










我们这里来介绍一下二分查找
本页内容:
1.二分查找原理
2.代码实现
3.查找长度分析
4.在向量模板中实现
5.二分查找改进
1.二分查找原理:
设查找范围为[lo,hi)
二分查找采用减而治之的办法,以有序数列的中点元素V[mi]为界,将查找区间分为三部分:
V[lo,mi)<=V[mi]<=V(mi,hi)
再将目标元素e与V[mi]作比较,可分为三种情况进一步处理:
1) e<V[mi] :则深入左侧V[lo,mi)继续查找。
2) e>V[mi] :则深入右侧V(mi,hi)继续查找。
3) e=V[mi] :已找到,立即返回
这样,每次查找都可以将查找范围缩小一半。可用下图形象表示:

2.代码实现:
#include<iostream>
using namespace std;
/*********二分查找(基于数组)**********/
int binSearch(int *A,int e,int lo,int hi)
{
int mi;
while(lo<hi)
{
mi=(lo+hi)/2;
if(e<A[mi])//深入左半段
{
hi=mi;
}
else if(e>A[mi])//生如右半段
{
lo=mi+1;
}
else
{
return mi;//命中返回
}
}
return -1;//查找失败
}
/**************************************/
int main()
{
int a[100];
for(int i=0;i<100;i++)
{
a[i]=i;
}
/*binSearch查找测试*/
cout<<binSearch(a,101,0,100)<<endl;
cout<<binSearch(a,50,0,100)<<endl;
/*******************/
return 0;
} 3.查找长度分析
在此算法中,我们将比较次数作为查找长度。很明显,查找长度越小,说明效率越高。
通常,我们评价一个算法的好坏,需分别针对其成功与失败查找,从最好,最坏,平均等角度评估。
如图,我们取有序数列长度为7,来分别观察其各个元素的的查找长度:
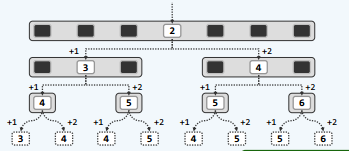
由代码:
if(e<A[mi])//深入左半段
{
hi=mi;
}
else if(e>A[mi])//深入右半段
{
lo=mi+1;
}
else
{
return mi;//命中返回
}查找成功时,各元素对应的成功查找长度 :{4,3,5,2,5,4,6} 平均查找长度:(4+3+5+2+5+4+6)/7=4.14
查找失败时,各元素对应的失败查找长度 :{3,4,4,5,4,5,5,6} 平均查找长度:(3+4+4+5+4+5+5+6)/8=4.50
我们也可以改写一下程序,让其为我们自动最终查找长度:
代码如下:
#include<iostream>
using namespace std;
/*********二分查找(基于数组)**********/
int binSearch(int *A,int e,int lo,int hi)
{
int count=0;//统计查找长度
int mi;
while(lo<hi)
{
mi=(lo+hi)/2;
if(e<A[mi])//深入左半段
{
count++;
hi=mi;
}
else if(e>A[mi])//深入右半段
{
count+=2;
lo=mi+1;
}
else
{
count+=2;
return count;//命中返回
}
}
return count;//查找失败
}
/**************************************/
int main()
{
int a[100];
for(int i=0;i<7;i++)
{
a[i]=i;
}
/*成功查找长度*/
cout<<"各元素成功查找长度:" ;
for(int i=0;i<7;i++)
{
cout<<binSearch(a,i,0,7)<<" ";
}
cout<<endl;
/*失败查找长度*/
cout<<"各元素失败查找长度:";
for(int i=0;i<7;i++)//重新给a赋值,为失败查找做准备a={1,3,5,7,9,11,13}
{
a[i]=1+2*i;
}
for(int i=0;i<8;i++)
{
cout<<binSearch(a,i*2,0,7)<<" ";//查找数列为{0,2,4,6,8,10,12,14}
}
cout<<endl;
return 0;
}
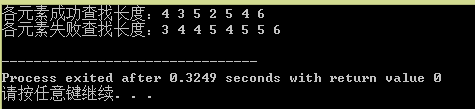
4.在向量模板中实现
将二分查找用于向量中,并与search()接口对接:
我自己写过一篇关于向量模板的文章,此博文章是那篇博文的的分支,是search()接口的其中一个实现。现在我们将二分查找,写成向量的模式与那篇博文中的search()对接。下面给出那篇博文的连接,有兴趣的话,大家可以看一下。
链接:向量模板介绍
代码实现:
template<typename T>
Rank myVector<T>::binSearch(T*A,T const&e,Rank lo,Rank hi) const
{
Rank mi;
while(lo<hi)//每步迭代可能要做两次比较判断,有3个分支
{
mi=(lo+hi)>>1;//以中点为轴点
if(e<A[mi]) hi=mi;//深入前半段[lo,mi)继续查找
else if(A[mi]<e) lo=mi+1;//深入后半段(mi,hi)
else return mi;//在mi处命中
}
if(e<A[mi])
{
return mi-1;//查找失败
}
else
{
return mi;//查找失败
}
}该代码并不严格遵循search()函数的接口规则,即返回有序数列中值不大于e且秩最大的元素。下面改进后的算法会严格遵循search()接口。
5.二分查找改进
改进思路:由于上述算法中向左向右查找的代价不同,向左只需一次判断,而向右只需两次判断,造成了向右查找的代价过高。我们可以想着将mi并入右边,这样就只需一次
判断。可用下图形象表示:

代码实现:
template<typename T>
Rank myVector<T>::binSearch(T*A,T const&e,Rank lo,Rank hi) const
{
Rank mi;
while(lo<hi)//每步迭代可能要做两次比较判断,有3个分支
{
while(lo<hi)
{
Rank mi=(lo+hi)/2;//以中点为轴点,经比较后确定深入
if(e<A[mi])
{
hi=mi;//[lo,mi)
}
else
{
lo=mi+1;//(mi,hi)
}//出口时,A[lo=hi]为大于e的最小元素
}
return --lo;//因此--lo是不大于e的元素的最大秩
}















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









