






很早之前看过YYCache,对于内存缓存一开始是没看懂的,但是后面学过了LRU算法之后,加上自己的实际实践之后,内存缓存已经完全明了。
对于磁盘缓存,确实虽然多次看了源码,但是一致不明所以,直到自己使用SQLLite实现磁盘缓存的功能,回头在看YYCache的思路,才恍然大悟。
以下是YYCache的思路,其实是对原文的精简。YYCache 设计思路
YYCache (GitHub - ibireme/YYCache: High performance cache framework for iOS.)
通常一个缓存是由内存缓存和磁盘缓存组成,内存缓存提供容量小但高速的存取功能,磁盘缓存提供大容量但低速的持久化存储。
内存缓存
内存缓存的设计要更简单些,下面是我调查的一些常见的内存缓存。
NSCache 是苹果提供的一个简单的内存缓存,它有着和 NSDictionary 类似的 API,不同点是它是线程安全的,并且不会 retain key。我在测试时发现了它的几个特点:NSCache 底层并没有用 NSDictionary 等已有的类,而是直接调用了 libcache.dylib,其中线程安全是由 pthread_mutex 完成的。另外,它的性能和 key 的相似度有关,如果有大量相似的 key (比如 “1”, “2”, “3”, …),NSCache 的存取性能会下降得非常厉害,大量的时间被消耗在 CFStringEqual() 上,不知这是不是 NSCache 本身设计的缺陷。
YYMemoryCache 是一个内存缓存,尽量优化了同步访问的性能,用 pthread_mutex_t 来保证线程安全。另外,缓存内部用双向链表和 NSDictionary 实现了 LRU 淘汰算法。
LRU 淘汰算法
- 利用哈希表NSDictionary实现迅速读取, 哈希表中存贮key和封装的Node结构;
- 利用双向链表保证数据按照数据按照访问顺序排列, 这样最少使用的就是在链表尾部;
我们首先使用哈希表进行定位,找出缓存项, 同时这个缓存项也在双向链表,随后将缓存项移动到双向链表的头部,即可在 O(1) 的时间内完成 get 或者 put 操作。具体的方法如下:
对于 get 操作,首先判断 key 是否存在:
- 如果 key 不存在,则返回 nil;
- 如果 key 存在,则 key 对应的节点是最近被使用的节点。
- 通过哈希表定位到该节点, 同时在双向链表中,并将节点移动到双向链表的头部,最后返回该节点的值。
对于 put 操作,首先判断 key 是否存在:
- 如果 key 不存在,使用 key 和 value 创建一个新的节点,在双向链表的头部添加该节点,并将 key 和该节点添加进哈希表中。同时还要判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项;
- 如果 key 存在,则与 get 操作类似,先通过哈希表定位,再将对应的节点的值更新为 value,并将该节点移到双向链表的头部。
上述各项操作中,访问哈希表的时间复杂度为 O(1),在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 O(1)。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 O(1) 时间内完成。
在双向链表的实现中,使用一个伪头部(dummy head)和伪尾部(dummy tail)标记界限,这样在添加节点和删除节点的时候就不需要检查相邻的节点是否存在。

疑问:使用字典和双向链表存储数据,是否是存了2份数据,造成空间浪费?
答:不会造成空间浪费,只是同一个key-value被引用了2次。
比如有一个person对象,在字典中保存了一份,在数组中保存了一份,字典和数组保存的都只是person对象的地址,person对象在内存中仅此一个。修改字典中的person对象,数组中的person也会同步修改,因为这就是同一个对象,只是被不同的指针引用而已。
下面的单线程的 Memory Cache 性能基准测试:
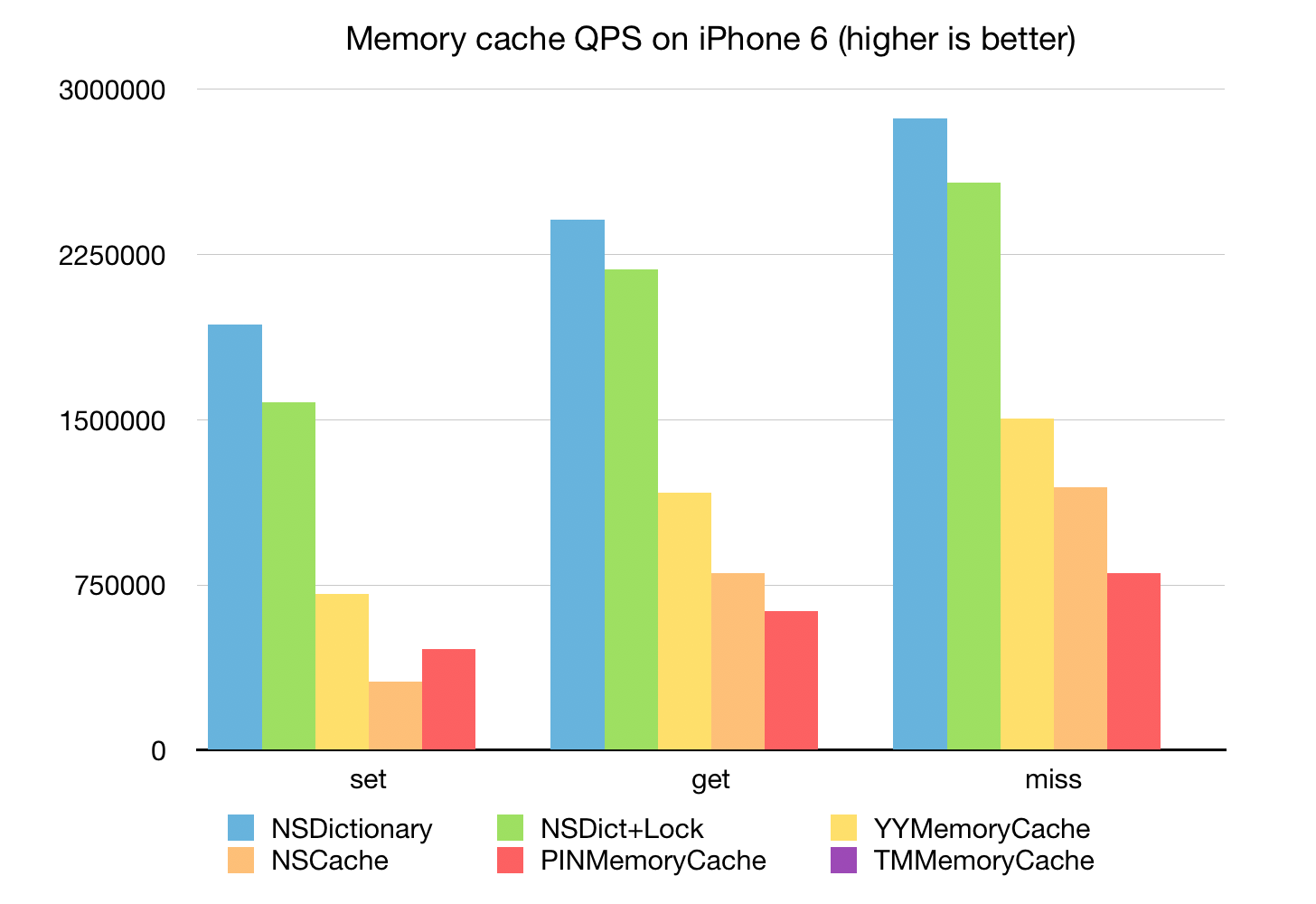
可以看到 YYMemoryCache 的性能不错,仅次于 NSDictionary + OSSpinLock;
NSCache 的写入性能稍差,读取性能不错;
磁盘缓存
为了设计一个比较好的磁盘缓存,我调查了大量的开源库,包括 TMDiskCache、PINDiskCache、SDWebImage、FastImageCache 等,也调查了一些闭源的实现,包括 NSURLCache、Facebook 的 FBDiskCache 等。他们的实现技术大致分为三类:基于文件读写、基于 mmap 文件内存映射、基于数据库。
文件读写
TMDiskCache, PINDiskCache, SDWebImage 等缓存,都是基于文件系统的,即一个 Value 对应一个文件,通过文件读写来缓存数据。他们的实现都比较简单,性能也都相近,缺点也是同样的:不方便扩展、没有元数据、难以实现较好的淘汰算法、数据统计缓慢。
mmap内存映射
FastImageCache 采用的是 mmap 将文件映射到内存。用过 MongoDB 的人应该很熟悉 mmap 的缺陷:热数据的文件不要超过物理内存大小,不然 mmap 会导致内存交换严重降低性能;另外内存中的数据是定时 flush 到文件的,如果数据还未同步时程序挂掉,就会导致数据错误。抛开这些缺陷来说,mmap 性能非常高。
基于数据库
NSURLCache、FBDiskCache 都是基于 SQLite 数据库的。基于数据库的缓存可以很好的支持元数据、扩展方便、数据统计速度快,也很容易实现 LRU 或其他淘汰算法,唯一不确定的就是数据库读写的性能,为此我评测了一下 SQLite 在真机上的表现。iPhone 6 64G 下,SQLite 写入性能比直接写文件要高,但读取性能取决于数据大小:当单条数据小于 20K 时,数据越小 SQLite 读取性能越高;单条数据大于 20K 时,直接写为文件速度会更快一些。这和 SQLite 官网的描述基本一致。另外,直接从官网下载最新的 SQLite 源码编译,会比 iOS 系统自带的 sqlite3.dylib 性能要高很多。基于 SQLite 的这种表现,磁盘缓存最好是把 SQLite 和文件存储结合起来:key-value 元数据保存在 SQLite 中,而 value 数据则根据大小不同选择 SQLite 或文件存储。NSURLCache 选定的数据大小的阈值是 16K;FBDiskCache 则把所有 value 数据都保存成了文件。
YYDiskCache 也是采用的 SQLite 配合文件的存储方式,在 iPhone 6 64G 上的性能基准测试结果见下图。在存取小数据 (NSNumber) 时,YYDiskCache 的性能远远高出基于文件存储的库;而较大数据的存取性能则比较接近了。但得益于 SQLite 存储的元数据,YYDiskCache 实现了 LRU 淘汰算法、更快的数据统计,更多的容量控制选项。
















 135
135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









