







Identifying facial phenotypes of genetic disorders using deep learning 翻译
原文链接
一作单位以色列特拉维夫大学。

1. 摘要
- 遗传病影响8%的人口,临床遗传病专家可以通过面部特征识别。
- 当前的技术可以识别少数几种,必须考虑几百种。
- Deep Gestalt面部图片分析框架在三个初级实验超过专家。
- 其中两个识别特定的病,一个区分不同基因亚型。
- 91% Top-10 Accuracy。
- 502张图测试,17000张图训练,代表200多种遗传病。社区驱动的分型平台。
- 可用于临床遗传学,基因测试,研究和精准医疗
2. 方法概要
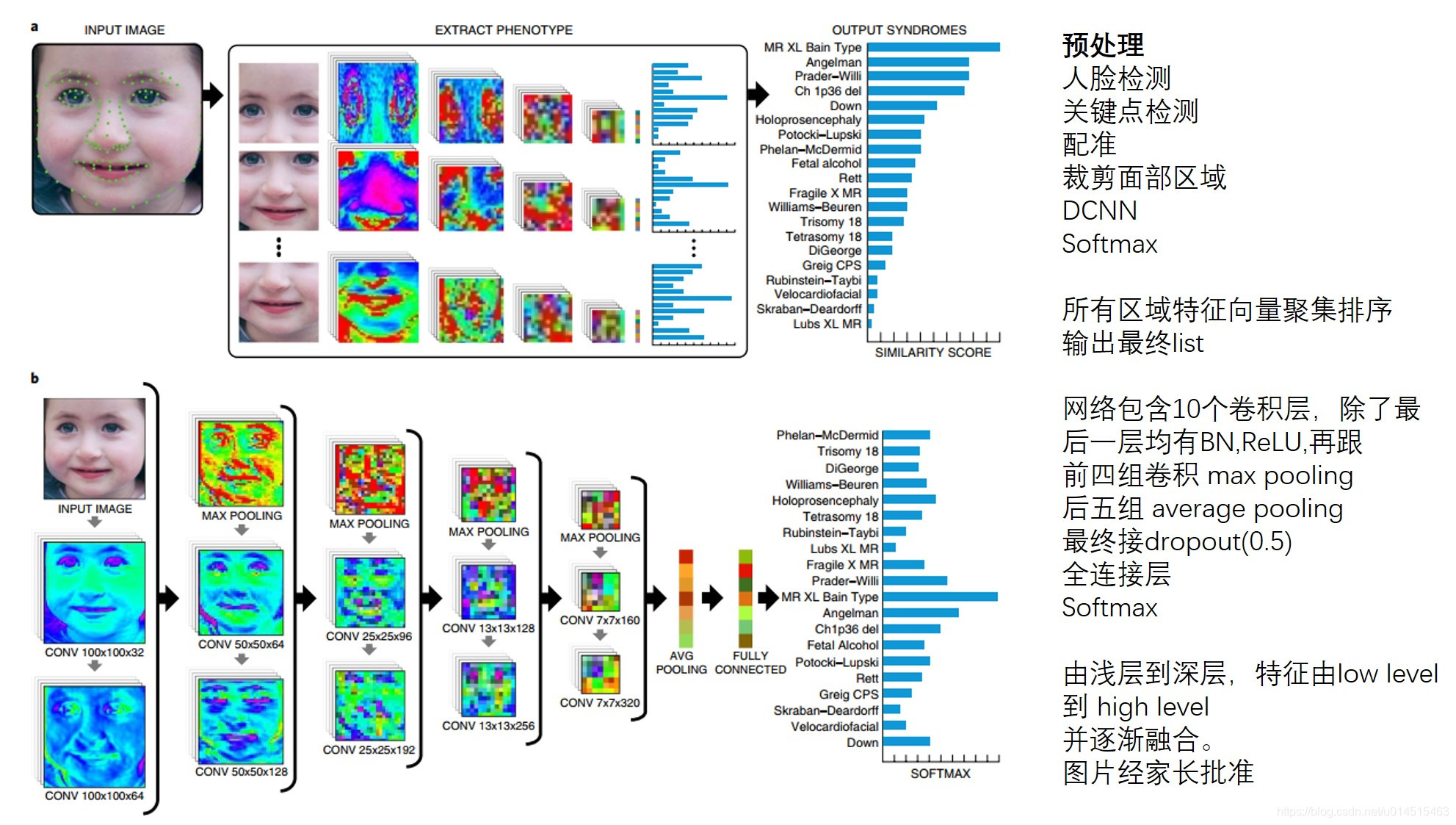
3. 临床背景
-
诊断耗时越长,结果越好。 有大量种类的遗传病,而每种又比较稀少。获得正确诊断需要又长又贵的检查。识别非典型的表征或者最稀有的种类受限于单个专家的先验知识。所以计算机辅助诊断很重要。
-
主要的研究关注区分不受个人影响的或者通过照片识别少数几类
而不是关注真实世界的临床问题,即从不受限制的图片中识别几百种遗传病。
已有的研究使用小规模数据训练,200张左右,只能时小的深度学习模型。没有公开的基准存在。比较多种方法的性能或者准确率比较重要。 -
提出Deep Gestalt。基于Face2Gebe, 从上万张病人图片中训练,区分上百种症状。直接使用DCNN分类,基于从邻近域的知识迁移方法。测试集来源于临床或者出版物。3个实验证明结果优于人类专家。
4.实验和结果
输入图片,检测人脸和关键点,几何校正,剪切成不同区域,调整到100X100, 转成灰度,经过DCNN得到分型概率。先在公共人脸数据集上训练,然后迁移到遗传病领域,通过经验证的病人图片。包含top-1, top-5 ,top-10 accuracy。Top-10 accuracy 强调该工具用于参考,所有类型都考虑。 每种都报告 95%置信区间以及P-value
4.1 两个二分类实验
| 实验一 | 实验二 | |
|---|---|---|
| 对象 | CdLS (多毛发育障碍综合征)检测 | 天使综合征检测 |
| 训练数据 | 614张 CdLS (多毛发育障碍综合征)综合征图片。1079张其他类型作为阴性群 | 766天使图片作为阳性2669图片作为阴性群组 |
| 测试 | 23张CdLS ,9个非CdLS病人 | 10 天使综合征病人,15个其他病人 |
| 结果 | Accuracy 96.88% sensitivity 95% specificity 100%(Top1 Acc ) | Acc 92% sensitivity 80% specificity 100% |
| 总体比例检验来计算显著性水平P值 | 0.01和0.22对应DeepGestalt方法和Basel-Vanagaite方法 | P=0.05 |
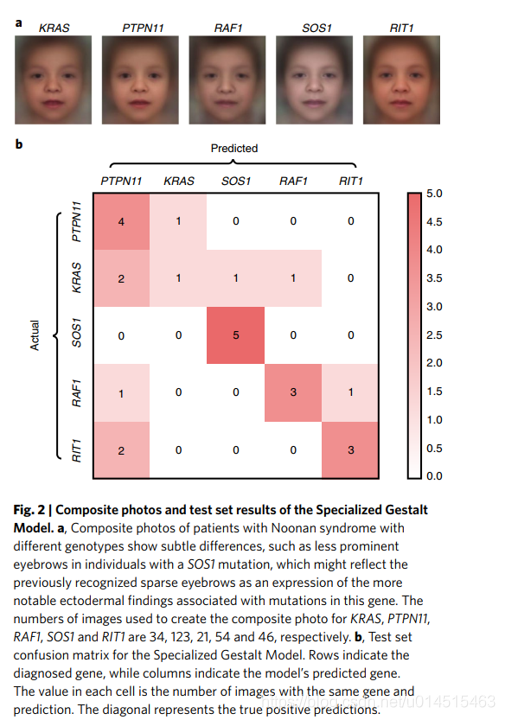
4.2 特殊Gestalt 模型,区分相同综合征下的不同基因型
- 本模型可能面临小规模问题,每个群组只有少量图片。
目标在于区分由影响相同表达通道的不同突变引起的异质综合征的分子亚型(太专业可能理解的不对) - 检验Gestalt模型是否再相似任务中性能更佳。
即 使用278张 NOOnan综合征图片(从文章和临床数据中收集来) 分了PTPN11等5个亚型 - 测试集25张图片,每种类别5张,不在训练集
从公开发表的文章中收集来 - 特殊G模型是阉割版的DeepG模型,输出5种亚型
Top-1 ACC 64% 这个有点低啊,数据也太少了。
随机分类得有20%. P值低于10^-5
4.3 DeepG模型面部分型大规模分析
大数据集 17106张图片, 区分216种综合征
2个测试集:
临床测试集 502张病人图片(临床专家提供和解决)
公开数据集 329张病人图片 London Medical Databases
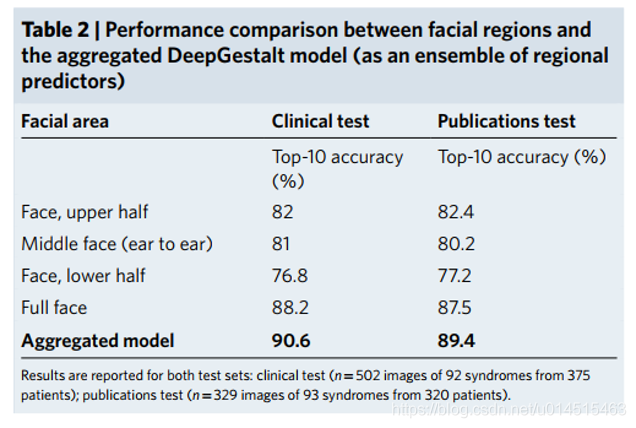
通过聚合面部区域提高性能和鲁棒性(就是测试时随机裁剪多一些图片)
聚合模型性能高于分开测试
Top-10 Accuracy 90.6% 临床数据
89.4% 公开数据
Top-5 85.4% Top1 61.3% 临床数据
83.2% 68.7% 公开数据
5. 讨论
总结
- 提出面部分析框架来用于遗传综合征分类 ,名为DeepGestalt
- 利用深度技术和大规模数据学习面部表征
迁移学习(大规模人脸识别数据集) - 解决不同问题
- 性能超过人类专家,可以在子集上优化
可以用来分析表型基因型相关性 - Top-10的acc高于90%
- 有很高可能用于临床
- 传统方法依靠独立的临床条例,根据特征语义相似度确定,方法比较主观,依赖临床经验
待提高
- 增加自动面部分析框架到工作流可以达到更好的先验和诊断
- 像其他AI系统, 不能够准确的解释预测结果,不能提供哪个面部特征决定了分类
- 通过梯度反向传播得到的热度图可以看出单张图片的拟合程度
- 可能计算130个关键点的比例,如眼角距离等,提高性能
局限性
- 该系统的使用的假设基于病人有一些症状,通过一些科学的问题可以确定是否有遗传疾病
- 本报告的结果仅限于特定的综合征的病人
不能迁移到including unaffected individuals 的测试集 - 一些实验中缺少和其他方法的比较或者人类专家的比较
在二值实验中,建立了小的benchmarks.
使用了25到32张图片
测试集开源。
下一代表型分析技术,DeeGestalt, 类似于基因数据。
表型数据也是敏感的病人信息,此前讨论基于非基因歧视行动免于指控。不同于基因数据,人脸数据便于获取
雇主可能通过分析分析面部图像判断既往病史或者发生医学病症带来对个人的歧视
对滥用的有效监管政策包括通过区块链技术获取额外的数字指纹应用于DeepGestalt
在标准流程中增加的描述表型能力可以通过匹配未定义病人的相似表征来确定新的基因表型。
确信通过整合基因序列分析来进行自动表型分析可以提高先验知识和对结果提供可解释性,或许是精准医疗的关键
6. 方法
-
伦理声明: 作者确定人类学研究者提供了公开这些图片的许可通知书
-
研究许可:
该研究经IRB协会批准: NCHS,等等... 作者获得了病人的同意,根据对应的IRB适用
7. DeepGestalt背后的技术
包括:
1.图像预处理流程,2.表型提取和综合征分类方法,3.数据集,4.训练细节,5.评估和统计分析。
数据采集
面部数据在病人看病时由临床医生通过商业相机采集,通常为智能机摄像头(这个。。。。),没有特殊的硬件。
随后上传,图像质量标准为是否能检测到正脸
从端到端的观点看,我们的目标是为了得到一个函数Fx,
从输入图片x映射到基因表型列表,即得到对性的相似度分数。通过排序,综合征列表靠前的也就算最相似的表型
7.1 图像预处理流程
为了应对真实世界无控制的2D图片,第一步就是检测病人的脸。
真实临床图片具有大的差异,如人脸大小,姿势,表情,背景,遮挡和光照。
所以需要一个鲁棒的人脸检测器来识别可靠的正脸,
我们采用深度学习方法,基于级联DCNN在非控制环境下检测人脸。
然后由粗略到精细的多步骤检测130个关键点(landmarks)
然后对脸和关键点进行几何标准化。(标准化脸的姿态差异减小,这方法会提高人脸识别性能)
接下来使用区域生成器,即产生多个预定义的ROI区域。(包括全脸裁剪,和具有区分度的区域,即包括眼睛,嘴唇,鼻子等)
最后一步为将每个区域Resize到100X100, 然后转为灰度
7.2 表型(Phenotype)提取和 综合征分类
DeeGestalt使用DCNN, 属于机器学习技术的一种,包括相互链接的数据单元,称为神经元。每个神经元都有自己的特殊知识(knowledge),也和其他神经元分享信息。神经元按输入到输出一层层叠起啦,每层的输出就是下一层的输入。
一般来说每层后面都会有非线性步骤(sigmoid函数)。靠近输入的层提取低层信息,如边和角;靠近输出的汇聚前面层的信息得到更复杂的特征。
这种结构使得网络可以从输入中获得特殊的目标函数。每层的参数(权重)都是随机初始化,然后随着训练数据样本更新。步骤重复直到收敛(尤其是采用反向传播算法)。给定足够大且有足够差异的训练数据,网络学习具有泛化能力的模型来用于测试图片,测试图片的标签是未知的。
DCNN中一些层在输入上进行卷积操作,这是从图片中提取信息的有效方法。
为了降低我们这个特殊问题的主要挑战,类别不平衡的小训练数据集。我们训练分两步,1是学习普通的人脸表征,然后微调到本分类任务。
为了学习基础的人脸表征,我们在大规模人脸识别数据集上训练DCNN。基础结构基于前文。在每个人脸块上单独训练。最后将训练的模型合在一起构成鲁棒的人脸表征。
一旦得到了综合的人脸表观模型
我们就在每个更小规模的表型数据集上微调
这个步骤一般就像在源域和目标域之间的迁移学习
获得的人脸识别模型不是用来识别个体,而是用于区分不同遗传综合征
使用不同的面部区域作为集成的分类器。每个区域对应的DCNN分别给出预测结果,最后取平均,产生一个多类问题的鲁棒模型
在真正的临床使用中,病人的图片不会使用前面描述的处理流程。输出的向量是一组排序的相似度分数,指明病人照片和每种支持的综合征之间的相关性
为了更好的理解模型的预测,我们醉了热度图来表征输入图像和选择的综合征之间的空间相关性。这通过从特定DCNN的输出的信息反向传播,并可视化对应特定综合征的最相关的面部区域
7.3 数据集
为了训练人脸识别模型,采用了公开的CASIA WebFace数据集(中科院自动化所)。包含494414张图片,10575个不同主体,经配准
放缩,裁剪。为了微调网络以获取表型信息,我们使用上传在Face2Gene上的包含面部图片临床数据
在该数据集上,病例的诊断基于用户的标注,进一步的诊断验证由于严格的隐私规则无法获取。
为了训练,我们使用了数据集快照,支持216种不同综合征
使用17106张图片,其中包含10953个主体(平均每个人1.56张图片。中值为1)。由当前完整数据集得到。
我们仅使用那些经相关健康专家基于临床或者分子的诊断的病例。
自动排除那些低分辨率和检测不到正脸的图片。数据集可能有标注错误,但是我们相信DeepG框架能够在训练集有错误的情况下泛化的很好。我们假设出现这样的错误的可能性很小,不会对学习到的模型带来大的偏差。其他深度学习的发表的文献也支持类似的偏差假设(bias)。
-为了系统的评估,我们建立了两个测试集:
-
临床数据集。
在一段时间内,我们采集了所有在Face2Gene中被诊断为任何一种DeepGestalt支持的综合征的病例
我们移除了训练集的部分并忽略了复制的图片
为了和临床使用保持一致,我们没有基于年龄或者种族来排除(一些图片)
在建立该测试集的时候,我们保证每个病人所有的图片要么在训练集,要么在测试集。(怎么保证?)我们最终收集了包括92种不同综合征的502张图片。测试集向着十分稀有的综合征倾斜,65%的综合征出现在1到5张图片。35%的综合征各有6到42张图片。
最终,中值为4,均值为每种5.45张
病人和综合征的分布反应了稀有综合征的普遍性,因此是一个应用于基因咨询的有代表性的测试集。 -
公开数据集
包含93种综合征的329张图片的新测试集
经London Medical Database的同意发表。
为了创造高质量的测试集,我们在完整的伦敦医学数据集上上万的图片中使用了一系列的数据清洗操作。
我们排除了没有前脸的图片,质量不好的图片,或者年龄1岁以下,18岁以上的,还有病人被遮挡的图片(如戴眼镜的)
在该测试集中,80%的综合征只出现了1到5张图片。20%的综合征有超过6张,中值为2,均值为3.54
为了遵从高的安全标准和隐私标准,我们还使用了一种全自动的操作系统。在用户上传的相同环境下对图片进行处理,以保证图片的安全和隐私。为了评估性能,只报告了最终结果
7.4 训练细节
对每个面部区域,我们都使用大规模人脸识别数据集训练一个人脸识别的DCNN。
训练数据随机分为90%训练,10%验证。
随后在基因综合征分类任务上微调。
DCNN结构类似于2015CVPR,有一些修改包括增加BN层
使用Keras训练,TensorFlow后端。Baseline基于He初始化权重(结果优于其他方法)
采用Adam优化,初始化学习率0.001/。 使用交叉熵损失函数。40 epochs之后,继续按照1e-4学习率训练10次,这时使用SGD优化,带动量0.9
在微调中,将最后的输出层换成和综合征数量匹配的层数。我们发现,微调层的初始化特别重要,最好的结果在采用修改版Xavier初始化时获得。我们采用了不同的系数(scale)做实验,最好的结果系数为0.3
微调优化器为SGD, 学习率5e-3. 动量0.9 . 没有kernel正则化,或者权重衰减, 在初始结构中增加BN层和dropout(0.5),性能更好。
数据增强十分重要。每个区域在5°内随机旋转, 0.05的垂直水平偏移,剪切变换(5?/180),随机放缩(0.05范围),水平翻转。没有增强时,训练很快过拟合,尤其在非完整脸的区域上
7.5 评估和统计分析
在二分类实验中,我们使用top-1 acc评估模型性能。同时计算敏感度和特异度。通过总体分布测试(population proportions test)评估与人类预测结果的统计显著性。
在多分类问题中,我们计算top-K acc,其中k分别为1,5,10.(总类别 216)
[测试集一共就90多种,是如何评估200多种的准确率呢]
为了对类别不平衡的数据进行显著性检验,进行置换测试(permutation test)
所有值均在95%置信区间内,通过百分位引导方法计算percentile bootstrap
对于二分类问题,在和专家的结果相比较或者与已有研究比较时, 我们通过双边总体比例测试计算P值(two-sided population proportionstest ),从而评估统计显著性
该测试衡量两个比例(proportions)在单个二值特征上的差异。测试结果为Z-score和P值,其接受零假设显著性检验
数据和代码均不开源























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











