







介绍
**自然语言处理(Natural Language Processing,NLP)**是计算机科学领域与人工智能领域中的一个重要方向。它研究的是人类(自然)语言与计算机之间的交互。NLP的目标是让计算机能够理解、解析、生成人类语言,并且能够以有意义的方式回应和操作这些信息。
NLP的任务可以分为多个层次,包括但不限于:
- 词法分析:将文本分解成单词或标记(token),并识别它们的词性(如名词、动词等)。
- 句法分析:分析句子结构,理解句子中词语的关系,比如主语、谓语、宾语等。
- 语义分析:试图理解句子的实际含义,超越字面意义,捕捉隐含的信息。
- 语用分析:考虑上下文和对话背景,理解话语在特定情境下的使用目的。
- 情感分析:检测文本中表达的情感倾向,例如正面、负面或中立。
- 机器翻译:将一种自然语言转换为另一种自然语言。
- 问答系统:构建可以回答用户问题的系统。
- 文本摘要:从大量文本中提取关键信息,生成简短的摘要。
- 命名实体识别(NER):识别文本中提到的特定实体,如人名、地名、组织名等。
- 语音识别:将人类的语音转换为计算机可读的文字格式。
NLP技术的发展依赖于算法的进步、计算能力的提升以及大规模标注数据集的可用性。近年来,深度学习方法,特别是基于神经网络的语言模型,如BERT、GPT系列等,在许多NLP任务上取得了显著的成功。随着技术的进步,NLP正在被应用到越来越多的领域,包括客户服务、智能搜索、内容推荐、医疗健康等。
Bi - RNN 模型
双向循环神经网络(Bidirectional Recurrent Neural Network,Bi - RNN)是循环神经网络(RNN)的一种拓展形式,在处理序列数据时具有独特优势,以下是对它的详细介绍:
结构特点
双向循环神经网络由两个方向相反的循环层构成,一个按时间顺序正向处理序列数据(前向RNN),另一个则逆向处理(后向RNN)。在每个时间步,这两个循环层都分别计算各自的隐藏状态,然后将它们的结果进行合并(如拼接或相加等),作为该时间步的最终隐藏状态输出。这种结构使得模型在处理当前时刻的信息时,既能利用过去的上下文信息(通过前向RNN),又能利用未来的上下文信息(通过后向RNN),从而更全面地捕捉序列中的依赖关系。
工作原理
- 前向传播:前向RNN在时间步 t t t接收输入 x t x_t xt和上一个时间步的隐藏状态 h t − 1 f h_{t - 1}^f ht−1f( f f f表示前向),通过公式 h t f = σ ( W x h f x t + W h h f h t − 1 f + b h f ) h_t^f = \sigma(W_{xh}^f x_t + W_{hh}^f h_{t - 1}^f + b_h^f) htf=σ(Wxhfxt+Whhfht−1f+bhf)计算当前时间步的隐藏状态 h t f h_t^f htf,其中 W x h f W_{xh}^f Wxhf是输入到隐藏层的权重矩阵, W h h f W_{hh}^f Whhf是隐藏层到隐藏层的权重矩阵, b h f b_h^f bhf是偏置项, σ \sigma σ是激活函数(如tanh或ReLU等)。
- 后向传播:后向RNN在时间步 t t t接收输入 x t x_t xt和下一个时间步的隐藏状态 h t + 1 b h_{t + 1}^b ht+1b( b b b表示后向),通过公式 h t b = σ ( W x h b x t + W h h b h t + 1 b + b h b ) h_t^b = \sigma(W_{xh}^b x_t + W_{hh}^b h_{t + 1}^b + b_h^b) htb=σ(Wxhbxt+Whhbht+1b+bhb)计算当前时间步的隐藏状态 h t b h_t^b htb,这里的 W x h b W_{xh}^b Wxhb、 W h h b W_{hh}^b Whhb、 b h b b_h^b bhb分别是后向RNN对应的权重矩阵和偏置项。
- 输出整合:将前向和后向的隐藏状态进行整合,常见的方式是拼接,即 h t = [ h t f ; h t b ] h_t = [h_t^f; h_t^b] ht=[htf;htb],得到最终的隐藏状态 h t h_t ht,该隐藏状态包含了更丰富的上下文信息,后续可用于进一步的计算,如通过全连接层得到模型的输出。
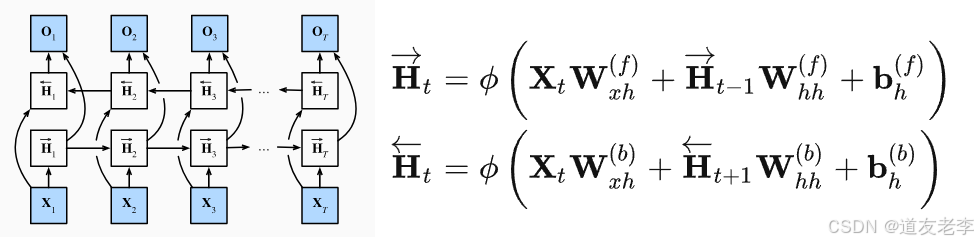
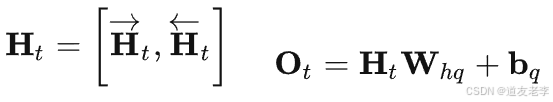
主要用于对句子做特征提取,翻译、填空等。
这组公式用于双向循环神经网络(Bi - RNN)中,分别计算前向和后向的隐藏状态。
符号含义
- 输入与隐藏状态:
- X t \mathbf{X}_t Xt:在时间步 t t t的输入矩阵,维度通常为 [ b a t c h _ s i z e , i n p u t _ s i z e ] [batch\_size, input\_size] [batch_size,input_size],其中 b a t c h _ s i z e batch\_size batch_size是批量大小, i n p u t _ s i z e input\_size input_size是每个样本的特征数量。
- H → t \overrightarrow{\mathbf{H}}_t Ht:前向RNN在时间步 t t t的隐藏状态矩阵,维度为 [ b a t c h _ s i z e , h i d d e n _ s i z e ] [batch\_size, hidden\_size] [batch_size,hidden_size], h i d d e n _ s i z e hidden\_size hidden_size是隐藏层神经元数量。
- H → t − 1 \overrightarrow{\mathbf{H}}_{t - 1} Ht−1:前向RNN在时间步 t − 1 t - 1 t−1的隐藏状态矩阵,维度同样为 [ b a t c h _ s i z e , h i d d e n _ s i z e ] [batch\_size, hidden\_size] [batch_size,hidden_size]。
- H ← t \overleftarrow{\mathbf{H}}_t Ht:后向RNN在时间步 t t t的隐藏状态矩阵,维度是 [ b a t c h _ s i z e , h i d d e n _ s i z e ] [batch\_size, hidden\_size] [batch_size,hidden_size]。
- H ← t + 1 \overleftarrow{\mathbf{H}}_{t + 1} Ht+1:后向RNN在时间步 t + 1 t + 1 t+1的隐藏状态矩阵,维度为 [ b a t c h _ s i z e , h i d d e n _ s i z e ] [batch\_size, hidden\_size] [batch_size,hidden_size]。
- 权重矩阵和偏置项:
- W x h ( f ) \mathbf{W}_{xh}^{(f)} Wxh(f):前向RNN中输入层到隐藏层的权重矩阵,维度为 [ i n p u t _ s i z e , h i d d e n _ s i z e ] [input\_size, hidden\_size] [input_size,hidden_size],负责将输入特征转换到前向隐藏层空间。
- W h h ( f ) \mathbf{W}_{hh}^{(f)} Whh(f):前向RNN中隐藏层到隐藏层的权重矩阵,维度是 [ h i d d e n _ s i z e , h i d d e n _ s i z e ] [hidden\_size, hidden\_size] [hidden_size,hidden_size],用于在前一时刻隐藏状态与当前输入共同作用时,对前向隐藏状态计算进行变换。
- W x h ( b ) \mathbf{W}_{xh}^{(b)} Wxh(b):后向RNN中输入层到隐藏层的权重矩阵,维度为 [ i n p u t _ s i z e , h i d d e n _ s i z e ] [input\_size, hidden\_size] [input_size,hidden_size],将输入特征转换到后向隐藏层空间。
- W h h ( b ) \mathbf{W}_{hh}^{(b)} Whh(b):后向RNN中隐藏层到隐藏层的权重矩阵,维度是 [ h i d d e n _ s i z e , h i d d e n _ s i z e ] [hidden\_size, hidden\_size] [hidden_size,hidden_size],用于在后一时刻隐藏状态与当前输入共同作用时,对后向隐藏状态计算进行变换。
- b h ( f ) \mathbf{b}_{h}^{(f)} bh(f):前向RNN隐藏层的偏置向量,维度为 [ h i d d e n _ s i z e ] [hidden\_size] [hidden_size] ,给前向隐藏层计算增加可学习的偏置值。
- b h ( b ) \mathbf{b}_{h}^{(b)} bh(b):后向RNN隐藏层的偏置向量,维度为 [ h i d d e n _ s i z e ] [hidden\_size] [hidden_size] ,给后向隐藏层计算增加可学习的偏置值。
- 激活函数:
- ϕ \phi ϕ:通常为sigmoid、tanh、ReLU等激活函数,为计算引入非线性,使模型能够学习到复杂的模式。
公式含义
- 前向隐藏状态计算:公式 H → t = ϕ ( X t W x h ( f ) + H → t − 1 W h h ( f ) + b h ( f ) ) \overrightarrow{\mathbf{H}}_t = \phi(\mathbf{X}_t\mathbf{W}_{xh}^{(f)} + \overrightarrow{\mathbf{H}}_{t - 1}\mathbf{W}_{hh}^{(f)} + \mathbf{b}_{h}^{(f)}) Ht=ϕ(XtWxh(f)+Ht−1Whh(f)+bh(f))表示在前向RNN中,时间步 t t t的隐藏状态计算过程。先将当前时间步的输入 X t \mathbf{X}_t Xt与权重矩阵 W x h ( f ) \mathbf{W}_{xh}^{(f)} Wxh(f)相乘,同时将前一时间步的隐藏状态 H → t − 1 \overrightarrow{\mathbf{H}}_{t - 1} Ht−1与权重矩阵 W h h ( f ) \mathbf{W}_{hh}^{(f)} Whh(f)相乘,然后把这两个乘积结果相加,再加上偏置 b h ( f ) \mathbf{b}_{h}^{(f)} bh(f),最后通过激活函数 ϕ \phi ϕ对其进行非线性变换,得到前向RNN在时间步 t t t的隐藏状态 H → t \overrightarrow{\mathbf{H}}_t Ht。
- 后向隐藏状态计算:公式 H ← t = ϕ ( X t W x h ( b ) + H ← t + 1 W h h ( b ) + b h ( b ) ) \overleftarrow{\mathbf{H}}_t = \phi(\mathbf{X}_t\mathbf{W}_{xh}^{(b)} + \overleftarrow{\mathbf{H}}_{t + 1}\mathbf{W}_{hh}^{(b)} + \mathbf{b}_{h}^{(b)}) Ht=ϕ(XtWxh(b)+Ht+1Whh(b)+bh(b))描述了后向RNN在时间步 t t t的隐藏状态计算。先将当前时间步的输入 X t \mathbf{X}_t Xt与权重矩阵 W x h ( b ) \mathbf{W}_{xh}^{(b)} Wxh(b)相乘,同时将后一时间步的隐藏状态 H ← t + 1 \overleftarrow{\mathbf{H}}_{t + 1} Ht+1与权重矩阵 W h h ( b ) \mathbf{W}_{hh}^{(b)} Whh(b)相乘,然后把这两个乘积结果相加,再加上偏置 b h ( b ) \mathbf{b}_{h}^{(b)} bh(b),最后通过激活函数 ϕ \phi ϕ进行非线性变换,得到后向RNN在时间步 t t t的隐藏状态 H ← t \overleftarrow{\mathbf{H}}_t Ht。
这两个公式体现了双向RNN分别从正向和反向对输入序列进行处理,捕捉序列中不同方向的信息依赖关系的过程。
优势
- 上下文信息利用充分:相比单向RNN只能利用过去的信息,双向RNN能够同时利用序列的前后文信息,对于理解序列语义、捕捉长期依赖关系非常有帮助,尤其适用于需要综合考虑前后信息的任务。
- 性能提升:在许多自然语言处理、语音识别等任务中,由于能获取更全面的信息,双向RNN通常能取得比单向RNN更好的性能,提高预测的准确性和可靠性。
应用场景
- 自然语言处理:在命名实体识别任务中,双向RNN可以根据一个词前后的词汇信息更准确地判断它是否为实体以及实体的类型;在机器翻译中,能够更好地理解源语言句子的语义,从而生成更准确的目标语言译文;在情感分析中,结合上下文能更精准地判断文本的情感倾向。
- 语音识别:语音信号是典型的序列数据,双向RNN可以利用语音片段前后的声学特征信息,提高语音识别的精度,更好地处理语音中的连读、变音等现象。
- 时间序列分析:如在股票价格预测、电力负荷预测等任务中,双向RNN可以综合考虑时间序列的历史数据和未来趋势信息,提升预测的准确性。
局限性
- 计算复杂度高:由于存在两个方向的循环计算,双向RNN的计算量是单向RNN的两倍左右,训练时间更长,对硬件资源(如GPU)的要求也更高。
- 内存消耗大:需要存储两个方向的隐藏状态等中间结果,导致内存占用增加,在处理长序列或大规模数据集时,可能会面临内存不足的问题。
- 训练难度增加:复杂的结构使得模型在训练过程中更容易出现梯度消失或梯度爆炸等问题,需要更精细的调参和训练技巧。
代码实现
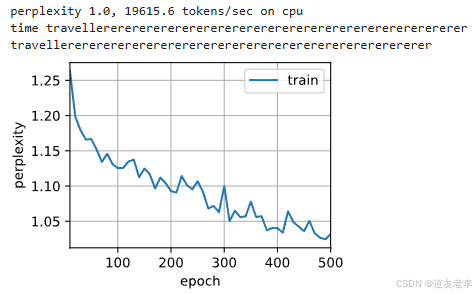
通过设置bidirectional=True把一个普通的RNN变成双向RNN
import torch
from torch import nn
import dltools
batch_size, num_steps = 32, 35
train_iter, vocab = dltools.load_data_time_machine(batch_size, num_steps)
# 通过设置bidirectional=True把一个普通的RNN变成双向RNN.
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
device = dltools.try_gpu()
num_inputs = vocab_size
rnn_layer = nn.RNN(num_inputs, num_hiddens, num_layers, bidirectional=True)
model = dltools.RNNModel(rnn_layer, len(vocab))
model = model.to(device)
# 训练
num_epochs, lr = 500, 1
dltools.train_ch8(model, train_iter, vocab, lr, num_epochs, device)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











