









1、id 执行的顺序
id 是select的执行顺序,id越大优先级越高,越先被执行,id 相同时 下面的先执行.
原因是因为执行子查询时,先查内层的,再查外层
SELECT
de.*
FROM
dict_equip de
WHERE
de.n_equip_id = (
SELECT n_equip_id FROM equip e WHERE
e.n_role_id = (
SELECT n_role_id FROM role r WHERE r.s_name = '香菜' )
)
从上面的执行计划可以看到先执行了查询role表,后执行了equip ,最后执行了 dict_equip
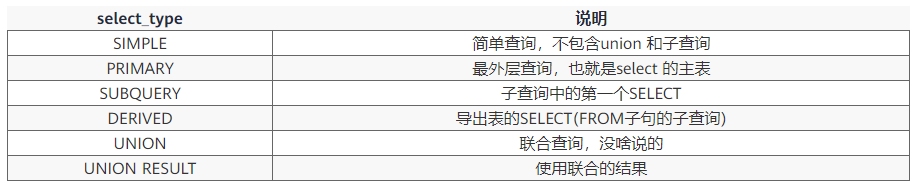
2、select_type select 的类型
3、table 查询涉及的表或衍生表
当前输出的正在使用的表,可以有下面几种:
<unionM,N> : 行数据是联合之后的数据id 处于 m和 n
<derived*N*>: 衍生表
<subqueryN>: 子查询
4、partitions 查询涉及到的分区
在使用分区表的时候才能用到,暂时没用到过这种高级功能。
5、type 查询的类型
表示MySQL在表中找到所需行的方式,又称“访问类型”,常见类型如下:
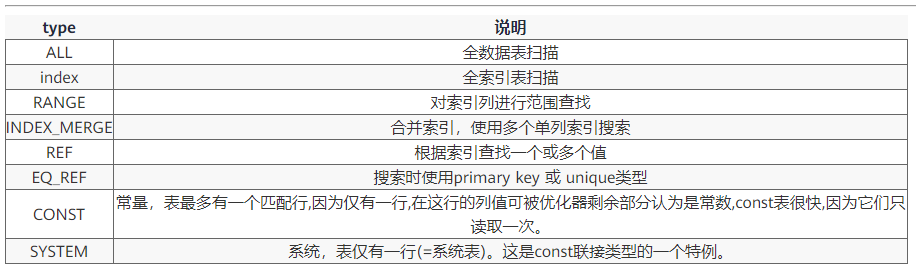
性能:all < index < range < index_merge < ref_or_null < ref < eq_ref < system/const
由左至右,由最差到最好
在进行优化的时候如果查询出的数据量大的话可以使用全表扫描,避免使用索引。
如果只是查询很少的数据尽量使用索引。
6、possible_keys:预计可能使用的索引
在不和其他表进行关联的时候,查询表的是可能使用的索引
7、key:实际查询的过程中使用的索引
显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL
8、key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度
9、ref 显示该表的索引字段关联了哪张表的哪个字段
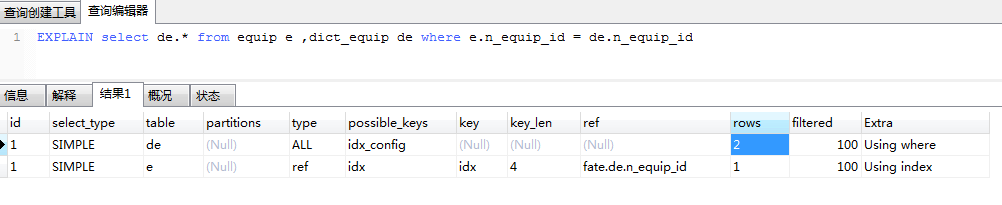
注: 我在equip 和 dict_equip 两张表都分别添加了索引,索引列是n_equip_id
通过上面的执行计划可以看出,首先使用了索引
10、rows:根据表统计信息及选用情况,大致估算出找到所需的记录或所需读取的行数,数值越小越好
比如 一个列上 虽然没做索引,但是都是唯一的,这个时候查找的时候如果是全表读取,就是表里有多少数据这个值就是多少,这个时候你需要优化的就是尽可能的读取少的表,可以增加索引,减少读取行数
11、filtered:返回结果的行数占读取行数的百分比,值越大越好
比如全表有100条数据,可能读取了全表数据,但是只有一条匹配上,这个时候百分比就是1,所以你需要让这个比例越大越好,也就是读到的数据尽量都是有用的,避免读取不用的数据,因为IO是很费时的。
12、extra
常见的有下面几种
use filesort:MySQL需要额外的一次传递,以找出如何按排序顺序检索行,如果是这个值,应该优化索引。
use temporary:为了解决查询,MySQL需要创建一个临时表来容纳结果。典型情况如查询包含可以按不同情况列出列的GROUP BY和ORDER BY子句时。
use index:从只使用索引树中的信息而不需要进一步搜索读取实际的行来检索表中的列信息。当查询只使用作为单一索引一部分的列时,可以使用该策略
use where:where子句用于限制哪一行
















 322
322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









