






hashmap
| 时间复杂度 | 空间复杂度 | |
| 数组 | 对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n) | |
| 线性链表 | 对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n) | |
| 二叉树 | O(logn) | |
| 哈希表 | O(1) |
使用了链地址法,也就是数组+链表
HashMap的实现原理
主干是一个Entry数组
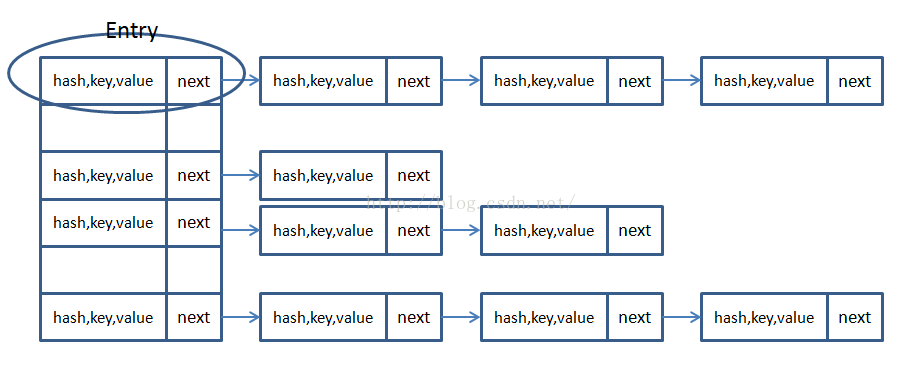
图片来源(6条消息) Java中HashMap底层实现原理(JDK1.8)源码分析_tuke_tuke的博客-CSDN博客_hashmap底层实现原理
HashMap底层实现原理
1.8之前
数组+链表
hahs冲突后使用头插法
1.8之后
数组+链表+红黑树
当发生hash冲突时,插入元素是尾插法,避免了
当链表长度长于一定值(默认为8)时,会转换成红黑树
红黑树的特性: (6条消息) HashMap底层实现原理解析_苟且偷生的程序员的博客-CSDN博客_hashmap底层实现原理
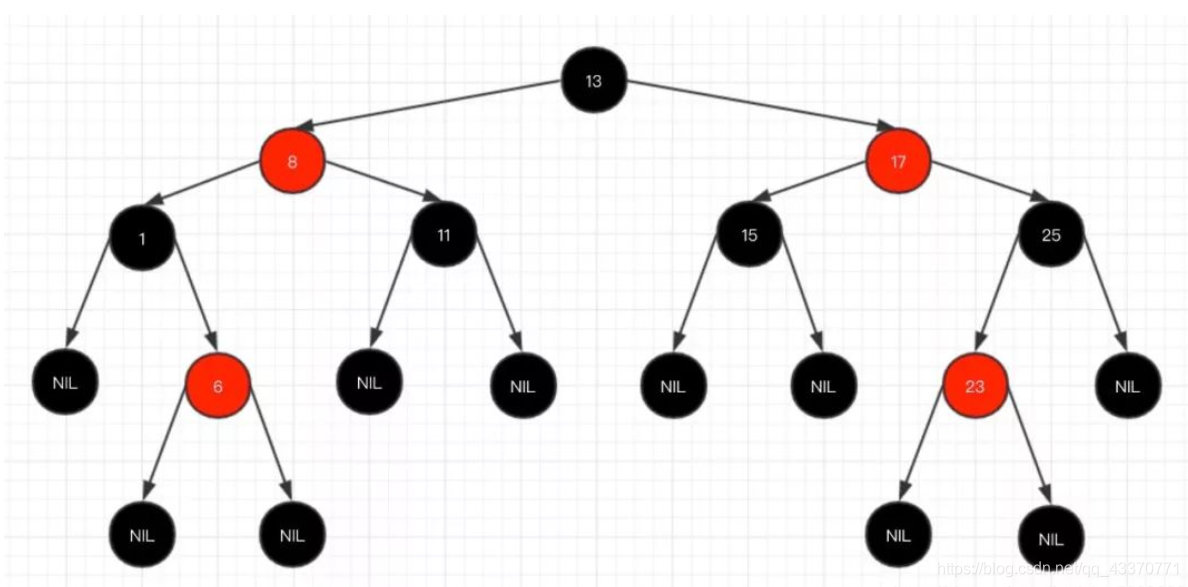
1、每个节点要么是红色,要么是黑色,但根节点永远是黑色的;
2、每个红色节点的两个子节点一定都是黑色;
3、红色节点不能连续(也即是,红色节点的孩子和父亲都不能是红色);
4、从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点;
5、所有的叶节点都是是黑色的(注意这里说叶子节点其实是上图中的 NIL 节点);
为什么Hashmap的链表长度是16或者2的幂 比如15 是1111,要插入的值与它进行按位与,可以让所有的index值结果都可以出现,假如是1001的话,可能就有的值根本不会用到,不符合hash算法均匀分布的原则
ConcurrentHashMap 和 HashMap的区别
HashMap是线程不安全的
ConcurrentHashMap是线程安全的
JDK1.7 数据结构是有一个Segment数组和多个HashEntry组成,如图 来自 多线程-ConcurrentHashMap(JDK1.8) - 小路不懂2 - 博客园 (cnblogs.com)
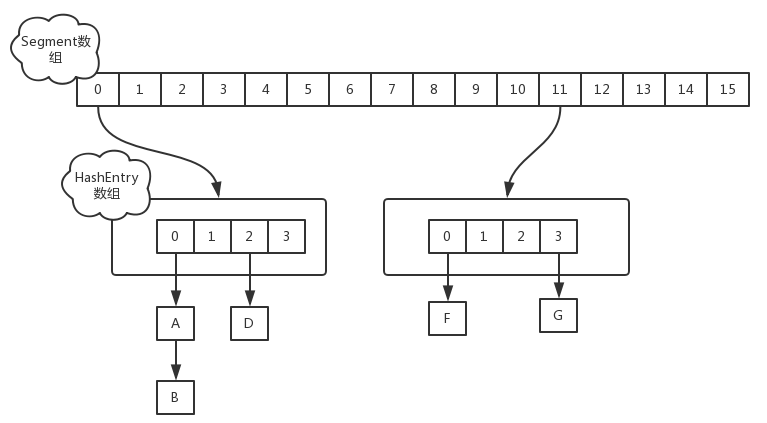
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,
每一个segment存储的是HashEntry数组+链表 .分多少段是开始就确定的,后期不能在扩容,也就是并发度不能改变,但是单个segment里面的数组是可以扩容的
put 是要进行两次hash去定位数据的存储位置
Segment实现了ReentrantLock,第一次先key的hash来定位segment的位置,如果该segment还没初始化,就通过CAS操作进行赋值,然后进行第二次hash操作找到entry位置,通过ReentrantLock的tryLock()方法去获取锁,然后插入相应位置,如果锁被其他线程获取,当前线程通过自旋方式去继续调用tryLock()去获取锁,超过指定次数就挂起,等待唤醒
get 第一次先定位到segment的位置,然后再hash定位到hashEntry位置,遍历该HashEntry下的链表进行对比
size 计算长度
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j) ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) { sum += seg.modCount; int c = seg.count; if (c < 0 || (size += c) < 0)
overflow = true;
} }
if (sum == last) break;
last = sum; } }
finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}也就是说,1.先通过不加锁的方式去多次获得一下size,最多三次,比较一致就认为没有元素加入,计算结果准确
2.如果不一致,就会给每个Segment加上锁,然后计算size返回
JDK1.8
不再使用segment ,而是Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作.后续并发度大小依赖于table数组的大小
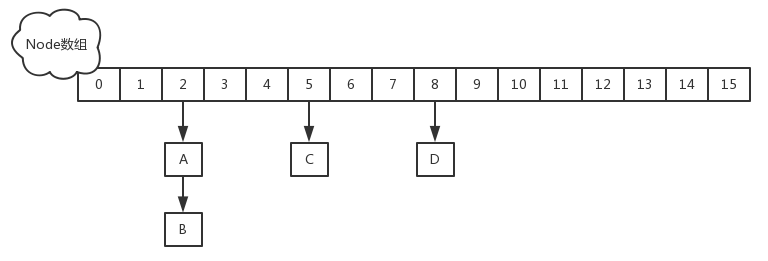
Node 是ConcurrentHashMap存储结构的基本单元,实现了Map.Entry接口,用于存储数据,其中的value和next属性设置了volatile同步锁,不允许调用setValue直接改变Node的value,增加了find方法辅助map.get()
TreeNode 继承于Node ,实现红黑树
TreeBin 从字面可以理解为存储树形结构的容器
ForwardingNode 一个用于链接2个table的节点类
JDK1.8中也是锁分离思想,只是锁住一个Node,而不是JDK7中的Segment















 5713
5713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









