







 本文是关于微软Deepspeed中GPT-2模型的源码学习记录,主要涵盖模型概述、代码模块解读及预训练过程。GPT-2是一个基于Transformer的预训练模型,其主模块由多个TransformerBlock组成,每个Block包含SelfAttention和MLP。预训练阶段,通过forward计算损失函数,输入和目标标签分别是句子的前缀和后缀。
本文是关于微软Deepspeed中GPT-2模型的源码学习记录,主要涵盖模型概述、代码模块解读及预训练过程。GPT-2是一个基于Transformer的预训练模型,其主模块由多个TransformerBlock组成,每个Block包含SelfAttention和MLP。预训练阶段,通过forward计算损失函数,输入和目标标签分别是句子的前缀和后缀。
相关链接:
gpt2论文传送门
microsoft Deepspeed gpt2源码传送
微软 Deepspeed 中集成的 gpt2 代码感觉比 huggingface 的代码可读性要强很多,这里只用作代码结构的学习,暂时忽略其中模型分片并行的部分。
(虽然感觉直接把精华给忽略了Orz)
文章目录
1. GPT2模型概述
GPT2 是2018年发布的预训练模型,使用超过40G的近8000万的网页文本数据对模型进行训练。
GPT-2 可以理解成是由 transforer 的decoder 堆叠成的,输入是 word embeddings + position embeddings。
transformer 模块处理单词的步骤如下:首先通过自注意力层处理,接着将其传递给神经网络层。第一个 transformer 模块处理完但此后,会将结果向量被传入堆栈中的下一个 transformer 模块,继续进行计算。每一个 transformer 模块的处理方式都是一样的,但每个模块都会维护自己的自注意力层和神经网络层中的权重。
2. GPT2代码模块阅读
GPT-2的代码模块可读性较强,整体框架如下:
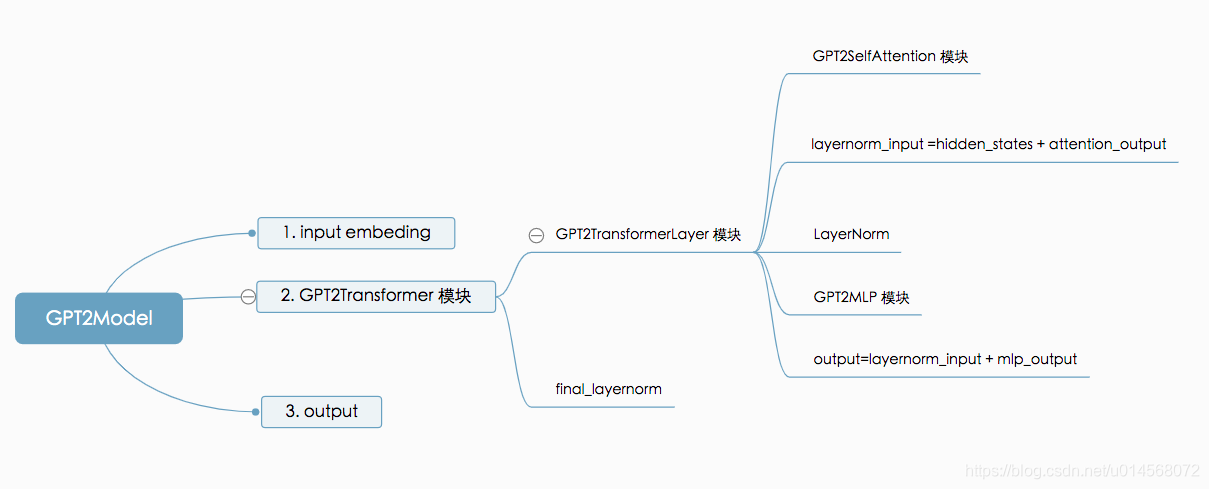
2.1 GPT2Model主模块
class GPT2Model(torch.nn.Module):
"""GPT-2 Language model.
The output of the forward method are the logits (parallel or
serial depending on the `parallel_output` flag.
"""
def __init__(self,
num_layers,
vocab_size,
hidden_size,
num_attention_heads,
embedding_dropout_prob,
attention_dropout_prob,
output_dropout_prob,
max_sequence_length,
checkpoint_activations,
checkpoint_num_layers=1,
parallel_output=True):
super(GPT2Model, self).__init__()
self.parallel_output = parallel_output
init_method = init_method_normal(std=0.02)
# Word embeddings (parallel).
# 生成 word embedding,shape 是 vocab_size * hidden_size,用于lookup embedding
self.word_embeddings = mpu.VocabParallelEmbedding(
vocab_size, hidden_size, init_method=init_method)
# Position embedding (serial).
# position embedding,shape 是vocab_size * hidden_size,用于 每个position 的 lookup embedding,是绝对位置编码
self.position_embeddings = torch.nn.Embedding(max_sequence_length,
hidden_size)
# Initialize the position embeddings.
init_method(self.position_embeddings.weight)
# Embeddings dropout
self.embedding_dropout = torch.nn.Dropout(embedding_dropout_prob)
# Transformer
# 构建transformer模块(后文详细说)
self.transformer = mpu.GPT2ParallelTransformer(num_layers, # transformer 层数
hidden_size,
num_attention_heads, # 多头attention的头数
attention_dropout_prob,
output_dropout_prob,
checkpoint_activations,
checkpoint_num_layers)
def forward(self, input_ids, position_ids, attention_mask):
# Embeddings.
# 根据输入 id 做 look up embeddings
words_embeddings = self.word_embeddings(input_ids)
# 根据位置id 做 look up embeddings
position_embeddings = self.position_embeddings(position_ids)
# 实际的输入是 文本+位置 embedding
embeddings = words_embeddings + position_embeddings
# Dropout.
embeddings = self.embedding_dropout(embeddings)
# Transformer.
# 将 embedding 和 mask作为transformer的输入
transformer_output = self.transformer(embeddings, attention_mask)
# Parallel logits.
# 并行计算的logits
transformer_output_parallel = mpu.copy_to_model_parallel_region(
transformer_output)
logits_parallel = F.linear(transformer_output_parallel,
self.word_embeddings.weight)
if self.parallel_output:
return logits_parallel
return mpu.gather_from_model_parallel_region(logits_parallel)
2.2 GPT2Transformer 模块
GPT2ParallelTransformer 模块是封装在 mpu/transformer.py 里的,mpu就是模型并行的框架了,里面封装了bert和gpt2并行训练的代码。
这里只看原理相关的部分了,暂时忽略并行的部分。
该模块是模型的主模块,即将n个的 transformer blocks 打包在一起,即 n * transformer layer + final layernorm 两部分组成。
单独的transformer layer代码详见 2.3。
class GPT2ParallelTransformer(torch.nn.Module):
"""GPT-2 transformer.
This module takes input from embedding layer and it's output can
be used directly by a logit layer. It consists of L (num-layers)
blocks of:
layer norm
self attention
residual connection
layer norm
mlp
residual connection
followed by a final layer norm.
Arguments:
num_layers: Number of transformer layers.
hidden_size: The hidden size of the self attention.
num_attention_heads: number of attention head in the self
attention.
attention_dropout_prob: dropout probability of the attention
score in self attention.
output_dropout_prob: dropout probability for the outputs
after self attention and final output.
checkpoint_activations: if True, checkpoint activations.
checkpoint_num_layers: number of layers to checkpoint. This
is basically the chunk size in checkpoitning.
layernorm_epsilon: epsilon used in layernorm to avoid
division by zero.
init_method_std: standard deviation of the init method which has
the form N(0, std).
use_scaled_init_for_output_weights: If Ture use 1/sqrt(2*num_layers)
scaling for the output weights (
output of self attention and mlp).
"""
def __init__(self,
num_layers,
hidden_size,
num_attention_heads,
attention_dropout_prob,
output_dropout_prob,
checkpoint_activations,
checkpoint_num_layers=1,
layernorm_epsilon=1.0e-5,
init_method_std=0.02,
use_scaled_init_for_output_weights=True,
sparse_attention_config=None,
max_seq_length=None):
super(GPT2ParallelTransformer, self).__init__()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









