性将服务器相应内容转换为字符串形式,赋值给html
html = response.text
# 将json数据转换为字典
data = json.loads(html)
# 提取中字典中的hotCommentTagStatistics值,期结果为一个列表
hotCommentTags = data["hotCommentTagStatistics"]
# 定义一个字典,存储结果数据
tagdict = {}
# 使用for循环遍历列表
for hotCommentTag in hotCommentTags:
# 获取name值
name = hotCommentTag["name"]
# 获取count值
count = hotCommentTag["count"]
# 将name,count值添加到字典中
tagdict[name] = count
# 使用Bar()创建bar对象,赋值给bar
bar = Bar()
# 使用list()将字典tagdict所有键转换成列表,传入add_xaxis()中
bar.add_xaxis(list(tagdict.keys()))
# 使用add_yaxis()函数,将数据统称设置为"评论"
# 将字典tagdict所有值,作为参数添加进函数中
bar.add_yaxis("评论", list(tagdict.values()))
# 使用render()函数存储文件,设置文件名为"tile.html"
bar.render("D:/学习资料/Python/stest/tile.html")
print("success")
三、总结
在本实例中,我们获取了京东商品的评论统计数据,并使用该数据制作了一个简单的柱状图,使用到的模块包括:requests、json和pyecharts。
requests:是一个常用的 HTTP 请求库,可以方便地向网站发送 HTTP 请求,并获取响应结果。requests 模块比 urllib 模块更简洁。
json:是Python标准库中的一个用于处理JSON数据的模块,它提供了一组方法来进行 JSON 数据的解析和生成。JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,常用于数据传输和配置文件。
pyecharts:是一个用于生成 ECharts 图表的 Python 库,其提供了丰富的图表类型,包括折线图、柱状图、散点图、饼图、地图、热力图等。它支持高度定制,你可以通过简单的 Python 代码实现丰富的数据可视化效果。
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











