







 前言本文基于http服务器实现(一)来完成http报文解析部分。 涉及到的内容有:http协议格式状态机变迁字符串解析服务器源码客户端源码和测试结果一、http协议这一节的重点是解析http报文,那么首先我们必须知道http协议格式。针对协议字段,本节程序并不涉及到每个字段的含义,只是简单的把这些字段分隔开来,后续需要深入理解这些字段的含义才能进一步实现服务器的处理流程。这里简单介绍h
前言本文基于http服务器实现(一)来完成http报文解析部分。 涉及到的内容有:http协议格式状态机变迁字符串解析服务器源码客户端源码和测试结果一、http协议这一节的重点是解析http报文,那么首先我们必须知道http协议格式。针对协议字段,本节程序并不涉及到每个字段的含义,只是简单的把这些字段分隔开来,后续需要深入理解这些字段的含义才能进一步实现服务器的处理流程。这里简单介绍h
前言
本文基于http服务器实现(一)来完成http报文解析部分。
涉及到的内容有:
- http协议格式
- 状态机变迁
- 字符串解析
- 服务器源码
- 客户端源码和测试结果
一、http协议
这一节的重点是解析http报文,那么首先我们必须知道http协议格式。针对协议字段,本节程序并不涉及到每个字段的含义,只是简单的把这些字段分隔开来,后续需要深入理解这些字段的含义才能进一步实现服务器的处理流程。这里简单介绍http报文格式。
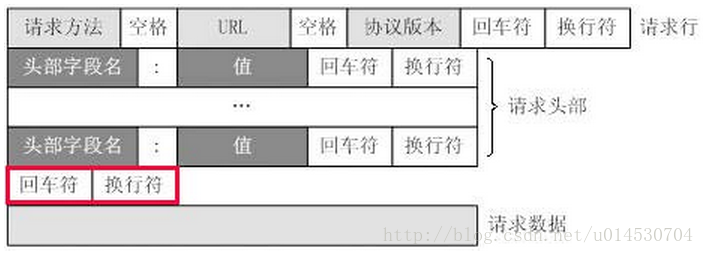
一个http报文由请求行、请求头部、空行、请求正文四部分组成,如下图:
抽象的东西一般比较难理解,这里我用抓包工具抓了http的请求报文和响应报文。
http请求报文:
GET /adsid/integrator.js?domain=fragment.firefoxchina.cn HTTP/1.1
Host: adservice.google.com
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0
Accept: */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Referer: http://fragment.firefoxchina.cn/html/mp_google_banner_20171122v1.html
Connection: keep-alive
Pragma: no-cache
Cache-Control: no-cache
以上http报文,我们对照着前面的图片,很容易可以看出请求行为:GET /adsid/integrator.js?domain=fragment.firefoxchina.cn HTTP/1.1,请求行由请求方法、URL字段和http协议版本字段组成,它们之间用空格隔开。请求头部由key/value键值对组成,每行一对,key和value之间用冒号”:”分隔。注意,必须在其后加上回车符和换行符”\r\n”标识。最后一个请求头之后是一个空行,字符为回车符和换行符”\r\n”,用于标识请求头的结束。空行下面则是请求正文。请求数据不在GET方法中使用,而是在POST中使用。上面GET的报文中无请求数据。
以下为http响应报文,可以看出和请求报文的格式差不多,由响应行、响应头部、空行、响应数据组成。 因为在本节中不需要返回http响应报文,现阶段暂不讨论这些,等以后用到了会再说明。
http响应报文:
HTTP/1.1 200 OK
P3P: CP="This is not a P3P policy! See http://support.google.com/accounts/answer/151657 for more info."
Timing-Allow-Origin: *
Cache-Control: private, no-cache, no-store
Content-Type: application/javascript; charset=UTF-8
X-Content-Type-Options: nosniff
Content-Disposition: attachment; filename="f.txt"
Date: Fri, 29 Dec 2017 03:40:54 GMT
Server: cafe
X-XSS-Protection: 1; mode=block
Alt-Svc: hq="googleads.g.doubleclick.net:443"; ma=2592000; quic=51303431; quic=51303339; quic=51303338; quic=51303337; quic=51303335,quic="googleads.g.doubleclick.net:443"; ma=2592000; v="41,39,38,37,35",hq=":443"; ma=2592000; quic=51303431; quic=51303339; quic=51303338; quic=51303337; quic=51303335,quic=":443"; ma=2592000; v="41,39,38,37,35"
Content-Length: 108
processGoogleToken({
"newToken":"NT","validLifetimeSecs":0,"freshLifetimeSecs":3600,"1p_jar":"","pucrd":""});二、状态机变迁
服务器读取HTTP头部采用的是状态机,下面来看看代码大致怎么实现。
//解析http头。参数buff为客户端传来的字符串,len为字符串的长度。成功返回0。
int header_parse(char *buff, int len)
{
char *check = buff; //指向要解析的字符串
int status = READ_HEADER;//状态机的标志位
int parse_pos = 0;//表示解析过的字节数
while (check < (buff + len)) {
//一直解析到http请求头结束
switch (status) {
case READ_HEADER:
if (*check == '\r') {
status = ONE_CR;
line_end = check;
} else if (*check == '\n') {
status = ONE_LF;
line_end = check;
}
break;
case ONE_CR:
if (*check == '\n')
status = ONE_LF;
else if (*check != '\r')
status = READ_HEADER;
break;
case ONE_LF:
/* if here, we've found the end (for sure) of a header */
if (*check == '\r') /* could be end o headers */
status = TWO_CR;
else if (*check == '\n')
status = BODY_READ;
else
status = READ_HEADER;
break;
case TWO_CR:
if (*check == '\n')
status = BODY_READ;
else if (*check != '\r')
status = READ_HEADER;
break;
default:
break;
}
parse_pos++; //更新解析字节数
check++; //更新解析位置
//解析到"\r\n"后进入
if (status == ONE_LF) {
//以"\r\n"分隔开的认为是一行,这里将进行请求头一行的读取和处理
} else if (status == BODY_READ){
//这里将进行http请求正文的读取和处理
//处理部分省略。。。。。。
PARSE_HEAD_OPTION = 0;//解析完请求头部之后置0,为下一个客户端做好准备。
return 0;
}
}
return 0;
}以上程序,是对HTTP头的每个字节逐一进行解析,状态机流程如下:
一开始状态标志status为READ_HEADER
- 如果收到“\r”切到ONE_CR 态
- 如果收到“\n”则切为 ONE_LF,每次状态为ONE_LF时,则对请求头进行解析。
当status为ONE_CR时
- 如果收到“\n”则切为 ONE_LF 态
- 如果收到“\r”则切为初始态 READ_HEADER
当status为ONE_LF态时
- 如果收到“\r”则切为 TWO_CR 态
- 如果收到“\n”则收到两个换行符,此时后面内容为HTTP BODY,切为BODY_READ态
- 如果收到其他字符,切回初始态READ_HEADER
当status为TWO_CR态时
- 如果收到“\n”则表示已经收到两个“\r\n”,后面内容为BODY,则切为BODY_READ态
- 如果收到“\r”则切为初始态BODY_READ
每次状态为ONE_LF时,将对http请求头进行解析,主要是涉及到了字符串的解析。下面将对字符串解析进行说明。
三、字符串解析
字符串解析分为两部分,一部分是HTTP请求行的解析,另一部分是HTTP请求头部的解析。我们先来看请求行的解析,代码如下:
//函数主要用来解析HTTP请求行,参数buff指向HTTP请求行开始的位置,成功返回0,失败返回-1
int process_logline(char *buff)
{
static char *SIMPLE_HTTP_VERSION = "HTTP/0.9";
int method;//用于获取http请求行的方法,GET或HEAD或POST
char request_uri[MAX_HEADER_LENGTH + 1]; // 用于获取客户端请求的uri
char *http_version = SIMPLE_HTTP_VERSION;
char *stop, *stop2;
char *logline = buff;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









