







一、引言
在C++中我们写判断逻辑一般会用if else或switch case语句,比如以下例子:
#include <iostream>
using namespace std;
class CTest
{
public:
enum class ConditionType
{
TYPE1 = 0,
TYPE2,
TYPE3,
};
CTest() = default;
~CTest() = default;
void execFun(ConditionType eConditionType) //根据条件执行对应函数
{
switch (eConditionType) {
case ConditionType::TYPE1: {
func1();
break;
}
case ConditionType::TYPE2: {
func2();
break;
}
case ConditionType::TYPE3: {
func3();
break;
}
default:break;
}
}
void execAllFun() //执行所有函数
{
func1();
func2();
func3();
}
void func1() { cout << "Func1" << endl; }
void func2() { cout << "Func2" << endl; }
void func3() { cout << "Func3" << endl; }
};
CTest gTest;
int main()
{
CTest::ConditionType eConditionType = CTest::ConditionType::TYPE1;
gTest.execFun(eConditionType);
gTest.execAllFun();
}执行效果如下:
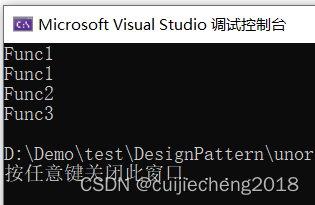
上面的例子很简单,我们用了switch case实现。但有如下不足:
1、swtich语句无法对字符串进行判断,只能对整形/枚举进行判断。
2、代码可读性差。上面的例子因为只有3个判断分支,所以阅读起来还好,但如果有成百上千个判断分支,那execFun函数和execAllFun函数里面的代码会变得非常臃肿,难以阅读。
3、代码可拓展性差。每新增一个分支都要修改execFun函数和execAllFun函数。
二、使用unordered_map查表代替if else和switch case语句
基于上述if else和switch case语句的不足我们可以使用unordered_map查表的方法来重构代码。
#include <iostream>
#include <unordered_map>
#include <functional>
using namespace std;
class CTest
{
public:
enum class ConditionType
{
TYPE1 = 0,
TYPE2,
TYPE3,
};
CTest()
{
m_map[ConditionType::TYPE1] = bind(&CTest::func1, this);
m_map[ConditionType::TYPE2] = bind(&CTest::func2, this);
m_map[ConditionType::TYPE3] = bind(&CTest::func3, this);
}
~CTest() = default;
void execFun(ConditionType eConditionType) //根据条件执行对应函数
{
auto it = m_map.find(eConditionType);
if (it != m_map.end())
{
it->second();
}
}
void execAllFun() //执行所有函数
{
for (const auto &e : m_map)
{
e.second();
}
}
void func1() { cout << "Func1" << endl; }
void func2() { cout << "Func2" << endl; }
void func3() { cout << "Func3" << endl; }
private:
unordered_map<ConditionType, function<void()>> m_map;
};
CTest gTest;
int main()
{
CTest::ConditionType eConditionType = CTest::ConditionType::TYPE1;
gTest.execFun(eConditionType);
gTest.execAllFun();
}上述代码中使用了std::unordered_map而不是std::map是因为unordered_map查询速度更快,具体可以参考《map和unordered_map的区别》。当然也可以选择其它性能更高的hash表,比如google的swisstable
执行效果如下:
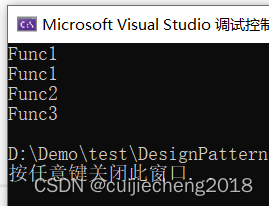
可以看到执行效果跟使用switch case是一摸一样的。并且有如下优点:
1、unordered_map容器类的key可以保存任意类型的数据。所以其实现的判断语句既可以对字符串进行判断,也能对整形/枚举进行判断。
2、代码拓展性强。新增分支不需要修改execFun函数和execAllFun函数,只需要改CTest类的构造函数这一个地方。
3、代码可读性强。直接在CTest类的构造函数中看unordered_map的key 关联了哪个value就可以知道整个判断逻辑。
三、进一步优化:使用单例模式
unordered_map由于建立了哈希表,所以它在最开始建立的时候比较耗时间。在实际的工程项目中我们可以把CTest类设计成单例,让unordered_map只被初始化一次。设计成单例模式的另外一个优点是把要经常使用的资源(全局变量、判断逻辑等)都放到一个地方,这样无论在代码的哪个类里面都能很方便地获取使用这些资源。
#include <iostream>
#include <unordered_map>
#include <functional>
using namespace std;
template<typename T>
class Singleton
{
public:
static T& GetInstance()
{
static T instance;
return instance;
}
Singleton(T&&) = delete;
Singleton(const T&) = delete;
void operator= (const T&) = delete;
protected:
Singleton() = default;
virtual ~Singleton() = default;
};
#define CT CTest::GetInstance()
class CTest : public Singleton<CTest>
{
public:
enum class ConditionType
{
TYPE1 = 0,
TYPE2,
TYPE3,
};
CTest()
{
m_map[ConditionType::TYPE1] = bind(&CTest::func1, this);
m_map[ConditionType::TYPE2] = bind(&CTest::func2, this);
m_map[ConditionType::TYPE3] = bind(&CTest::func3, this);
}
~CTest() = default;
void execFun(ConditionType eConditionType) //根据条件执行对应函数
{
auto it = m_map.find(eConditionType);
if (it != m_map.end())
{
it->second();
}
}
void execAllFun() //执行所有函数
{
for (const auto &e : m_map)
{
e.second();
}
}
void func1() { cout << "Func1" << endl; }
void func2() { cout << "Func2" << endl; }
void func3() { cout << "Func3" << endl; }
private:
unordered_map<ConditionType, function<void()>> m_map;
};
int main()
{
CTest::ConditionType eConditionType = CTest::ConditionType::TYPE1;
CT.execFun(eConditionType);
CT.execAllFun();
return 0;
}执行效果如下:
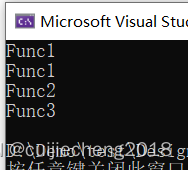
四、总结
使用unordered_map查表操作代替if else/switch case语句,适用于判断分支非常多的场合。比如我们设计平台服务器,该服务器需要跟数十种不同类型的客户端/设备进行通信,涉及成百上千条通信指令。平台服务器接收通信指令后需要执行对应的回调函数,这个时候我们可以用unordered_map查表代替if else/switch case语句,来提高代码的可读性和维护性。















 1951
1951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









