









首先说一下我所用的版本:
spark-2.1.1-bin-hadoop2.7.tgz
hadoop-2.7.3.tar.gz
jdk-8u131-linux-x64.rpm我们实验室有4台服务器:每个节点硬盘:300GB,内存:64GB。四个节点的hostname分别是master,slave01,slave02,slave03。
我用的是Spark做并行计算,用HDFS作为数据的分布式存储,这样的话就得安装hadoop利用里面的HDFS。如果你不用hadoop的话可以直接跳到第7步,直接安装spark即可!
1。先装java1.8环境:给各个节点上传jdk-8u131-linux-x64.rpm到/home里面。用rpm安装。
[root@localhost home]# rpm -ivh jdk-8u131-linux-x64.rpm
Preparing... ################################# [100%]
Updating / installing...
1:jdk1.8.0_131-2000:1.8.0_131-fcs ################################# [100%]
Unpacking JAR files...
tools.jar...
plugin.jar...
javaws.jar...
deploy.jar...
rt.jar...
jsse.jar...
charsets.jar...
localedata.jar...
[root@localhost home]# java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)如上:java1.8 安装成功!!
2。集群核准时间:(如果集群时间一致的话,此步略过!)
时间必须同步,因为节点之间要发送心跳,如果时间不一致的话,会产生错误。
用date -s 命令也行!(下面是ntp服务器来同步时间)
##在每个节点上执行安装ntp服务
[hadoop@master ~]$ sudo yum install -y ntp
##在每个节点上同时执行`sudo ntpdate us.pool.ntp.org`
[hadoop@master ~]$ sudo ntpdate us.pool.ntp.org
5 Oct 18:19:41 ntpdate[2997]: step time server 138.68.46.177 offset -6.006070 sec或者也可以在某个节点上启动一个ntp服务器:
##在每个节点上执行安装ntp服务
[hadoop@master ~]$ sudo yum install -y ntp
##在192.168.2.219节点上执行`sudo ntpdate us.pool.ntp.org`把这个节点作为ntp同步服务器
[hadoop@master ~]$ sudo ntpdate us.pool.ntp.org
5 Oct 18:19:41 ntpdate[2997]: step time server 138.68.46.177 offset -6.006070 sec
##在各个节点上开启ntp服务
[hadoop@master ~]$ sudo service ntpd start
Redirecting to /bin/systemctl start ntpd.service
##在其他节点上同步192.168.2.219节点ntp服务器上的时间。
[hadoop@slave01 ~]$ sudo ntpdate 192.168.2.219
5 Oct 18:27:45 ntpdate[3014]: adjust time server 192.168.147.6 offset -0.001338 sec3。添加用户hadoop:
[root@localhost etc]# useradd -m hadoop -s /bin/bash
useradd: user 'hadoop' already exists
[root@localhost etc]# passwd hadoop
Changing password for user hadoop.
New password:
BAD PASSWORD: The password fails the dictionary check - it is too simplistic/systematic
Retype new password:
passwd: all authentication tokens updated successfully.
[root@localhost etc]# su - hadoop
[hadoop@localhost ~]$ 4。给hadoop用户增加管理员权限,方便部署
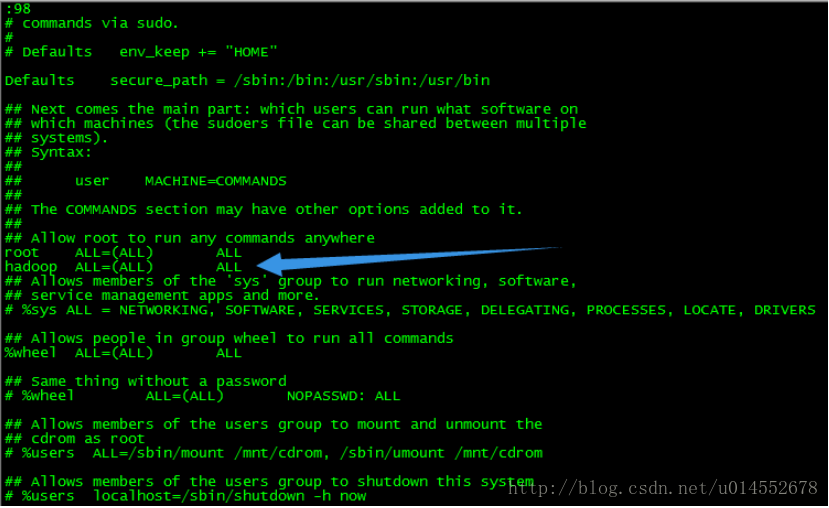
[root@localhost ~]#visudo找到 root ALL=(ALL) ALL 这行(应该在第98行,可以先按一下键盘上的 ESC 键,然后输入 :98 (按一下冒号,接着输入98,再按回车键),可以直接跳到第98行 ),然后在这行下面增加一行内容:hadoop ALL=(ALL) ALL (当中的间隔为tab),如下图所示:
5。SSH无密通信:
[root@master .ssh]#su - hadoop
[hadoop@master ~]$
[hadoop@master ~]$ ssh localhost # 如果没有该目录,先执行一次ssh localhost
[hadoop@master ~]$ cd ~/.ssh
[hadoop@master ~]$ rm ./id_rsa* # 删除之前生成的公匙(如果有)
[hadoop@master ~]$ ssh-keygen -t rsa # 一直按回车就可以
让 Master 节点需能无密码 SSH 本机,在 Master 节点上执行:
[hadoop@master .ssh]$ cat ./id_rsa.pub >> ./authorized_keys
完成后可执行 ssh Master 验证一下(可能需要输入 yes,成功后执行 exit 返回原来的终端)。接着在 master 节点将上公匙传输到 slave01,slave02,slave03 节点:
[hadoop@master .ssh]$ scp ~/.ssh/id_rsa.pub hadoop@slave01:/home/hadoop/
[hadoop@master .ssh]$ scp ~/.ssh/id_rsa.pub hadoop@slave02:/home/hadoop/
[hadoop@master .ssh]$ scp ~/.ssh/id_rsa.pub hadoop@slave03:/home/hadoop/
接着在 slave01,slave02,slave03节点上,将 ssh 公匙加入授权:【分别在其他三个节点上执行以下命令:】
[hadoop@slave03 ~]$ mkdir ~/.ssh
[hadoop@slave03 ~]$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@slave03 ~]$ rm ~/id_rsa.pub
然后在master上执行ssh slave01 但是还是不行解决方法:常见免密码登录失败分析
配置问题
检查配置文件/etc/ssh/sshd_config是否开启了AuthorizedKeysFile选项
检查AuthorizedKeysFile选项指定的文件是否存在并内容正常
目录权限问题
~权限设置为700
~/.ssh权限设置为700
~/.ssh/authorized_keys的权限设置为600
sudo chmod 700 ~
sudo chmod 700 ~/.ssh
sudo chmod 600 ~/.ssh/authorized_keys 6。安装hadoop:

下面是hosts文件内容:
192.168.2.189 slave01
192.168.2.240 slave02
192.168.2.176 slave03
192.168.2.219 master
hadoop-2.7.3.tar.gz放在~下。【一般安装文件都放在~下面】
我们选择将 Hadoop 安装至 /usr/local/ 中:
[hadoop@master ~]$ sudo tar -zxf ~/hadoop-2.7.3.tar.gz -C /usr/local # 解压到/usr/local中
[hadoop@master ~]$ cd /usr/local/
[hadoop@master ~]$ sudo mv ./hadoop-2.7.3/ ./hadoop # 将文件夹名改为hadoop
[hadoop@master ~]$ sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
[hadoop@master local]$ cd /usr/local/hadoop
[hadoop@master hadoop]$ ./bin/hadoop version
Hadoop 2.7.3
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on 2016-08-18T01:41Z
Compiled with protoc 2.5.0
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.7.3.jar6.1。 Hadoop单机配置(非分布式) ,注:先把一个节点的hadoop装好后,然后再依次拷贝到其他的节点上。
Hadoop 默认模式为非分布式模式,无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子(运行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
在此我们选择运行 grep 例子,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
[hadoop@master hadoop]$ cd /usr/local/hadoop
[hadoop@master hadoop]$ mkdir ./input
[hadoop@master hadoop]$ cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
[hadoop@master hadoop]$./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
[hadoop@master hadoop]$ cat ./output/* # 查看运行结果
1 dfsadmin6.2。修改/usr/local/hadoop/etc/hadoop/slaves:这里配置的是三个运行节点,master节点只做master不作为运行节点。
[hadoop@master hadoop]$ vi slaves #里面内容是:
slave01
slave02
slave036.3。文件 core-site.xml 改为下面的配置:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>6.4。文件 hdfs-site.xml,dfs.replication 一般设为 3:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>6.5。文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>6.6。文件 yarn-site.xml:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>6.7。配置好后,将 master 上的 /usr/local/Hadoop 文件夹复制到各个节点上。在 master 节点上执行:
之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。
[hadoop@master ~]$cd /usr/local
[hadoop@master ~]$sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
[hadoop@master ~]$sudo rm -r ./hadoop/logs/* # 删除日志文件
[hadoop@master ~]$tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
[hadoop@master ~]$cd ~
[hadoop@master ~]$scp ./hadoop.master.tar.gz slave01:/home/hadoop
[hadoop@master ~]$scp ./hadoop.master.tar.gz slave02:/home/hadoop
[hadoop@master ~]$scp ./hadoop.master.tar.gz slave03:/home/hadoop6.8。在各个节点执行:
在 slave01 节点上执行:
[hadoop@slave01 ~]$ sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
[hadoop@slave01 ~]$ sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
[hadoop@slave01 ~]$ sudo chown -R hadoop /usr/local/hadoop在 slave02 节点上执行:
[hadoop@slave02 ~]$ sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
[hadoop@slave02 ~]$ sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
[hadoop@slave02 ~]$ sudo chown -R hadoop /usr/local/hadoop在 slave03 节点上执行:
[hadoop@slave03 ~]$ sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
[hadoop@slave03 ~]$ sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
[hadoop@slave03 ~]$ sudo chown -R hadoop /usr/local/hadoop6.9。首次启动需要先在 Master 节点执行 NameNode 的格式化:
[hadoop@master ~]$ hdfs namenode -format #首次运行需要执行初始化,之后不需要6.10。CentOS系统需要关闭防火墙
CentOS系统默认开启了防火墙,在开启 Hadoop 集群之前,需要关闭集群中每个节点的防火墙。有防火墙会导致 ping 得通但 telnet 端口不通,从而导致 DataNode 启动了,但 Live datanodes 为 0 的情况。
在 CentOS 中,可以通过如下命令关闭防火墙:
在 CentOS 6.x 中,可以通过如下命令关闭防火墙:
sudo service iptables stop # 关闭防火墙服务
sudo chkconfig iptables off # 禁止防火墙开机自启,就不用手动关闭了
Shell 命令
若用是 CentOS 7,需通过如下命令关闭(防火墙服务改成了 firewall):
systemctl stop firewalld.service # 关闭firewall
systemctl disable firewalld.service # 禁止firewall开机启动6.11。接着可以启动 hadoop 了,启动需要在 master 节点上进行:
注意修改:vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh ,
把export JAVA_HOME=${JAVA_HOME}改为:export JAVA_HOME=/usr/java/jdk1.8.0_131/
在/usr/local/hadoop/sbin 启动hadoop ./start-all.sh
[hadoop@master sbin]$ ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-master.out
slave03: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-slave03.out
slave01: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-slave01.out
slave02: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-slave02.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-resourcemanager-master.out
slave01: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-slave01.out
slave02: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-slave02.out
slave03: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-slave03.out然后jps
[hadoop@master hadoop]$ jps
6194 ResourceManager
5717 NameNode
5960 SecondaryNameNode
6573 Jps
[hadoop@slave01 hadoop]$ jps
4888 Jps
4508 DataNode
4637 NodeManager
[hadoop@slave02 hadoop]$ jps
3841 DataNode
3970 NodeManager
4220 Jps
[hadoop@slave03 hadoop]$ jps
4032 NodeManager
4282 Jps
3903 DataNode6.12. 打开hadoop WEBUI
在浏览器中输入http://192.168.2.219:50070 【注意浏览器要与192.168.2.219为局域网】
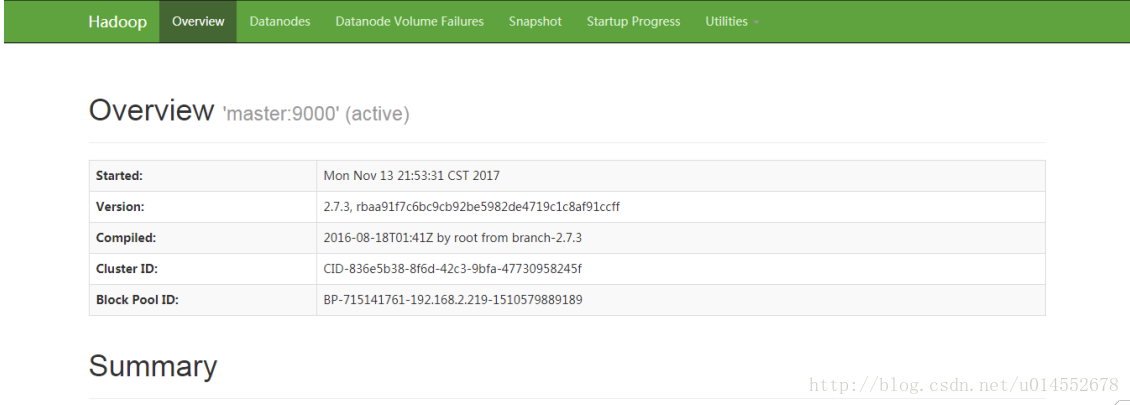
6.13。执行分布式实例
首先创建 HDFS 上的用户目录:
[hadoop@master hadoop]$ hdfs dfs -mkdir -p /user/hadoop
将 /usr/local/hadoop/etc/hadoop 中的配置文件作为输入文件复制到分布式文件系统中:
[hadoop@master hadoop]$ hdfs dfs -mkdir input
[hadoop@master hadoop]$ hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input通过查看 DataNode 的状态(占用大小有改变),输入文件确实复制到了 DataNode 中,如下图所示:
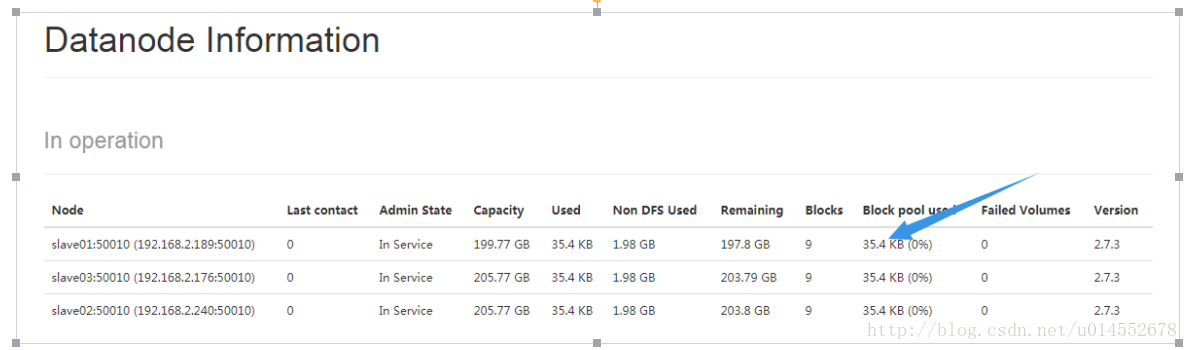
接着就可以运行 MapReduce 作业了:【注意运行前要保证节点时间一致】
####命令:
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
----------
####执行过程运行的log如下:
[hadoop@master hadoop]$ hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
17/11/13 22:26:21 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.2.219:8032
17/11/13 22:26:21 INFO input.FileInputFormat: Total input paths to process : 9
17/11/13 22:26:21 INFO mapreduce.JobSubmitter: number of splits:9
17/11/13 22:26:21 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1510581226826_0004
17/11/13 22:26:22 INFO impl.YarnClientImpl: Submitted application application_1510581226826_0004
17/11/13 22:26:22 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1510581226826_0004/
17/11/13 22:26:22 INFO mapreduce.Job: Running job: job_1510581226826_0004
17/11/13 22:26:28 INFO mapreduce.Job: Job job_1510581226826_0004 running in uber mode : false
17/11/13 22:26:28 INFO mapreduce.Job: map 0% reduce 0%
17/11/13 22:26:32 INFO mapreduce.Job: map 33% reduce 0%
17/11/13 22:26:33 INFO mapreduce.Job: map 100% reduce 0%
17/11/13 22:26:37 INFO mapreduce.Job: map 100% reduce 100%
17/11/13 22:26:37 INFO mapreduce.Job: Job job_1510581226826_0004 completed successfully
17/11/13 22:26:37 INFO mapreduce.Job: Counters: 50
File System Counters
FILE: Number of bytes read=51
FILE: Number of bytes written=1190205
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=28817
HDFS: Number of bytes written=143
HDFS: Number of read operations=30
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Killed map tasks=1
Launched map tasks=9
Launched reduce tasks=1
Data-local map tasks=9
Total time spent by all maps in occupied slots (ms)=26894
Total time spent by all reduces in occupied slots (ms)=2536
Total time spent by all map tasks (ms)=26894
Total time spent by all reduce tasks (ms)=2536
Total vcore-milliseconds taken by all map tasks=26894
Total vcore-milliseconds taken by all reduce tasks=2536
Total megabyte-milliseconds taken by all map tasks=27539456
Total megabyte-milliseconds taken by all reduce tasks=2596864
Map-Reduce Framework
Map input records=796
Map output records=2
Map output bytes=41
Map output materialized bytes=99
Input split bytes=1050
Combine input records=2
Combine output records=2
Reduce input groups=2
Reduce shuffle bytes=99
Reduce input records=2
Reduce output records=2
Spilled Records=4
Shuffled Maps =9
Failed Shuffles=0
Merged Map outputs=9
GC time elapsed (ms)=762
CPU time spent (ms)=7040
Physical memory (bytes) snapshot=2680807424
Virtual memory (bytes) snapshot=19690971136
Total committed heap usage (bytes)=1957691392
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=27767
File Output Format Counters
Bytes Written=143
17/11/13 22:26:37 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.2.219:8032
17/11/13 22:26:37 INFO input.FileInputFormat: Total input paths to process : 1
17/11/13 22:26:37 INFO mapreduce.JobSubmitter: number of splits:1
17/11/13 22:26:37 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1510581226826_0005
17/11/13 22:26:37 INFO impl.YarnClientImpl: Submitted application application_1510581226826_0005
17/11/13 22:26:37 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1510581226826_0005/
17/11/13 22:26:37 INFO mapreduce.Job: Running job: job_1510581226826_0005
17/11/13 22:26:48 INFO mapreduce.Job: Job job_1510581226826_0005 running in uber mode : false
17/11/13 22:26:48 INFO mapreduce.Job: map 0% reduce 0%
17/11/13 22:26:52 INFO mapreduce.Job: map 100% reduce 0%
17/11/13 22:26:57 INFO mapreduce.Job: map 100% reduce 100%
17/11/13 22:26:58 INFO mapreduce.Job: Job job_1510581226826_0005 completed successfully
17/11/13 22:26:58 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=51
FILE: Number of bytes written=237047
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=271
HDFS: Number of bytes written=29
HDFS: Number of read operations=7
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=2331
Total time spent by all reduces in occupied slots (ms)=2600
Total time spent by all map tasks (ms)=2331
Total time spent by all reduce tasks (ms)=2600
Total vcore-milliseconds taken by all map tasks=2331
Total vcore-milliseconds taken by all reduce tasks=2600
Total megabyte-milliseconds taken by all map tasks=2386944
Total megabyte-milliseconds taken by all reduce tasks=2662400
Map-Reduce Framework
Map input records=2
Map output records=2
Map output bytes=41
Map output materialized bytes=51
Input split bytes=128
Combine input records=0
Combine output records=0
Reduce input groups=1
Reduce shuffle bytes=51
Reduce input records=2
Reduce output records=2
Spilled Records=4
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=110
CPU time spent (ms)=1740
Physical memory (bytes) snapshot=454008832
Virtual memory (bytes) snapshot=3945603072
Total committed heap usage (bytes)=347078656
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=143
File Output Format Counters
Bytes Written=29
----------
查看运行结果:
[hadoop@master hadoop]$ hdfs dfs -cat output/*
1 dfsadmin
1 dfs.replication运行时的输出信息与伪分布式类似,会显示 Job 的进度。
可能会有点慢,但如果迟迟没有进度,比如 5 分钟都没看到进度,那不妨重启 Hadoop 再试试。
6.14。关闭 Hadoop 集群也是在 Master 节点上执行的:./sbin/stop-all.sh 即可
[hadoop@master sbin]$ stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [master]
master: stopping namenode
slave01: stopping datanode
slave03: stopping datanode
slave02: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
slave01: stopping nodemanager
slave02: stopping nodemanager
slave03: stopping nodemanager
slave01: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
slave02: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
slave03: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
no proxyserver to stop附录:增加一个master节点作为slaves ,这样运行节点就变成4个了,进入/usr/local/hadoop/etc/hadoop/修改slaves为:
master
slave01
slave02
slave03
$PWD就是当前目录,把此目录的slaves拷贝到其他三个节点上进行覆盖。
[hadoop@master hadoop]$ scp slaves hadoop@slave01:$PWD
[hadoop@master hadoop]$ scp slaves hadoop@slave02:$PWD
[hadoop@master hadoop]$ scp slaves hadoop@slave03:$PWD再启动:
[hadoop@master hadoop]$ ./sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-master.out
master: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-master.out
slave02: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-slave02.out
slave01: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-slave01.out
slave03: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-slave03.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-resourcemanager-master.out
slave02: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-slave02.out
slave01: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-slave01.out
master: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-master.out
slave03: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-slave03.out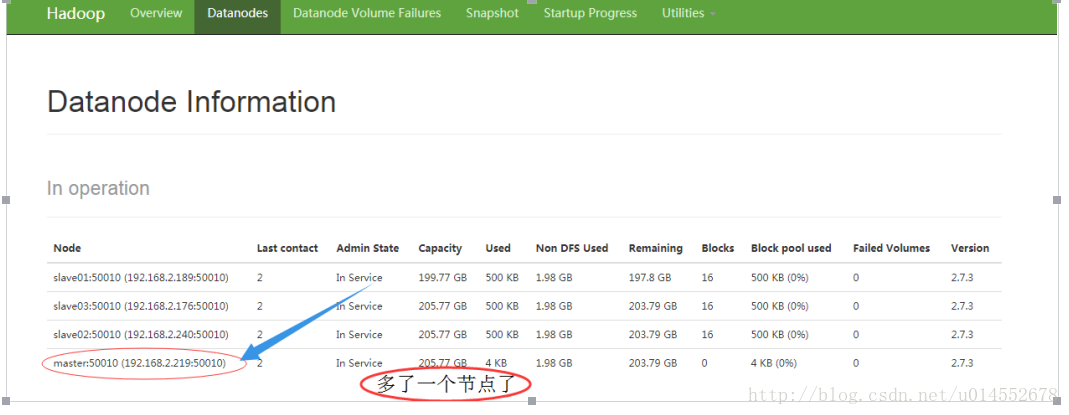
至此hadoop安装完成!!!!
7。安装spark
先把spark-2.1.1-bin-hadoop2.7.tgz传到~里。
执行命令:
[hadoop@master ~]$ sudo tar -zxf ~/spark-2.1.1-bin-hadoop2.7.tgz -C /usr/local/
[hadoop@master ~]$ cd /usr/local
[hadoop@master ~]$ sudo cp ./spark-2.1.1-bin-hadoop2.7.tgz/ ./spark
[hadoop@master ~]$ sudo chown -R hadoop:hadoop ./spark7.1。 在/usr/local/spark/conf里,修改spark-env.sh添加:
export JAVA_HOME=/usr/java/jdk1.8.0_131
export SPARK_MASTER_IP=192.168.2.219
export SPARK_MASTER_PORT=70777.2。在/usr/local/spark/conf里,添加内容到slaves,这里有4个运行节点把master也算进去了,master既做管理又做计算
[hadoop@master conf]$ cat slaves
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# A Spark Worker will be started on each of the machines listed below.
master
slave01
slave02
slave037.3。 配置好后,将Master主机上的/usr/local/spark文件夹复制到各个节点上。在Master主机上执行如下命令:
[hadoop@master local]$ cd /usr/local/
压缩spark包
[hadoop@master local]$ tar -zcf ~/spark.master.tar.gz ./spark
[hadoop@master local]$ cd ~
把spark压缩包远程传到其他节点
[hadoop@master local]$ scp ./spark.master.tar.gz slave01:/home/hadoop
[hadoop@master local]$ scp ./spark.master.tar.gz slave02:/home/hadoop
[hadoop@master local]$ scp ./spark.master.tar.gz slave03:/home/hadoop在slave01,slave02,slave03节点上分别执行下面同样的操作:
[hadoop@slave01 spark]$ sudo tar -zxf ~/spark.master.tar.gz -C /usr/local
[hadoop@slave01 spark]$ sudo chown -R hadoop:hadoop /usr/local/spark7.4。启动Spark集群
启动Hadoop集群
启动Spark集群前,要先启动Hadoop集群。在Master节点主机上运行如下命令:
[hadoop@master ~]$ cd /usr/local/hadoop/
[hadoop@master ~]$ ./sbin/start-all.sh启动Spark集群
[hadoop@master spark]$ ./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-master.out
slave02: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-slave02.out
master: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-master.out
slave03: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-slave03.out
slave01: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-slave01.out
[hadoop@master spark]$ jps
4641 Master
4068 ResourceManager
3447 NameNode
4807 Worker
3608 DataNode
3832 SecondaryNameNode
4938 Jps
4207 NodeManager在浏览器上查看Spark独立集群管理器的集群信息,在192.168.2.219主机上打开浏览器,访问http://192.168.2.219:8080,如下图:

安装成功!!!
7.5。关闭Spark集群
关闭spark:./stop-all.sh
关闭hadoop:./sbin/stop-all.sh
[hadoop@master spark]$ ./sbin/stop-all.sh
master: stopping org.apache.spark.deploy.worker.Worker
slave03: stopping org.apache.spark.deploy.worker.Worker
slave02: stopping org.apache.spark.deploy.worker.Worker
slave01: stopping org.apache.spark.deploy.worker.Worker
stopping org.apache.spark.deploy.master.Master
[hadoop@master spark]$ cd ..
[hadoop@master local]$ cd hadoop
[hadoop@master spark]$ ./sbin/stop-all.sh
master: stopping org.apache.spark.deploy.worker.Worker
slave03: stopping org.apache.spark.deploy.worker.Worker
slave02: stopping org.apache.spark.deploy.worker.Worker
slave01: stopping org.apache.spark.deploy.worker.Worker
stopping org.apache.spark.deploy.master.Master
[hadoop@master hadoop]$ ./sbin/stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [master]
master: stopping namenode
master: stopping datanode
slave02: stopping datanode
slave03: stopping datanode
slave01: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
slave03: stopping nodemanager
slave02: stopping nodemanager
slave01: stopping nodemanager
master: stopping nodemanager
no proxyserver to stop集群已经停止!!















 5292
5292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









