







分区管理
前面几章我们说到Rabbitmq存储消息的时候使用的是内存和磁盘的方式进行存储,而Kafka消息被持久化到本地磁盘。按照我们的理解Rabbimtq的消息吞吐量应该大于Kafka的消息吞吐量,但是相反Rabbitmq的消息吞吐量反而小于Kafka的,那么为什么呢?
Kafka可以将主题(Topic)划分为多个分区(Partition),会根据分区规则选择把消息存储到哪个分区中,只要分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡和水平扩展。另外,多个订阅者可以从一个或者多个分区中同时消费数据,以支撑海量数据处理能力。顺便说一句,由于消息是以追加的方法存储到分区中的,多个分区顺序写磁盘的总效率要比随机写内存还要高(引用Apache Kafka – A High Throughput DistributedMessaging System的观点),是Kafka高吞吐率的重要保证之一。
分区副本机制
由于Producer和Consumer都只会与Leader角色的分区副本相连,所以kafka需要以集群的组织形式提供主
题下的消息高可用。kafka支持主备复制,所以消息具备高可用和持久性。
一个分区可以有多个副本,这些副本保存在不同的broker上。每个分区的副本中都会有一个作为Leader。当一个broker失败时,Leader在这台broker上的分区都会变得不可用,kafka会自动移除Leader,再其他副本中选一个作为新的Leader。在通常情况下,增加分区可以提供kafka集群的吞吐量。然而,也应该意识到集群的总分区数或是单台服务器上的分区数过多,会增加不可用及延迟的风险。
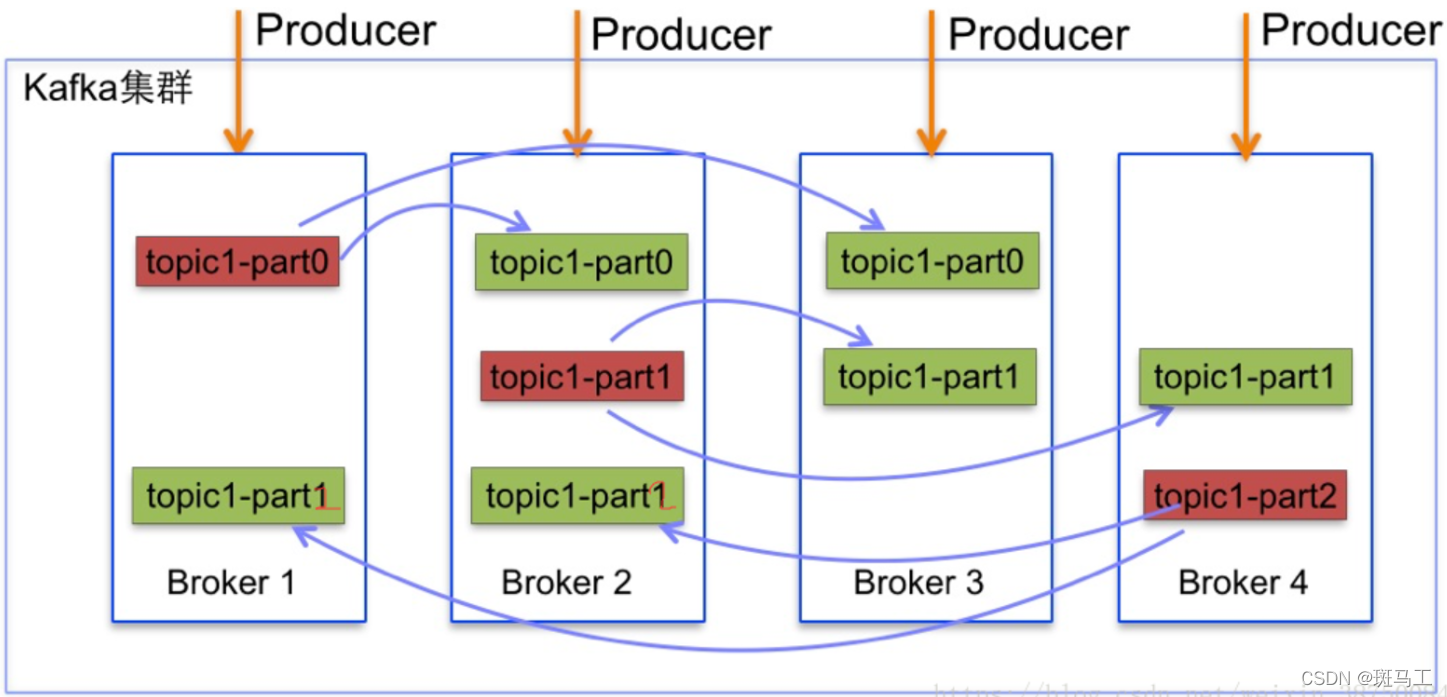
可以通过如下命令查看某一个主题的分区情况:
bin/kafka-topics.sh --zookeeper 172.19.0.60:2181 --describe --topic dd
Topic: itheima PartitionCount: 3 ReplicationFactor: 1 Configs:
Topic: itheima Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: itheima Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: itheima Partition: 2 Leader: 0 Replicas: 0 Isr: 0
注:Leader和Replicas以及Isr中的数字表示的是broker的标号
分区leader选举
可以预见的是,如果某个分区的Leader挂了,那么其它跟随者将会进行选举产生一个新的leader,之后所有的读写就会转移到这个新的Leader上,在kafka中,其不是采用常见的多数选举的方式进行副本的Leader选举,而是会在Zookeeper上针对每个Topic维护一个称为ISR(in-sync replica,已同步的副本)的集合,显然还有一些副本没有来得及同步。只有这个ISR列表里面的才有资格成为leader(先使用ISR里面的第一个,如果不行依次类推,因为ISR里面的是同步副本,消息是最完整且各个节点都是一样的)。通过ISR,kafka可以容忍的失败数比较高。
假设某个topic有f+1个副本,kafka可以容忍f个不可用,当然如果全部ISR里面的副本都不可用,也可以选择其他可用的副本,只是存在数据的不一致。
分区重新分配
我们往已经部署好的Kafka集群里面添加机器是最正常不过的需求,而且添加起来非常地方便,我们需要做的事是从已经部署好的Kafka节点中复制相应的配置文件,然后把里面的broker id修改成全局唯一的,最后启动这个节点即可将它加入到现有Kafka集群中。但是问题来了,新添加的Kafka节点并不会自动地分配数据,所以无法分担集群的负载,除非我们新建一个topic。但是现在我们想手动将部分分区移到新添加的Kafka节点上,Kafka内部提供了相关的工具来重新分布某个topic的分区。
具体的实现步骤如下所示:
1、比如某一个主题的分区信息如下所示:

2、给某一个分区在添加一个新的分区
bin/kafka-topics.sh --alter --zookeeper 172.19.0.61:2181 --topic itcast --partitions 4
添加完毕以后,分区的信息如下所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2439
2439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











