







「 Redis 」 SkipList 跳表底层实现及应用
参考&鸣谢
Redis中ZSet的底层数据结构跳跃表skiplist,你真的了解吗? RiemannChow
深入理解跳表及其在Redis中的应用 京东云开发者
Redis跳表底层实现 来年花惜
一、什么是跳跃表(skiplist)
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。和链表、字典等数据结构被广泛地应用在 Redis 内部不同,Redis 只在两个地方用到了跳跃表,一个是实现有序集合健,另一个是在集群节点中用做内部数据结构,除此之外,跳跃表在 Redis 里没有其它用途。
我们来想一下,为啥 Redis 中这两个场景要选择 skiplist?
既然跳跃表是一种有序数据结构,那我们就来考虑在有序序列中查找某个特定元素的情境:
- 如果该序列用支持随机访问的线性结构(数组)存储,那么我们很容易地用二分查找来做。
- 但是考虑到增删效率和内存扩展性,很多时候要用不支持随机访问的线性结构(链表)存储,就只能从头遍历、逐个比对。
- 作为折衷,如果用二叉树结构(BST)存储,就可以不靠随机访问特性进行二分查找了。
我们知道,普通 BST 插入元素越有序效率越低,最坏情况会退化回链表。因此很多大佬提出了自平衡 BST 结构,使其在任何情况下的增删查操作都保持 O(logn) 的时间复杂度。自平衡 BST 的代表就是 AVL 树及其衍生出来的红黑树。如果推广之,不限于二叉树的话,我们耳熟能详的 B 树和 B+ 树也属此类,常用于文件系统和数据库。
自平衡BST显然很香,但是它仍然有一个不那么香的点:树的自平衡过程比较复杂,实现起来麻烦,在高并发的情况下,加锁也会带来可观的overhead。如AVL树需要LL、LR、RL、RR四种旋转操作保持平衡,红黑树则需要左旋、右旋和节点变色三种操作。下面的动图展示的就是AVL树在插入元素时的平衡过程。

那么,有没有简单点的、与自平衡 BST 效率相近的实现方法呢?答案就是跳跃表,并且它简单很多,下面我们就来看一看。
二、如何理解跳跃表
对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。

那怎么来提高查找效率呢?请看我下面画的图,在该链表中,每隔一个节点就有一个附加的指向它在表中前两个位置上的节点的链,正因为如此,在最坏的情形下,最多考察 n/2 + 1 个节点。比如我们要查 90 这个节点,按照之前单链表的查找的话要 8 个节点,现在只需 5 个节点。

我们来将这种想法扩展一下,得到下面的图,这里每隔 4 个节点就有一个链接到该节点前方的下一个第 4 节点的链,只有 n/4 + 1 个节点被考察。

这里我们利用数学的思想,针对通用性做扩展。每隔第 2^i 个节点就有一个链接到这个节点前方下一个第 2^i 个节点链。链的总个数仅仅是加倍,但现在在一次查找中最多只考察 logn 个节点。不难看到一次查找的总时间消耗为 O(logn),这是因为查找由向前到一个新的节点或者在同一节点下降到低一级的链组成。在一次查找期间每一步总的时间消耗最多为 O(logn)。注意,在这种数据结构中的查找基本上是折半查找(Binary Search)。
我只举了两个例子,这里你可以自己想象下大量数据也就是链表长度为 n 的时候,查找的效率更加的凸显出来了。
这种链表加多级索引的的结构,就是跳跃表。接下来我们来定量的分析下,用跳表查询到底有多快。
三、跳跃表的时间复杂度分析
我们知道,在一个单链表中查询某个数据的时间复杂度是 O(n)。那在一个具有多级索引的跳表中,查询某个数据的时间复杂度是多少呢?
我把问题分解一下,先来看这样一个问题,如果链表里有 n 个结点,会有多少级索引呢?
按照我们上面讲的,第一级索引的链节点个数大约就是 n/2 个,第二级索引的链节点个数大约就是 n/4 个,第三级索引的链节点个数大约就是 n/8 个,依次类推,也就是说,第 k 级索引的链节点个数是第 k-1 级索引的链节点个数的 1/2,那第 k 级索引节点的个数就是 n/(2k)。
假设索引有 h 级,最高级的索引有 2 个节点。通过上面的公式,我们可以得到 n/(2h)=2,从而求得 h=log2n-1。如果包含原始链表这一层,整个跳表的高度就是 log2n。我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个节点,那在跳表中查询一个数据的时间复杂度就是 O(m*logn)。
那这个 m 的值是多少呢?按照前面这种索引结构,我们每一级索引都最多只需要遍历 3 个结点,也就是说 m=3,为什么是 3 呢?我来解释一下。
假设我们要查找的数据是 x,在第 k 级索引中,我们遍历到 y节点之后,发现 x 大于 y,小于后面的节点 z,所以我们通过 y 的 down 指针,从第 k 级索引下降到第 k-1 级索引。在第 k-1 级索引中,y 和 z 之间只有 3 个节点(包含 y 和 z),所以,我们在 k-1 级索引中最多只需要遍历 3 个结点,依次类推,每一级索引都最多只需要遍历 3 个节点。

通过上面的分析,我们得到 m=3,所以在跳跃表中查询任意数据的时间复杂度就是 O(logn)。这个查找的时间复杂度跟二分查找是一样的。换句话说,我们其实是基于单链表实现了二分查找,前提是建立了很多级索引,也就是我们讲过的空间换时间的设计思路。
我们的时间复杂度很优秀,那跳跃表的空间复杂度是多少呢?
实际上,在软件开发中,我们不必太在意索引占用的额外空间。在讲数据结构和算法时,我们习惯性地把要处理的数据看成整数,但是在实际的软件开发中,原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了。
四、跳跃表实现原理
Redis 的跳跃表是由 redis.h/zskiplistNode 和 redis.h/zskiplist 两个结构定义,其中 zskiplistNode 用于表示跳跃节点,而 zskiplist 结构则用于保存跳跃表节点的相关信息,比如节点的数量以及指向表头节点和表尾节点的指针等等。

上图最左边的是 zskiplist 结构,该结构包含以下属性:
- header:指向跳跃表的表头节点
- tail:指向跳跃表的表尾节点
- level:记录目前跳跃表内,层数最大的那个节点层数(表头节点的层数不计算在内)
- length:记录跳跃表的长度,也就是跳跃表目前包含节点的数量(表头节点不计算在内)
位于 zskiplist 结构右侧是四个 zskiplistNode 结构,该结构包含以下属性:
- 层(level):节点中用 L1、L2、L3 等字样标记节点的各个层,L1 代表第一层,L2 代表第二层,以此类推。每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其它节点,而跨度则记录了前进指针所指向节点和当前节点的距离。
- 后退(backward)指针:节点中用 BW 字样标识节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。
- 分值(score):各个节点中的 1.0、2.0 和 3.0 是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。
- 成员对象(obj):各个节点中的 o1、o2 和 o3 是节点所保存的成员对象。
我们接下来看下 Redis 是如何实现 skiplist 的。
结构定义
zskiplist 的结构定义:

zskiplistNode 的结构定义:

skiplist 创建

这里需要注意的是常量 ZSKIPLIST_MAXLEVEL,它定义了 zskiplist 的最大层数,值为 32,这也是节点最高只到 L32 的原因。
skiplist 插入节点

其大致执行流程如下:
- 按照前面讲过的查找流程,找到合适的插入位置。注意 zset 允许分数 score 相同,这时会根据节点数据 obj 的字典序来排序。
- 调用 zslRandomLevel() 方法,随机出要插入的节点的层数。
- 调用 zslCreateNode() 方法,根据层数 level、分数 score 和数据 obj 创建出新节点。
- 每层遍历,修改新节点以及其前后节点的前向指针 forward 和跳跃长度 span,也要更新最底层的后向指针 backward。
- 其中维护了两个数组 update 和 rank。update 数组用来记录每一层的最后一个分数小于待插入 score 的节点,也就是插入位置。rank 数组用来记录上述插入位置的上一个节点的排名,以便于最后更新 span 值。
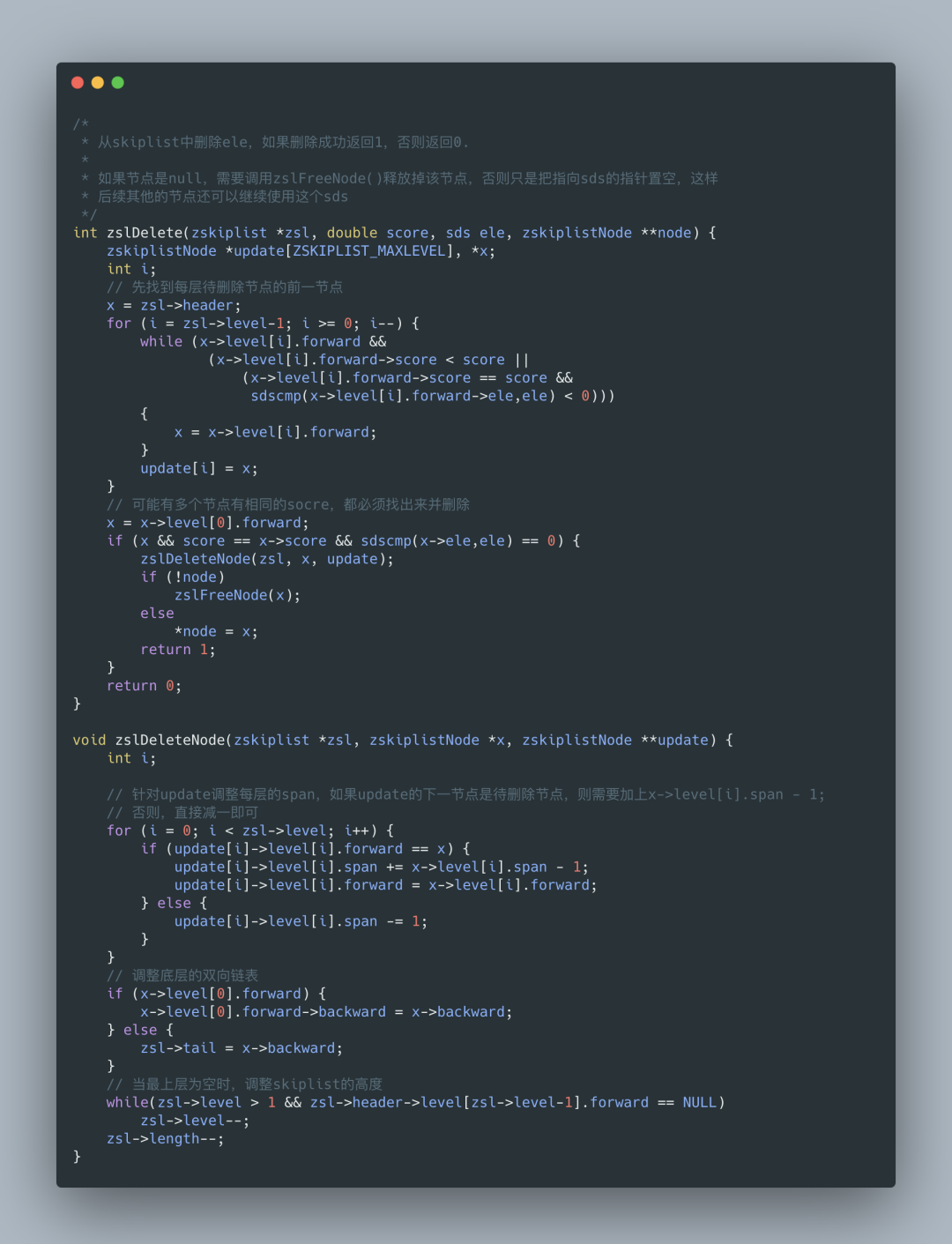
5.4 skiplist 删除节点
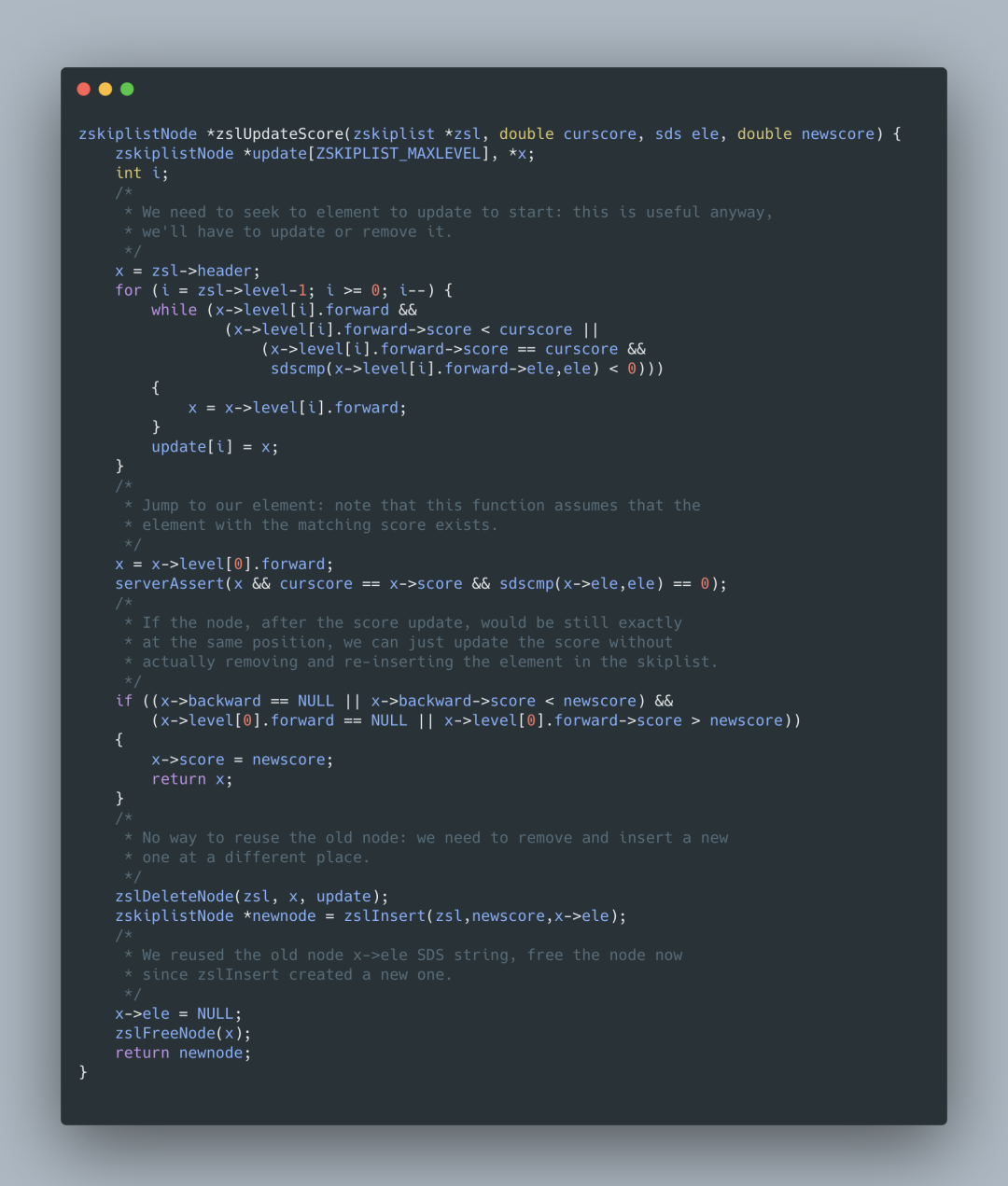
skiplist 更新节点
更新的过程和插入的过程都是是使用着 zadd 方法的,先是判断这个 value 是否存在,如果存在就是更新的过程,如果不存在就是插入过程。在更新的过程是,如果找到了 Value,先删除掉,再新增,这样的弊端是会做两次的搜索,在性能上来讲就比较慢了,
在 Redis 5.0 版本中,Redis 的作者 Antirez 优化了这个更新的过程,目前的更新过程是如果判断这个 value 是否存在,如果存在的话就直接更新,然后再调整整个跳跃表的 score 排序,这样就不需要两次的搜索过程。
skiplist 查找节点
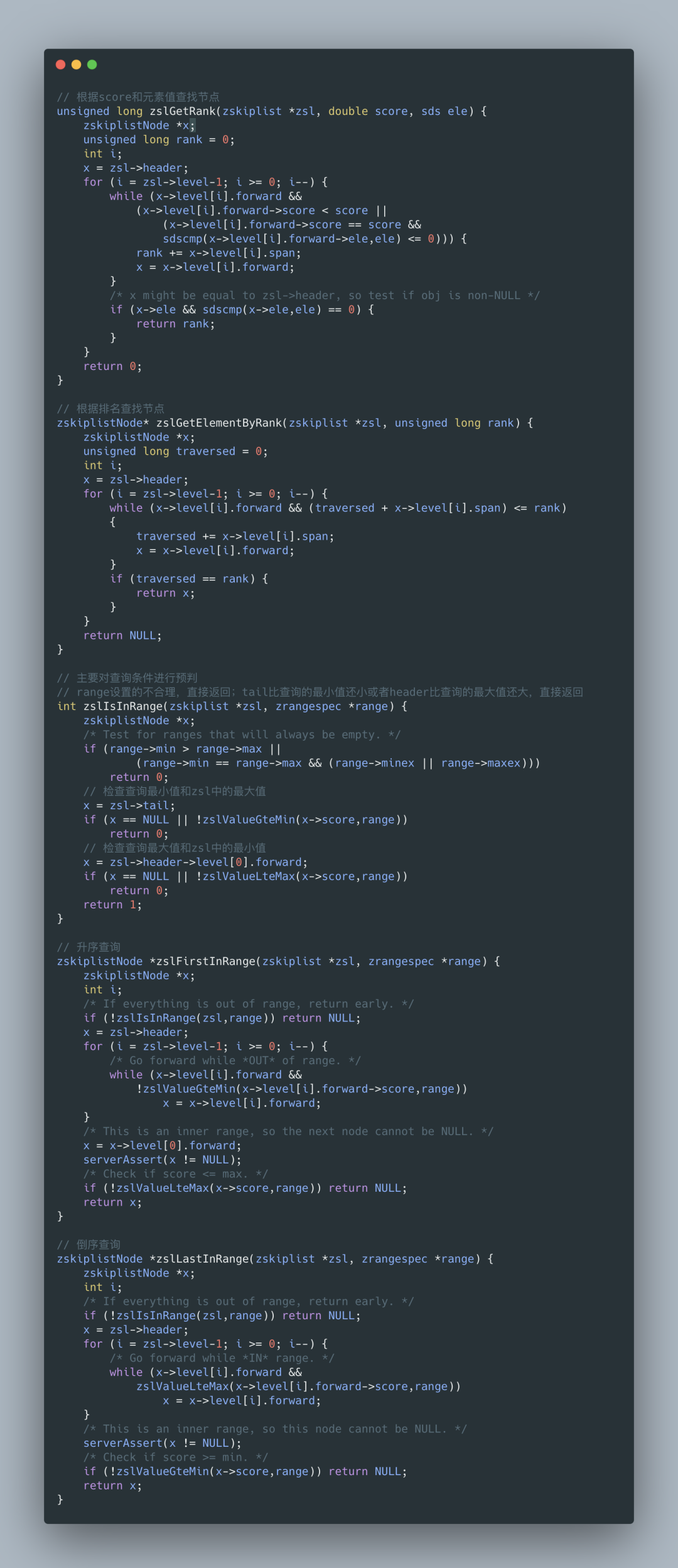
五、跳表在ZSet中的应用
一般讨论查找问题时首先想到的是平衡树和哈希表,但是跳表这种数据结构也非常犀利,性能和实现复杂度都可以和红黑树媲美,甚至某些场景由于红黑树,从1990年被发明目前广泛应用于多种场景中,包括Redis、LevelDB等数据存储引擎中,后续将详细介绍。
跳表在Redis中的应用
ZSet结构同时包含一个字典和一个跳跃表,跳跃表按score从小到大保存所有集合元素。字典保存着从member到score的映射。这两种结构通过指针共享相同元素的member和score,不会浪费额外内存。
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
ZSet中的字典和跳表布局:

ZSet中跳表的实现细节
随机层数的实现原理
跳表是一个概率型的数据结构,元素的插入层数是随机指定的。Willam Pugh在论文中描述了它的计算过程如下:指定节点最大层数 MaxLevel,指定概率 p, 默认层数 lvl 为1
生成一个0~1的随机数r,若r<p,且lvl<MaxLevel ,则lvl ++
重复第 2 步,直至生成的r >p 为止,此时的 lvl 就是要插入的层数。
论文中生成随机层数的伪码:

在Redis中对跳表的实现基本上也是遵循这个思想的,只不过有微小差异,看下Redis关于跳表层数的随机源码src/z_set.c:
/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned. */
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
其中两个宏的定义在redis.h中:
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^32 elements */
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
可以看到while中的:
(random()&0xFFFF) < (ZSKIPLIST_P*0xFFFF)
第一眼看到这个公式,因为涉及位运算有些诧异,需要研究一下Antirez为什么使用位运算来这么写?
最开始的猜测是random()返回的是浮点数[0-1],于是乎在线找了个浮点数转二进制的工具,输入0.5看了下结果:

可以看到0.5的32bit转换16进制结果为0x3f000000,如果与0xFFFF做与运算结果还是0,不符合预期。
我印象中C语言的math库好像并没有直接random函数,所以就去Redis源码中找找看,于是下载了3.2版本代码,也并没有找到random()的实现,不过找到了其他几个地方的应用:
- random()在dict.c中的使用:

- random()在cluster.c中的使用:

看到这里的取模运算,后知后觉地发现原以为random()是个[0-1]的浮点数,但是现在看来是uint32才对,这样Antirez的式子就好理解了。
ZSKIPLIST_P*0xFFFF
由于ZSKIPLIST_P=0.25,所以相当于0xFFFF右移2位变为0x3FFF,假设random()比较均匀,在进行0xFFFF高16位清零之后,低16位取值就落在0x0000-0xFFFF之间,这样while为真的概率只有1/4,更一般地说为真的概率为1/ZSKIPLIST_P。
对于随机层数的实现并不统一,重要的是随机数的生成,在LevelDB中对跳表层数的生成代码是这样的:
template <typename Key, typename Value>
int SkipList<Key, Value>::randomLevel() {
static const unsigned int kBranching = 4;
int height = 1;
while (height < kMaxLevel && ((::Next(rnd_) % kBranching) == 0)) {
height++;
}
assert(height > 0);
assert(height <= kMaxLevel);
return height;
}
uint32_t Next( uint32_t& seed) {
seed = seed & 0x7fffffffu;
if (seed == 0 || seed == 2147483647L) {
seed = 1;
}
static const uint32_t M = 2147483647L;
static const uint64_t A = 16807;
uint64_t product = seed * A;
seed = static_cast<uint32_t>((product >> 31) + (product & M));
if (seed > M) {
seed -= M;
}
return seed;
}
可以看到leveldb使用随机数与kBranching取模,如果值为0就增加一层,这样虽然没有使用浮点数,但是也实现了概率平衡。
跳表结点的平均层数
我们很容易看出,产生越高的节点层数出现概率越低,无论如何层数总是满足幂次定律越大的数出现的概率越小。
如果某件事的发生频率和它的某个属性成幂关系,那么这个频率就可以称之为符合幂次定律。
幂次定律的表现是少数几个事件的发生频率占了整个发生频率的大部分, 而其余的大多数事件只占整个发生频率的一个小部分。

幂次定律应用到跳表的随机层数来说就是大部分的节点层数都是黄色部分,只有少数是绿色部分,并且概率很低。
定量的分析如下:
- 节点层数至少为1,大于1的节点层数满足一个概率分布。
- 节点层数恰好等于1的概率为p^0(1-p)
- 节点层数恰好等于2的概率为p^1(1-p)
- 节点层数恰好等于3的概率为p^2(1-p)
- 节点层数恰好等于4的概率为p^3(1-p)
依次递推节点层数恰好等于K的概率为p^(k-1)(1-p)
因此如果我们要求节点的平均层数,那么也就转换成了求概率分布的期望问题了,灵魂画手大白再次上线:
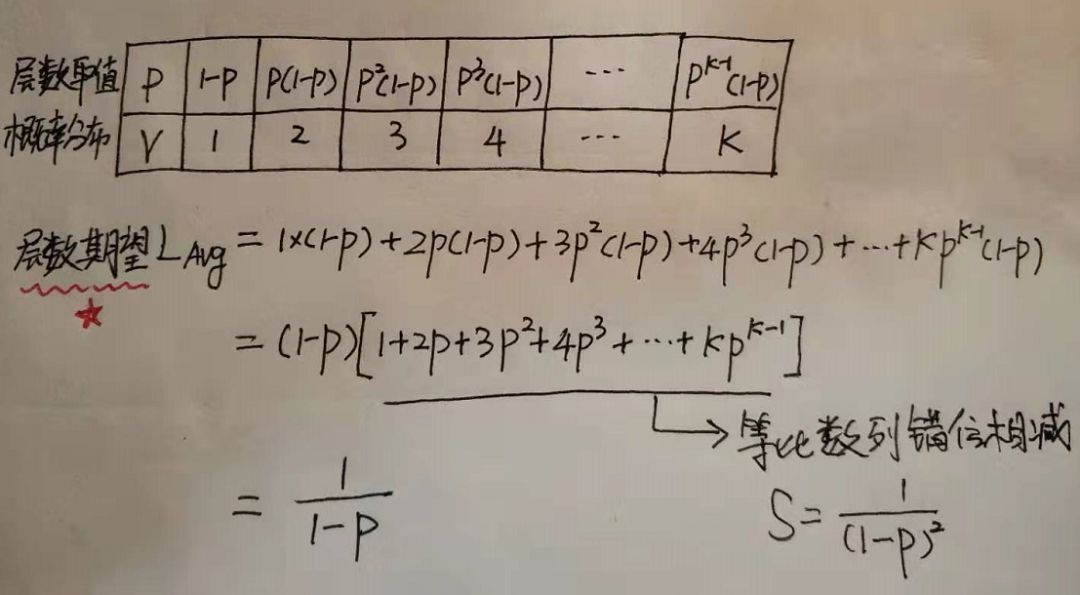
表中P为概率,V为对应取值,给出了所有取值和概率的可能,因此就可以求这个概率分布的期望了。
方括号里面的式子其实就是高一年级学的等比数列,常用技巧错位相减求和,从中可以看到结点层数的期望值与1-p成反比。
对于Redis而言,当p=0.25时结点层数的期望是1.33。
在Redis源码中有详尽的关于插入和删除调整跳表的过程,本文就不再展开了,代码并不算难懂,都是纯C写的没有那么多炫技的特效,放心大胆读起来。
六、小结
本文主要讲述了跳表的基本概念和简单原理、以及索引结点层级、时间和空间复杂度等相关部分,并没有涉及概率平衡以及工程实现部分,并且以Redis中底层的数据结构zset作为典型应用来展开,进一步看到跳跃链表的实际应用。
跳表的时间复杂度与AVL树和红黑树相同,可以达到O(logN),但是AVL树要维持高度的平衡,红黑树要维持高度的近似平衡,这都会导致插入或者删除节点时的一些时间开销,所以跳表相较于AVL树和红黑树来说,省去了维持高度的平衡的时间开销,但是相应的也付出了更多的空间来存储多个层的节点,所以跳表是用空间换时间的数据结构。
需要注意的是跳跃链表的原理、应用、实现细节也是面试的热点问题,值得大家花费时间来研究掌握。
















 1125
1125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











