







--第一单元 select 语句
oracle开发的金科玉律
--1 oracle底层的标准产品只能查询,不能更新、删除、增加,因为背后的各个表关系错综复杂
-- 2 熟悉oracle 数据库官方文档,尽量使用oracle数据库的方法解决复杂问题
--数据库设计的三原则
--P:分布性
--A:高可用性
--C:一致性
--权限分配原则:最小权限原则
--数据库连接在中间键开发中不推荐使用
--查询类型
--列查询SELECT employee_id FROM employees;
--行查询
SELECT * FROM employees;
--多表连接查询
SELECT emp.* , dep.* FROM employees emp ,departments dep
WHERE emp.department_id = dep.department_id;
--设计查询语句时注意
--1逻辑清晰、易于理解
--2提高效率、优化查询
--设计查询思路:在哪些表(from) 以什么条件(where) 查询什么字段(select)
--oracle 关系型数据库的多个表呈现 星型结构
--主表的链接作用巨大
select table1.column1--主表(包含众多外表的主键)
, table2.column2--次表
from table1,table2
;
--oracle对类型转换的处理:
--oracle优化器:CBO(基于开销的优化)、RBO(基于关系的优化),默认采用CBO
--oracle 优化器会进行数据采集,统计分析,会自动修改连接的顺序或匹配的顺序,在进行数据类型的转换兼容时,顺序特别关键。
--eg:“123”(number)--“123”(varchar2):ok
--“123”(varchar2)--“123”(number):maybe ok,or not
--*
--使用*的弊端:1数据冗余 2不易于扩展(所需要的列不同:次序、数量、)
--别名的使用问题:
--建议表尽量使用别名,别名的好处:简短、表意,别名双引号
select last_name as name --标准化写法,对于用户理解产品有好处
,commission_pct comm --oracle优化写法的,对于效率有帮助,项目的开发推荐使用,简洁,高效
from employees
;
--distinct
SELECT DISTINCT emp.* FROM employees emp;
--备注:distinct 作用:删除表中重复部分,根据distinct后面连接内容进行比较,如distinct employee_id
--则根据employee_id判断是否重复,如果为distinct employee_id ,dempartment_id 则根据employee_id 与dempartment_id
--综合起来进行比较,即employee_id ,dempartment_id需要完全相同才是为重复,才会去除
--慎用distinct,distinct由于会将该记录与全表其余记录逐个进行比较,共有n*n次,会有很大的性能问题
--Distinct会将所有表先进行排序,有可能导致内存不够,会在磁盘创建临时表空间,使得效率急剧降低。使用Distinct的情况:查询的表的行很少
--内存(SGA)—效率高,速度高:缓存区、排序区
--磁盘—效率低,速度低:DBF-分配内存、TEMP(临时表空间)
--null
SELECT emp.*
FROM employees emp
WHERE emp.department_id IS NULL;
--null 表示不可用、未赋值、不知道、不适用,既不是0也不是空
--和null进行数字运算,结果为空,和null进行逻辑运算,得根据null不知道的本质,推导出结果
--is null 是数据库提供的函数,用于判断是否为null
--eg: a.x=b.y or(a.x is null and b.y is null)
--别名
SELECT emp.employee_id AS "EID"
,emp.last_name ename
,emp.job_id "job"
,emp.job_id AS job
FROM employees emp;
--备注: 带as 、不带as 都能作为别名适用,“”表示别名大小写敏感,大小写固定,推荐不带as ,简洁
--字符串连接操作符||
SELECT last_name || ' works in ' || department_id AS "Personal info"
FROM employees;
--备注:字符串连接操作符将各个属性串联起来作为完整语句适用
--第二单元 条件限制和排序
--条件类型:关联条件、过滤条件
--比较操作符 =、>、>=、<、<=、<>、!=、between...and..、in、like、is null
--between ..and ..
SELECT *
FROM employees
WHERE salary BETWEEN 10000 AND 20000
AND NOT department_id IS NULL;
SELECT *
FROM employees
WHERE salary BETWEEN 10000 AND 20000
AND department_id IS NOT NULL;
--备注:数据库语句支持非运算,between...and 与 < ...and >... 或 >...and <...的查询效果与查询效率是一样的
--oracle会自带优化器,优化器会根据SQL语句形成特定的查询路径,查询路径不同,会有效率的不同,但高版本的oracle已经
--对一些具有相同功能的SQL语句进行优化
--IN
SELECT employee_id
,manager_id
FROM employees
WHERE manager_id IN (100
,101
,102);
SELECT employee_id
,manager_id
FROM employees
WHERE manager_id NOT IN (100
,101
,102
,103
,104);
--备注:IN 作用:有限范围的匹配,IN的原理过程:一般会将每条记录,与in中的数据逐个进行比较配对,查询的次数为N*M
--(M即为in范围的数据个数),由此可知in中的数据不能过多,一旦过多,会严重影响性能,oracle也会自动提示
--模糊匹配 like % 代表0或多个字符 _代表一个单个字符
SELECT employee_id
,last_name
FROM employees
WHERE last_name LIKE 'K%';
--备注:有些特殊字符,可以用转义符来表示,如‘\%’
--逻辑操作符 and or not
SELECT emp1.employee_id
,emp1.salary
FROM employees emp1
,employees emp2
WHERE emp1.salary = emp2.salary
AND emp1.employee_id != emp2.employee_id;
--order by
SELECT employee_id
,salary
FROM employees
ORDER BY salary;
SELECT employee_id
,salary
FROM employees
ORDER BY salary ASC;
SELECT employee_id
,salary
FROM employees
ORDER BY salary DESC;
SELECT employee_id
,salary
FROM employees
ORDER BY salary DESC
,employee_id;
--order by 后面若没有指名,默认升序排序
--伪表 dual 只有一行一列,供开发人员查询系统时间等使用
--第三单元
--函数类型:单行函数、多行函数
--字符函数、数值函数、日期函数、转换函数、通用函数
--大小写转换函数
SELECT employee_id
,lower(first_name)
,upper(last_name)
,initcap(email)
FROM employees;
--备注:LOWER(first_name) 转换为小写 ;UPPER(last_name)转换为大写,INITCAP(email),单词首字母大写
--字符串操作函数
SELECT concat('Hello'
,'World')
,substr('ABCDEFGHIJK'
,1
,5)
,length('ABCDEFGHIJK')
,instr('ABCDEFGHIJK'
,'E')
,lpad('ABCDEF'
,10
,'*')
,rpad('ABCDEF'
,10
,'*')
,TRIM('A' FROM 'ABCDEFGHIJK')
,TRIM('K' FROM 'ABCDEFGHIJK')
,TRIM('E' FROM 'ABCDEFGHIJK')
,TRIM(' ABCDEFGHIJK ')
,TRIM('ABCDE FGHIJK')
FROM dual;
--CONCAT('Hello','World') 拼接函数,将两组字符串组合在一起
--SUBSTR('ABCDEFGHIJK',1,5),取指定字符串中从第二个参数之后,连续第三个参数
--LENGTH('ABCDEFGHIJK'),取指定字符串的长度
--INSTR('ABCDEFGHIJK','E'),取第二个参数在第一个参数的位置
--LPAD('ABCDEF',10,'*'),第二个参数说明长度,如果第一个参数长度不够,则向右靠齐,不足的地方补齐
--RPAD ('ABCDEF',10,'*'),第二个参数说明长度,如果第一个参数长度不够,则向左靠齐,不足的地方补齐
--TRIM('A' FROM'ABCDEFGHIJK'),第一个参数需在第二个参数的左右最外边,才能截取,否则没有效果
--TRIM('K' FROM'ABCDEFGHIJK')
--TRIM('E' FROM'ABCDEFGHIJK')
--TRIM (' ABCDEFGHIJK '),会自动将参数最外边的空格截取掉
--TRIM ('ABCDE FGHIJK')
--数字操作函数
SELECT round(123.456
,2)
,round(123.456
,-2)
,trunc(123.456
,2)
,MOD(1600
,300)
FROM dual;
--ROUND(123.456,2) 依据四舍五入,2,小数点后2位之后的数进行取舍
--ROUND(123.456,-2)依据四舍五入,2,小数点前2位之前的数进行取舍
--TRUNC (123.456,2)直接截断小数点后2位自后
--MOD(1600,300) 取余
--dual:oracle提供的伪列,帮助用户了解系统属性,没有实际意义,用户可以借助daul进行预算
--日期函数
SELECT months_between(to_date('1990-05-08'
,'yyyy-mm-dd')
,to_date('1991-05-08'
,'yyyy-mm-dd'))
,add_months(to_date('1990-01-01'
,'yyyy-mm-dd')
,5)
,next_day(to_date('1990-01-01'
,'yyyy-mm-dd')
,6)
,next_day(to_date('1990-01-01'
,'yyyy-mm-dd')
,1)
,last_day(to_date('1990-01-01'
,'yyyy-mm-dd'))
,round(to_date('1990-05-12'
,'yyyy-mm-dd')
,'year')
,round(to_date('1990-05-12'
,'yyyy-mm-dd')
,'month')
,round(to_date('1990-05-12'
,'yyyy-mm-dd')
,'day')
,trunc(to_date('1990-05-12'
,'yyyy-mm-dd')
,'year')
,trunc(to_date('1990-05-12'
,'yyyy-mm-dd')
,'month')
,trunc(to_date('1990-05-12'
,'yyyy-mm-dd')
,'day')
FROM dual;
--sysdate 日期的格式是按照客户端用户设置的格式
--1. 日期时间间隔操作
--当前时间减去7分钟的时间
select sysdate,sysdate - interval '7' MINUTE from dual
--当前时间减去7小时的时间
select sysdate - interval '7' hour from dual
--当前时间减去7天的时间
select sysdate - interval '7' day from dual
--当前时间减去7月的时间
select sysdate,sysdate - interval '7' month from dual
--当前时间减去7年的时间
select sysdate,sysdate - interval '7' year from dual
--时间间隔乘以一个数字
select sysdate,sysdate - 8 *interval '2' hour from dual
--2.日期到字符操作
select sysdate,to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual
select sysdate,to_char(sysdate,'yyyy-mm-dd hh:mi:ss') from dual
select sysdate,to_char(sysdate,'yyyy-ddd hh:mi:ss') from dual
select sysdate,to_char(sysdate,'yyyy-mm iw-d hh:mi:ss') from dual
--参考oracle的相关关文档(ORACLE901DOC/SERVER.901/A90125/SQL_ELEMENTS4.HTM#48515)
3. 字符到日期操作
select to_date('2003-10-17 21:15:37','yyyy-mm-dd hh24:mi:ss') from dual
具体用法和上面的to_char差不多。
4. trunk/ ROUND函数的使用
select trunc(sysdate ,'YEAR') from dual
select trunc(sysdate ) from dual
select to_char(trunc(sysdate ,'YYYY'),'YYYY') from dual
--5.oracle有毫秒级的数据类型
--返回当前时间年月日小时分秒毫秒
select to_char(current_timestamp(5),'DD-MON-YYYY HH24:MI:SSxFF') from dual;
--返回当前时间的秒毫秒,可以指定秒后面的精度(最大=9)
select to_char(current_timestamp(9),'MI:SSxFF') from dual;
--转换函数
--数据类型转换
--1 显性数据类型转换
--2 隐形数据类型转换
--to_char(date,'format_model')
SELECT to_date('2014-7-25'
,'yyyy-mm-dd')
,to_number(to_char(SYSDATE
,'yyyymmdd'))
,to_char(67)
,to_char(SYSDATE)
,to_char(SYSDATE
,'YEAR')
,to_char(SYSDATE
,'MM')
,to_char(SYSDATE
,'DD')
,to_char(SYSDATE
,'HH24:MI:SS AM')
,to_char(SYSDATE
,'DDspth')
,to_char(SYSDATE
,'DD "of" MONTH yyyy') AS hiredate
,to_char(SYSDATE
,'fmDD "of" MONTH yyyy') AS hiredate
,to_char(SYSDATE
,'DD "of" MONTH YEAR') AS hiredate
FROM dual;
--to_char(number,'format_model')
--9 表示一个数字
--0 强制显示0
--$ 放一个美元占位符
--L 使用浮点本地币种符号
--. 显示一个小数点占位符
--, 显示一个千分位占位符
ALTER session SET nls_currency = '¥';
SELECT to_char(salary
,'L99,999.00') salary
FROM employees
WHERE employee_id = 100;
ALTER session SET nls_currency = '$';
SELECT to_char(salary
,'L99,999.00') salary
FROM employees
WHERE employee_id = 100;
-- to_number()
TO_NUMBER应用 正确与否
select TO_NUMBER('4456') from dual; √
select TO_NUMBER('$4,456','$9,999' )from dual; √
select TO_NUMBER('$4,456,455.000','$9,999,999,999,999.999' )from dual; √
select to_date('2011-2-22','YYYY-MM-DD') from dual;
select to_date('2-22-2011','MM-DD-YYYY') from dual;
select to_date('2011-FEB-22','YYYY-MON-DD') from dual;
--NVL (expr1, expr2) 如果expr1为空,这返回expr2
--NVL2 (expr1, expr2, expr3) 如果expr1为空,这返回expr3(第2个结果)否则返回expr2
--NULLIF (expr1, expr2) 如果expr1和expr2相等,则返回空 如果expr1不为空,则返回expr1,结束;否则计算expr2,直到找到
--COALESCE (expr1, expr2, ..., exprn) 一个不为NULL的值 或者如果全部为NULL,也只能返回NULL了
--备注:上述参数的类型都需要相同,或者可以转换为相同类型的
SELECT emp.employee_id
,nvl(emp.commission_pct
,0)
,nvl2(emp.department_id
,emp.department_id
,007)
FROM employees emp;
--多路选择函数
SELECT emp.employee_id
,emp.job_id
,CASE emp.employee_id
WHEN 100 THEN
'max'
WHEN 101 THEN
'max'
WHEN 102 THEN
'max'
ELSE
'min'
END "RANK"
FROM employees emp;
SELECT emp.employee_id
,emp.job_id
,decode(emp.employee_id
,100
,'max'
,101
,'max'
,102
,'max'
,'min') "RANK"
FROM employees emp
WHERE emp.employee_id < 200;
--第4单元 多表关联查询
--在执行多表查询时,若未指定链接条件,则结果返回是个笛卡尔乘积
--oracle 定义的链接查询
-- 1.等于链接
-- 2.不等链接
-- 3.外连接(可细分为 左外连接、右外连接)
-- 4.自链接
--等于连接
SELECT emp.employee_id
,dep.department_id
FROM employees emp
,departments dep
WHERE emp.department_id = dep.department_id
;
--左外连接
SELECT emp.employee_id
,dep.department_id
FROM employees emp
,departments dep
WHERE emp.department_id = dep.department_id(+)
;
--右外连接
SELECT emp.employee_id
,dep.department_id
FROM employees emp
,departments dep
WHERE emp.department_id(+) = dep.department_id
;
--自链接
SELECT table1.column
,table2.column
FROM table1
,table1 table2
WHERE table1.column1 = table2.column2;
--SQL1999 链接
SELECT table1.column
,table2.column
FROM table1
CROSS JOIN table2 | NATURAL
JOIN table2 |
JOIN table2
USING (column_name) |
JOIN table2
ON (table1.column_name = table2.column_name) |
LEFT |
RIG |
FULL OUTER JOIN table2
ON (table1.column_name = table2.column_name);
--1 交叉连接 :交叉连接相当于没有连接条件的多表关联查询,结果是个笛卡尔乘积。
--2 自然链接 :相当于Oracle的“等于连接”,只不过是让系统自己去找两张表中字段名相同的字段作为“等于连接”条件;(注意如果两个表中有相同的列名,但字段类型不一样,这会引发一个错误)
--3 using子句
SELECT e.employee_id, e.last_name, d.location_id
FROM employees e JOIN departments d
USING (department_id) ;
--4 内连接:相当于Oracle的“等于链接“
SELECT employee_id, city, department_name
FROM employees e
INNER JOIN departments d ON d.department_id = e.department_id
INNER JOIN locations l ON d.location_id = l.location_id;
--5 外连接(全外连接、左外连接、右外连接)
--左外连接
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
LEFT OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
--右外连接
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
RIGHT OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
--全外连接
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
FULL OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
SELECT emp.*
FROMemployees emp
--WHERE ROWNUM =1 将第一行显示出来 先将表进行关联,再判断是否满足条件,如果是,则显示出来,如果不是,则过滤掉
--WHERE ROWNUM =10 不显示任何结果
--WHERE ROWNUM <=10 显示前10条记录
;
--第5 单元 分组计算函数和group by 子句
--常用的分组函数
--1、求和(SUM)
--2、求平均值(AVG)
--3、计数(COUNT)
--4、求标准差(STDDEV)
--5、求方差(VARIANCE)
--6、求最大值(MAX)
--7、求最小值(MIN)
--COUNT(*) 返回满足选择条件的所有行的行数,包括值为空的行和重复的行
--COUNT(expr) 返回满足选择条件的且表达式不为空行数。
--COUNT(DISTINCT expr) 返回满足选择条件的且表达式不为空,且不重复的行数。
--分组函数遇到null,直接忽略
SELECT AVG(salary)
,MAX(salary)
,MIN(salary)
,SUM(salary)
FROM employees
WHERE job_id LIKE '%REP%';
SELECT MIN(hire_date)
,MAX(hire_date)
FROM employees;
SELECT AVG(salary) FROM employees
GROUP BY department_id ;
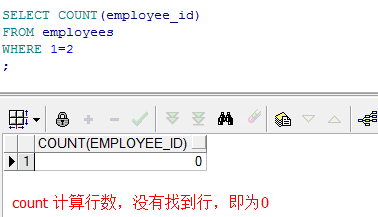
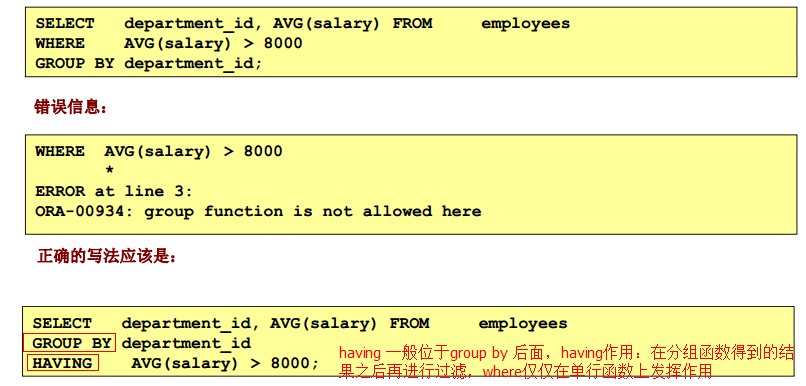
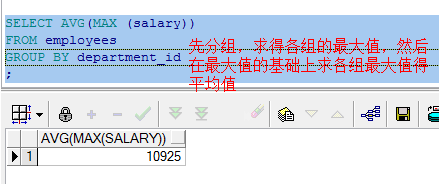
--最高部门的平均薪水
--having 下可以直接使用分组函数得到的结果
SELECT emp.department_id
,AVG(emp.salary)
FROM employees emp
GROUP BY emp.department_id
HAVING AVG(emp.salary) = (SELECT MAX(AVG(salary))
FROM employees
GROUP BY department_id);
--第6单元 子查询
SELECT employee_id
,last_name
,job_id
,salary
FROM employees
WHERE salary < ANY (SELECT salary
FROM employees
WHERE job_id = 'IT_PROG')
AND job_id <> 'IT_PROG';
--第7单元DML 语句
--插入语句
--方式一:写出表名+列名
--注意:在“列”中,对于不允许为NULL的列,必须写出来;对于允许为NULL的列,可以不写出来
--在Value中,对于列中未写出来的列,默认赋予NULL值
INSERT INTO departments (department_id,department_name )
VALUES (30, 'Purchasing' );
--方式二:仅写出表名
--注意:在Value中必须对应写出每个列的值,即是是允许NULL的字段,也必须显式的给出NULL
INSERT INTO departments
VALUES (100, 'Finance', NULL, NULL);
--方式三:从另一个表中Copy 一行
--语法:INSERT INTO table[ column(, column) ] subquery;
--注意:在这种方式下,不要使用VALUES 关键字
INSERT INTO sales_reps
(id
,NAME
,salary
,commission_pct)
SELECT employee_id
,last_name
,salary
,commission_pct
FROM employees
WHERE job_id LIKE '%REP%';
--更新语句
方式一:更新符合条件的行中某些列为具体的值
UPDATE employees
SET department_id = 70
WHERE employee_id = 113;
方式二:使用子查询的结果作为更新后的值
UPDATE employees
SET job_id =
(SELECT job_id
FROM employees
WHERE employee_id = 205)
,salary =
(SELECT salary
FROM employees
WHERE employee_id = 205)
WHERE employee_id = 114;
--删除语句
DELETE FROM departments
WHERE department_name = 'Finance';
--删除表中所有数据
DELETE FROM copy_emp;
--merge 根据条件进行查询,如果存在记录则更新,如果不存在则插入
MERGE INTO copy_emp c
USING employees e
ON (c.employee_id = e.employee_id)
WHEN MATCHED THEN
UPDATE SET
c.first_name = e.first_name,
c.last_name = e.last_name,
...
c.department_id = e.department_id
WHEN NOT MATCHED THEN
INSERT VALUES(e.employee_id, e.first_name, e.last_name,
e.email, e.phone_number, e.hire_date, e.job_id,
e.salary, e.commission_pct, e.manager_id,
e.department_id);
--第8单元 事务控制
--ORACLE数据库通过事务来控制数据的一致性,当用户进程或者系统崩溃的时候,事务可提供用户更多的的灵活性和控制,以确保数据的一致性。
--当如下事件发生是,会隐式的执行Commit动作:
--1、数据定义语句被执行的时候,比如新建一张表:Create Table …
--2、数据控制语句被执行的时候,比如赋权GRANT …( 或者DENY)
--3、正常退出iSQL*Plus 或者PLSQL DEVELOPER, 而没有显式的执行COMMIT 或者ROLLBACK语句 。-
--当如下事件发生时,会隐式执行Rollback 动作:
--1、非正常退出iSQL*Plus , PLSQL DEVELOPER, 或者发生系统错误。
--在Commit 或者Rollback前后数据的状态:
--1、在数据已经被更改,但没有Commit前 ,被更改记录处于被锁定状态,其他用户无法进行更改;
--2、在数据已经被更改,但没有Commit前 ,只有当前Session的用户可以看到这种变更 ,其他Session的用户看不到数据的变化。
--3、在数据已经被更改,并且被Commit后,被更改记录自动解锁,其他用户可以进行更改;
--4、在数据已经被更改,并且被Commit后,其他Session的用户再次访问这些数据时,看到的是变化后的数据。
--当有用户修改数据时,Oracle先把那部分原始数据备份到回滚段,在Commit之前,其他Session用户读到的这部分数据是回滚段上的; 在提交之后,回滚段被释放
--第9单元 锁
--Oracle中的锁的主要作用就是:防止 并发事务对相同的资源(所谓资源是指 表、行、共享的数据结构、
--数据字典行等)进行更改的时候,相互破坏。
--锁有既有隐式的,也有显式的;
--隐式枷锁:某用户对某一批数据进行更改,而未提交之前,Oracle会隐式的进行加锁;
--显示枷锁
Select … from TableA Where … For UPDATE NOWAIT
--查锁
SELECT a.*
,c.type
,c.lmode
FROM v$locked_object a
,all_objects b
,v$lock c
WHERE a.object_id = b.object_id
AND a.session_id = c.sid
AND b.object_name = 'TESTTAB3'
--第10单元 数据库对象--表
--数据库表中的数据类型
--VARCHAR2(size) 可变长字符串
--CHAR(size) 定长字符串
--NUMBER(p,s) 可变长数值
--DATE 日期时间
--LONG 可变长大字符串,最大可到2G
--CLOB 可变长大字符串数据,最大可到4G
--RAW and LONG RAW 二进制数据
--BLOB 大二进制数据,最大可到4G
--BFILE 存储于外部文件的二进制数据,最大可到4G
--ROWID 64进制18位长度的数据,用以标识行的地址
--TIMESTAMP 精确到分秒级的日期类型(9i以后提供的增强数据类型)
--INTERVAL YEAR TO MONTH 表示几年几个月的间隔(9i以后提供的增强数据类型-极其少见)
--INTERVAL DAY TO SECOND 表示几天几小时几分几秒的间隔(9i以后提供的增强数据类型-极其少见)
CREATE TABLE time_example
(order_date1 TIMESTAMP,
order_date2 TIMESTAMP WITH TIME ZONE,
order_date3 TIMESTAMP WITH LOCAL TIME ZONE);
INSERT INTO time_example VALUES('15-NOV-00 09:34:28','15-NOV-00 09:34:28 AM -8:00',
'15-NOV-00 09:34:28 AM');
CREATE TABLEA as select * from tableb;
CREATE TABLEA as select * from tableb where 1=2;
--添加列:
ALTER TABLE table
ADD (column datatype[DEFAULT expr]
[, column datatype]...);
--更改列:
ALTER TABLE table
MODIFY (column datatype[DEFAULT expr]
[, column datatype]...);
--删除列:
ALTER TABLE table
DROP (column);
--删除表:
DROP TABLE tableName;
--注意:表被删 除后,任何依赖于这张表的视图、Package等数据库对象都自动变为无效:
--更改表名:
RENAME oldtablename to newtableName;
--一次性清空一张表中的所有内容,但保留表结构:
TRUNCATE TABLE tableName;
--注意TRUNCATE 与DELETE FROM table 的区别:1)没有Rollback机会2)HWM标记复位
--hwm 帮助寻找可供插入的空余空间
--第11单元:数据库对象--约束
--oracle 数据库使用“约束”来阻止对数据库表中数据的不合法的‘增删改’动作
--常用约束
--NOT NULL (非空约束)
--UNIQUE (唯一性约束)
--PRIMARY KEY (主键约束)
--FOREIGN KEY (外键约束)
--CHECK (自定义约束)
--创建表的时候创建约束
CREATE TABLE employees(employee_id NUMBER(6)
,first_name VARCHAR2(20)
,.. . job_id VARCHAR2(10) NOT NULL
,CONSTRAINT emp_emp_id_pk primary key(employee_id));
--单独创建约束
ALTER TABLE cux_les_je_lines add CONSTRAINT cux_les_je_lines_pk primary key(je_line_id);
CREATE TABLE employees(employee_id NUMBER(6)
,last_name VARCHAR2(25) NOT NULL
,salary NUMBER(8
,2) CONSTRAINT emp_salary_min CHECK(salary > 0)
,email VARCHAR2(25)
,commission_pct NUMBER(2
,2)
,hire_date DATE CONSTRAINT emp_hire_date_nn NOT NULL
,CONSTRAINT emp_dept_fk foreign key(department_id) references departments(department_id)
,CONSTRAINT emp_email_uk UNIQUE(email)), CONSTRAINT dept_id_pk primary key(employee_id));
--外键约束类型:
-- REFERENCES: 表示列中的值必须在父表中存在
-- ON DELETE CASCADE: 当父表记录删除的时候自动删除子表中的相应记录.
-- ON DELETE SET NULL: 当父表记录删除的时候自动把子表中相应记录的值设为NULL
--删除约束:
ALTER TABLE employees drop CONSTRAINT emp_manager_fk;
ALTER TABLE departments drop primary key cascade;
ALTER TABLE employees disable CONSTRAINT emp_emp_id_pk cascade;
ALTER TABLE employees enable constraintemp_emp_id_pk;
CREATE TABLE test1(pk NUMBER primary key
,fk NUMBER
,col1 NUMBER
,col2 NUMBER
,CONSTRAINT fk_constraint foreign key(fk) references test1
,CONSTRAINT ck1 CHECK(pk > 0 AND col1 > 0)
,CONSTRAINT ck2 CHECK(col2 > 0));
ALTER TABLE test1 drop(pk);
--级联删除,比如你删除某个表的时候后面加这个关键字,会在删除这个表的同时删除和该表有关系的其他对象
ALTER TABLE test1
DROP (pk) CASCADE CONSTRAINTS;
--参考原文:http://blog.csdn.net/kadwf123/article/details/8067381
--查询系统存在的约束
SELECT constraint_name
,constraint_type
,search_condition
FROM user_constraints
WHERE table_name = 'EMPLOYEES';
--第12单元 数据库对象-视图
--为复杂查询的结果集创建视图,为以后的查询提供方便
--简单视图举例:
CREATE view empvu80 AS
SELECT employee_id
,last_name
,salary
FROM employees
WHERE department_id = 80;
--复杂视图举例:
CREATE view dept_sum_vu(NAME, minsal, maxsal, avgsal) AS
SELECT d.department_name
,MIN(e.salary)
,MAX(e.salary)
,AVG(e.salary)
FROM employees e
,departments d
WHERE e.department_id = d.department_id
GROUP BY d.department_name;
drop view empvu80;
--TOP-N 查询
SELECT column_list
,rownum
FROM (SELECT column_list
FROM TABLE
ORDER BY top - n_column)
WHERE rownum <= n;
--第13单元 数据库对象-序列、索引、同意词
--序列:具有唯一性、自增长类型的数据库对象,每获取一次,就自动增长,保证下次获取时肯定不一样的值
--创建序列
CREATE sequence sequence increment BY n START WITH n {maxvalue n | nomaxvalue} {minvalue n | nominvalue} {cycle | nocycle} {cache n | nocache} ;
--序列使用举例
INSERT
INTO departments(department_id
,department_name
,location_id) VALUES(dept_deptid_seq.nextval
,'Support'
,2500);
SELECT dept_deptid_seq.currval
FROM dual;
--更改序列定义:
ALTER sequence dept_deptid_seq increment BY 20 maxvalue 999999 nocache nocycle;
--删除序列:
drop sequence dept_deptid_seq;
--索引:索引是有序的,可以使用诸如二分法子类的方法加快查询,而不是做全表扫描
--索引创建举例:
CREATE INDEX emp_last_name_idx ON employees(last_name);
--建立索引的条件
--查询条件使用的列范围跨度很大,要获取的数据量占整个表的数据总量小于4%
--不适合建立索引的情况:
--1被查询的表本身很小,数据库先是根据索引找到数据所在的位置,然后再在数据的位置提取数据,如果数据本身很小,全表扫描很快,建立索引需要二次扫描,消耗时间
--2要获取的数据量超过整个表的4%
--3数据表需要经常被更新,建立的索引页需要经常被更新,会影响性能
--同义词:简化写法
CREATE synonym table1 FOR b.table1
--第14 单元 控制用户权限
--创建用户
CREATE USER hpos identified BY hpos;
--设置用户表空间,表的存储空间,临时表空间
ALTER USER hpos DEFAULT tablespace hpos_data quota unlimited ON hpos_data;
ALTER USER hpos temporary tablespace temp;
--将各种权限赋值给用户
grant CREATE session, CREATE TABLE, CREATE PROCEDURE, CREATE sequence, CREATE TRIGGER, CREATE view, CREATE synonym, ALTER session TO hpos;
--resource包含基本权限 ,对表的增删改查
grant RESOURCE TO hpos;
--通过角色,分配权限
CREATE role manager;
grant CREATE TABLE, CREATE view TO manager;
grant manager TO xiaowu;
grant UPDATE(department_name
,location_id) ON departments TO xiaowu;
grant
SELECT ,INSERT ON departments TO xiaowu WITH grant OPTION;
--with grant option 允许将权限转移给他人
grant
SELECT ON xiaowu.departments TO public
--让所有人都有相关权限
--数据字典视图
--ROLE_SYS_PRIVS 角色对应的系统权限
--ROLE_TAB_PRIVS 角色对应的表权限
--USER_ROLE_PRIVS 用户的角色分配表
--USER_TAB_PRIVS_MADE 用户对象上赋权者与被赋者的历史赋权情况
--USER_TAB_PRIVS_RECD 用户对象上拥有者与被赋者的历史赋权情况
--USER_COL_PRIVS_MADE 用户对象列上赋权者与被赋者的历史赋权情况
--USER_COL_PRIVS_RECD 用户对象列上拥有者与被赋者的历史赋权情况
--USER_SYS_PRIVS 用户的系统权限
--收回权限
revoke {privilege
,privilege .. . | all} ON OBJECT
FROM {user
, USER .. . | role | public}
--创建DB-LINK,通过DB-LINK 访问另一数据库中的表
CREATE public databaselink hq.acme.com
USING 'sales';
DATABASE link created.
SELECT *
FROM emp@hq.acme.com;
--第15单元 集合操作
--集合的合并
SELECT employee_id
,job_id
FROM employees
UNION
SELECT employee_id
,job_id
FROM job_history
;
SELECT employee_id
,job_id
,department_id
FROM employees
UNION ALL
SELECT employee_id
,job_id
,department_id
FROM job_history
ORDER BY employee_id
;
--union 会去掉集合重复部分,作用过程也是全表扫描,会影响性能
--union all 不会去掉集合重复部分
--INTERSECT 交集
SELECT employee_id
,job_id
FROM employees
INTERSECT
SELECT employee_id
,job_id
FROM job_history;
--minus 取差集
SELECT employee_id
,job_id
FROM employees
MINUS
SELECT employee_id
,job_id
FROM job_history;
--第16单元 group by 字句的增强
SELECT department_id
,job_id
,SUM(salary)
FROM employees
WHERE department_id < 60
GROUP BY ROLLUP(department_id
,job_id);
--备注:先是查询同个部门同个工作总的工资,然后查询同个部门总的工资,然后查询所有部门(整个公司)总的工资
SELECT department_id
,job_id
,SUM(salary)
FROM employees
WHERE department_id < 60
GROUP BY CUBE(department_id
,job_id);
--备注:先是查询同个部门同个工作总的工资,然后查询同个部门总的工资,然后查询所有部门同种工作总的工资,
--然后就是全部部门所有工资总的工资
--查询根据属性列分配的源
SELECT department_id deptid
,job_id job
,SUM(salary)
,GROUPING(department_id) grp_dept
,GROUPING(job_id) grp_job
FROM employees
WHERE department_id < 50
GROUP BY ROLLUP(department_id
,job_id);
SELECT department_id
,job_id
,manager_id
,AVG(salary)
FROM employees
GROUP BY GROUPING SETS((department_id, job_id),(job_id, manager_id));
--第17单元
--高于查询同个部门平均工资的员工
SELECT last_name
,salary
,department_id
FROM employees
OUTER WHERE salary > (SELECT AVG(salary)
FROM employees
WHERE department_id = outer.department_id);
--查询为领导的员工
SELECT employee_id
,last_name
,job_id
,department_id
FROM employees
OUTER WHERE EXISTS (SELECT 'X'
FROM employees
WHERE manager_id = outer.employee_id);
SELECT employee_id
,last_name
,job_id
,department_id
FROM employees
WHERE employee_id IN (SELECT manager_id
FROM employees
WHERE manager_id IS NOT NULL);
--查询没有员工的部门
SELECT department_id
,department_name
FROM departments d
WHERE NOT EXISTS (SELECT 'X'
FROM employees
WHERE department_id = d.department_id);
SELECT department_id
,department_name
FROM departments
WHERE department_id NOT IN (SELECT department_id
FROM employees);
--in 属于全表查询操作,效率会下降很多
--工作记录大于两条的员工
SELECT e.employee_id
,last_name
,e.job_id
FROM employees e
WHERE 2 <= (SELECT COUNT(*)
FROM job_history
WHERE employee_id = e.employee_id);
-- 暂存多表
WITH dept_costs AS
(SELECT d.department_name
,SUM(e.salary) AS dept_total
FROM employees e
,departments d
WHERE e.department_id = d.department_id
GROUP BY d.department_name),
avg_cost AS
(SELECT SUM(dept_total) / COUNT(*) AS dept_avg
FROM dept_costs)
SELECT *
FROM dept_costs
WHERE dept_total > (SELECT dept_avg
FROM avg_cost)
ORDER BY department_name;
--第18单元 递归查询
--查询从King开始,从上往下的各级员工
SELECT employee_id || last_name || 'reports to ' || PRIOR last_name "Walk Top Down"
FROM employees
START WITH last_name = 'King' --从king 开始查询
CONNECT BY PRIOR employee_id = manager_id;
-- king 作为递归查询的第一层
-- king的employee_id = whose manager_id 作为条件,得到who
--查询从101开始,从下往上的各级员工
SELECT employee_id
,last_name
,job_id
,manager_id
,PRIOR employee_id
FROM employees
START WITH employee_id = 101
CONNECT BY PRIOR manager_id = employee_id;
--从下往上查询,101作为对底层,
--101的manager_id =empleoyee_id 得到上一层的id,
--prior 作为每层的串联关键
--从上往下查询
SELECT first_name
,lpad(last_name
,length(last_name) + (LEVEL * 2) - 2
,'_') AS org_chart
FROM employees
START WITH last_name = 'King'
CONNECT BY PRIOR employee_id = manager_id
--第19单元
--insert 增强
--选择不同字段,然后根据字段匹配,同时插入多个表
INSERT ALL INTO sal_history VALUES(empid
,hiredate
,sal) INTO mgr_history VALUES(empid
,mgr
,sal) SELECT employee_id empid
,hire_date hiredate
,salary sal
,manager_id mgr
FROM employees
WHERE employee_id > 200
;
CREATE TABLE mytable1(tableid NUMBER
,tablex NUMBER);
CREATE TABLE mytable2(tableid NUMBER
,tablex NUMBER);
CREATE TABLE mytable3(tableid NUMBER
,tablex NUMBER);
--一个来源插入多个目标表(有条件,首次匹配即跳到下一条)
INSERT FIRST WHEN tableid < 200 THEN INTO mytable1
VALUES
(tableid
,tablex) WHEN tablex < 10000 THEN INTO mytable2
VALUES
(tableid
,tablex) ELSE INTO mytable3
VALUES
(tableid
,tablex)
SELECT employee_id tableid
,salary tablex
FROM employees;
drop TABLE mytable1;
drop TABLE mytable2;
drop TABLE mytable3;
SELECT *
FROM mytable1;
SELECT *
FROM mytable2;
SELECT *
FROM mytable3;
SELECT employee_id
,salary
FROM employees;
--对表的操作
--修改表,增加表的列
ALTER TABLE employees add(department_name VARCHAR2(14));
UPDATE employees e
SET department_name =
(SELECT department_name
FROM departments d
WHERE e.department_id = d.department_id);















 1545
1545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









