







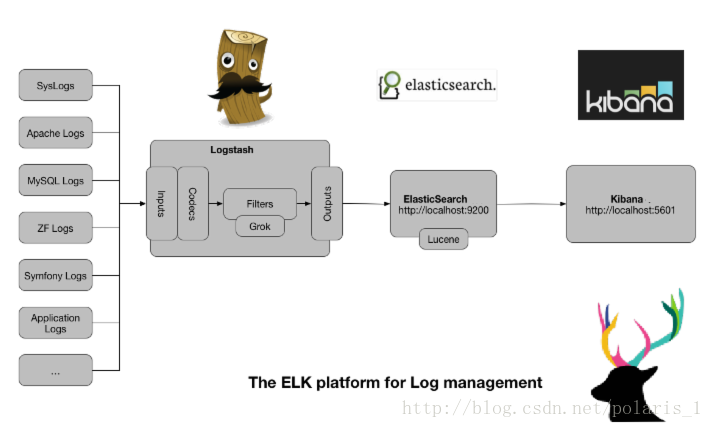
以往的日志都是一台台tomcat去找,如果是日志是位于多台服务器的多个多台tomcat,那么需要对日志进行追溯将是一场灾难,要一台台服务器去找,而且要从头到尾去找自己所需要的信息,碰巧老大说项搞一个日志搜集系统,所有的log集中管理。方便追踪错误。
核心思想:
spring的aop切面负责产生数据,也就是数据源(也可以直接通过logstash读取log文件)
kafka 消息队列来做数据缓冲以及异步传输
logstash 负责收集来自kafka的指定主题消息,并负责格式化,传输到es里
es 获取来自logstash的数据,并按照日期创建索引,数据存储,方便搜索(近实时搜索,方便查询日志)
kibana 负责对es的数据进行图形化界面的展示(kibana可以做很多很炫的报表展示)
参考文档:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
先从软件安装开始
es
环境
操作系统:centos 7.0
jdk版本:jdk1.8.0_121
应用版本:Elasticsearch 5.3.2
jdk安装步骤省略,网上资料多得是,这里就不多提了
1、解压文件并且放到指定目录,具体情况因人而异
解压:unzip elasticsearch-5.3.2.zip
进入目录:cd /usr/local/elasticsearch-5.3.2/
2、用户组和用户创建,elasticsearch不能使用root启动,因此需要创建其他用户来启动
创建用户组
groupadd elsearch
创建用户到指定用户组
useradd -g elsearch elsearch
然后设置目录为elsearch 用户所属
chown -R elsearch:elsearch /usr/local/elasticsearch-5.3.2
mkdir -p /var/elasticsearch/data/
mkdir -p /var/elasticsearch/logs/
chown -R elsearch:elsearch /var/elasticsearch/data/
chown -R elsearch:elsearch /var/elasticsearch/logs/
3、设置系统的相关参数,如果不设置参数将会存在相关的问题导致不能启动
配置系统最大文件数
vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
内存太小需要修改
vi /usr/local/elasticsearch-5.3.2/config/jvm.options
将-Xmx2g改成-Xmx512m
将-Xms2g改成-Xms512m
-Xms512m
-Xmx512m
调整虚拟内存最大map数量,默认是65536,调整最大的文件数量
vi /etc/sysctl.conf
在文件最底下增加:
vm.max_map_count=262144
fs.file-max=65536
使生效并查看值:sysctl -p
(4)启动elasticsearch
修改配置文件:vi /usr/local/elasticsearch-5.3.2/config/elasticsearch.yml
配置下面参数,根据实际情况配置
#集群名
cluster.name: my-application
#节点名
node.name: node-1
#数据存储路径
path.data: /var/elasticsearch/data
#日志存储路径
path.logs: /var/elasticsearch/logs
#本机IP
network.host: 118.178.90.208
#端口号
http.port: 9200
#集群节点IP集合
discovery.zen.ping.unicast.hosts: ["118.178.90.208", "106.14.77.86"]
如果报如下错误
max file descriptors [65535] for elasticsearch process likely too low, increase to at least [65536]
ulimit -n 65536
启动程序
切换到设置的用户:su elsearch
启动:/usr/local/elasticsearch-5.3.2/bin/elasticsearch -d
(5)验证有没有启动成功:curl -XGET 'http://118.178.90.208:9200/_cluster/health?pretty',返回下面信息说明启动成功
{
"cluster_name" : "my-application",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
logstash
#logstash安装
#安装jdk1.8环境
...略
#上传logstash-5.4.0.tar.gz
#解压
tar -zxvf logstash-5.4.0.tar.gz -C /usr/local/
#配置参数
input {
kafka {
bootstrap_servers => "IP:9092"
topics => "systemlog"#日志的topic
group_id => "systemlog-g1"#kafka组id
}
}
output {
elasticsearch {
hosts => ["IP:9200"]
index => "logstash-%{type}-%{+YYYY.MM.dd}"#按照日期建立索引文件
flush_size => 20000
idle_flush_time => 10
template_overwrite => true
}
}
bootstrap_servers => "IP:9092"
topics => "systemlog"#日志的topic
group_id => "systemlog-g1"#kafka组id
}
}
output {
elasticsearch {
hosts => ["IP:9200"]
index => "logstash-%{type}-%{+YYYY.MM.dd}"#按照日期建立索引文件
flush_size => 20000
idle_flush_time => 10
template_overwrite => true
}
}
kibana安装
kibana5的安装
上传kibana-5.4.0-linux-x86_64.tar.gz
tar -zxvf kibana-5.4.0-linux-x86_64.tar.gz -C /usr/local/
vim /usr/local/kibana-5.4.0-linux-x86_64/config/kibana.yml
```
server.host: "192.168.1.101"
elasticsearch.url: "http://192.168.1.101:9200"
```
启动:
nohup /usr/local/kibana-5.4.0-linux-x86_64/bin/kibana -c /usr/local/kibana-5.4.0-linux-x86_64/config/kibana.yml > /dev/null 2>&1 &
安装kafka先安装zk,zk的安装网上有很多例子我就不多提了
下面是步骤
参考:https://www.cnblogs.com/unqiang/p/5166770.html
参考:https://blog.csdn.net/chenshijie2011/article/details/75670126
vi kafkastart.sh #编辑,添加以下代码
#!/bin/sh
#启动zookeeper
/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties &
#等3秒后执行
sleep 3
#启动kafka
/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
vi kafkastop.sh #编辑,添加以下代码
#!/bin/sh
#关闭zookeeper
/usr/local/kafka/bin/zookeeper-server-stop.sh /usr/local/kafka/config/zookeeper.properties &
#等3秒后执行
sleep 3
#关闭kafka
/usr/local/kafka/bin/kafka-server-stop.sh /usr/local/kafka/config/server.properties &
chmod +x kafkastart.sh
chmod +x kafkastop.sh
五、设置脚本开机自动执行
vi /etc/rc.d/rc.local #编辑,在最后添加一行
sh /usr/local/kafka/kafkastart.sh & #设置开机自动在后台运行脚本
:wq! #保存退出
sh /usr/local/kafka/kafkastart.sh #启动kafka
sh /usr/local/kafka/kafkastop.sh #关闭kafka
至此,Linux下Kafka单机安装配置完成。
扩展阅读:
Kafka创建topic
/usr/local/kafka/bin/kafka-topics.sh --create --zookeeper IP:2181 --replication-factor 1 --partitions 1 --topic systemlog
/usr/local/kafka/bin/kafka-topics.sh --list --zookeeper IP:2181
/usr/local/kafka/bin/kafka-console-producer.sh --broker-list IP:9092 --topic systemlog
/usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server IP:9092 --topic systemlog --from-beginning
然后新建一个spring boot项目打成jar,给所有的项目依赖,我这里使用自定义注解结合AOP切面来处理环绕通知
项目结构图
pom.xml依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>springLog</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springLog</name>
<description>Demo project for Spring Boot</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.3.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<spring.boot.starter.log4j.version>1.3.8.RELEASE</spring.boot.starter.log4j.version>
<fastjson.version>1.1.26</fastjson.version>
<org.codehaus.jackson.version>1.9.13</org.codehaus.jackson.version>
<commonslang.version>2.6</commonslang.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<!--对json格式的支持 -->
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-mapper-asl</artifactId>
<version>${org.codehaus.jackson.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>${commonslang.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.1.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
package com.example.demo;
import java.util.HashMap;
import java.util.Map;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
@Configuration
@EnableKafka
public class KafkaProducerConfig {
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "IP:9092");
// 如果请求失败,生产者会自动重试,我们指定是0次,如果启用重试,则会有重复消息的可能性
props.put(ProducerConfig.RETRIES_CONFIG, 0);
/**
* Server完成 producer request 前需要确认的数量。 acks=0时,producer不会等待确认,直接添加到socket等待发送;
* acks=1时,等待leader写到local log就行; acks=all或acks=-1时,等待isr中所有副本确认 (注意:确认都是 broker
* 接收到消息放入内存就直接返回确认,不是需要等待数据写入磁盘后才返回确认,这也是kafka快的原因)
*/
// props.put("acks", "all");
/**
* Producer可以将发往同一个Partition的数据做成一个Produce
* Request发送请求,即Batch批处理,以减少请求次数,该值即为每次批处理的大小。
* 另外每个Request请求包含多个Batch,每个Batch对应一个Partition,且一个Request发送的目的Broker均为这些partition的leader副本。
* 若将该值设为0,则不会进行批处理
*/
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 4096);//
/**
* 默认缓冲可立即发送,即遍缓冲空间还没有满,但是,如果你想减少请求的数量,可以设置linger.ms大于0。
* 这将指示生产者发送请求之前等待一段时间,希望更多的消息填补到未满的批中。这类似于TCP的算法,例如上面的代码段,
* 可能100条消息在一个请求发送,因为我们设置了linger(逗留)时间为1毫秒,然后,如果我们没有填满缓冲区,
* 这个设置将增加1毫秒的延迟请求以等待更多的消息。 需要注意的是,在高负载下,相近的时间一般也会组成批,即使是
* linger.ms=0。在不处于高负载的情况下,如果设置比0大,以少量的延迟代价换取更少的,更有效的请求。
*/
props.put(ProducerConfig.LINGER_MS_CONFIG, 1);
/**
* 控制生产者可用的缓存总量,如果消息发送速度比其传输到服务器的快,将会耗尽这个缓存空间。
* 当缓存空间耗尽,其他发送调用将被阻塞,阻塞时间的阈值通过max.block.ms设定, 之后它将抛出一个TimeoutException。
*/
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 40960);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<String, String>(producerFactory());
}
}package com.example.demo;
import java.util.Enumeration;
import javax.servlet.http.HttpServletRequest;
import org.apache.commons.lang.StringUtils;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.Ordered;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import com.alibaba.fastjson.JSONObject;
@Aspect
@Component
public class LogInterceptor implements Ordered{
@Autowired
private KafkaTemplate kafkaTemplate;
@Around("@annotation(systemLog)")
public Object Log(ProceedingJoinPoint joinPoint,SystemLog systemLog){
Object retVal = null;
try {
if (joinPoint == null) {
return null;
}
JSONObject message = new JSONObject();
HttpServletRequest request = ((ServletRequestAttributes) RequestContextHolder.getRequestAttributes()).getRequest();
String ip = getIpAddr(request);
//获取方法参数
Enumeration<String> eParams = request.getParameterNames();
while (eParams.hasMoreElements()) {
String key = eParams.nextElement();
String value = request.getParameter(key);
message.put(key, value);
}
//获取header参数
Enumeration<?> headerNames = request.getHeaderNames();
while (headerNames.hasMoreElements()) {
String key = (String) headerNames.nextElement();
String value = request.getHeader(key);
//时间戳单位统一
if ("timestamp".equals(key) && StringUtils.isNotBlank(value) && value.length() > 10) {
value = value.substring(0, 10);
}
message.put(key, value);
}
String requestURL=request.getRequestURL().toString();
message.put("requestURL", requestURL);message.put("class", joinPoint.getTarget().getClass().getName());
message.put("request_method", joinPoint.getSignature().getName());
message.put("ip", ip);
message.put("systemName", "all");
kafkaTemplate.send("systemlog",message.toJSONString());
retVal =joinPoint.proceed();
} catch (Throwable throwable) {
throwable.getMessage();
}
return retVal;
}
public String getIpAddr(HttpServletRequest request) {
String ipAddress = null;
ipAddress = request.getHeader("x-forwarded-for");
if (ipAddress == null || ipAddress.length() == 0
|| "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getHeader("Proxy-Client-IP");
}
if (ipAddress == null || ipAddress.length() == 0
|| "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getHeader("WL-Proxy-Client-IP");
}
if (ipAddress == null || ipAddress.length() == 0
|| "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getRemoteAddr();
}
// 对于通过多个代理的情况,第一个IP为客户端真实IP,多个IP按照','分割
if (ipAddress != null && ipAddress.length() > 15) { // "***.***.***.***".length()
// = 15
if (ipAddress.indexOf(",") > 0) {
ipAddress = ipAddress.substring(0, ipAddress.indexOf(","));
}
}
//或者这样也行,对于通过多个代理的情况,第一个IP为客户端真实IP,多个IP按照','分割
//return ipAddress!=null&&!"".equals(ipAddress)?ipAddress.split(",")[0]:null;
return ipAddress;
}
@Override
public int getOrder() {
return 0;
}
}
package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SpringLogApplication {
public static void main(String[] args) {
SpringApplication.run(SpringLogApplication.class, args);
}
}
package com.example.demo;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface SystemLog {
}
另一个项目引用他打包好的jar
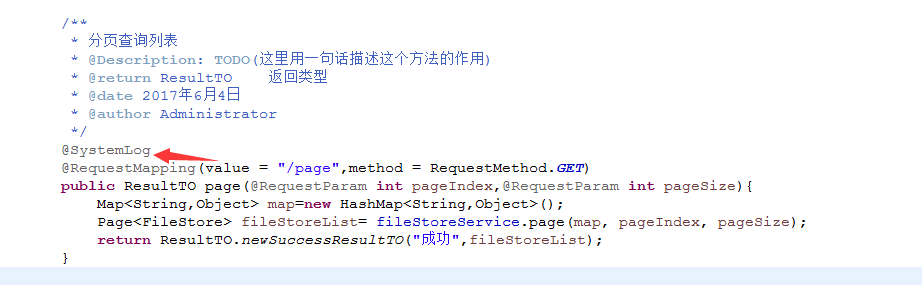
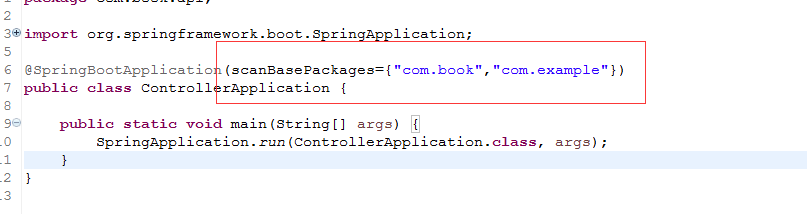
这里一定要加上,因为springboot默认扫描启动类所在的包及其子包的文件,如果是引用其他项目必须手动指定,不然注解无效
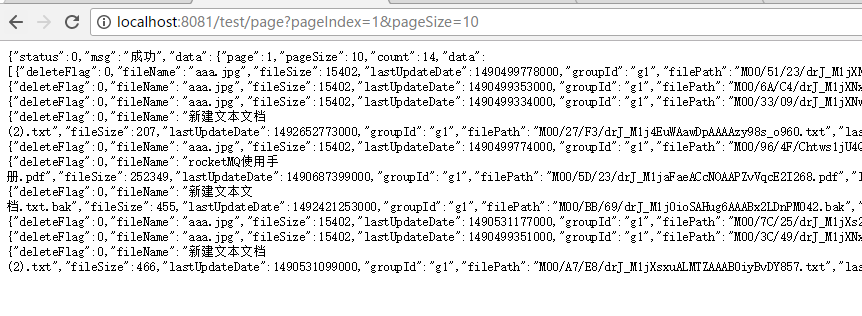
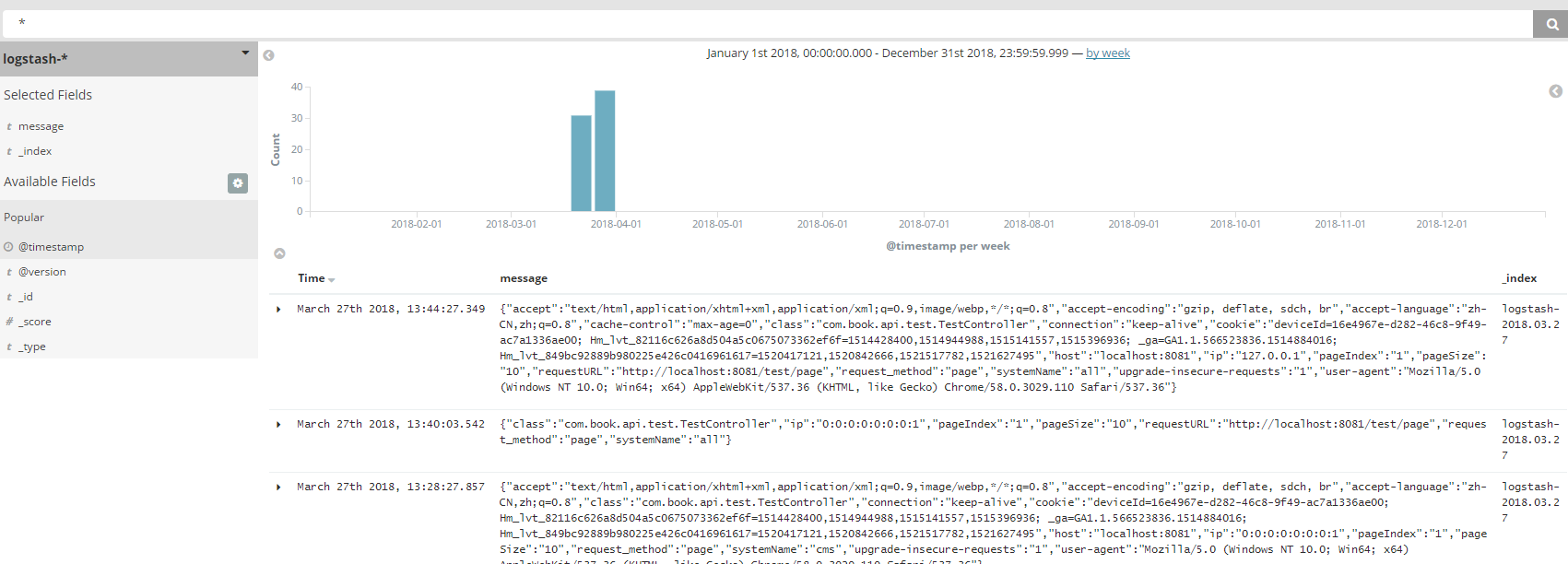
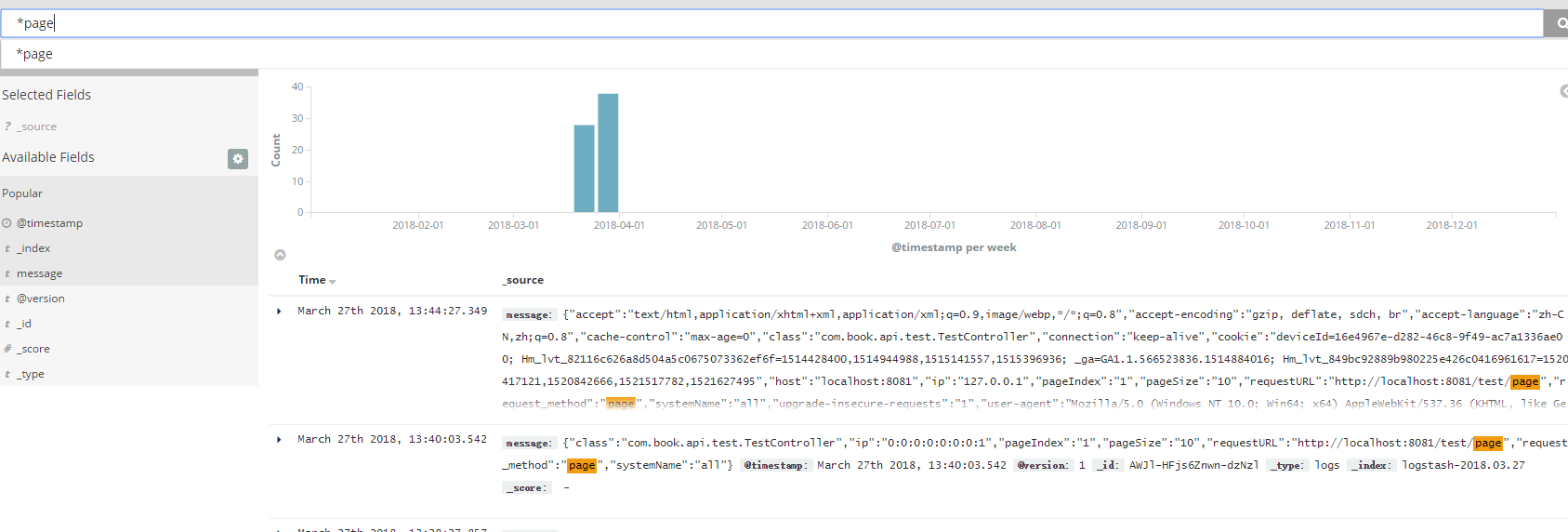
我们调用方法发信消息已经发送到kafka,并且kibana已经可以看到这条log















 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









