






在本章主要完成以下几件事情:
-
配置linux主机路由完成跨主机容器通信
-
配置linux ip tunnel完成跨主机容器通信
-
配置linux vxlan完成跨主机容器通信
主机路由
前面我们已经介绍了几种从容器到主机通信的配置方式,接下来我们通过配置主机路由来打通不同主机的容器,首先在两台主机上分别创建一个新的NS然后配置到各自主机的通信,环境如下:
---------------------------------
host1:
host-name:worker2
ip:10.57.4.20
pod-cidr:192.168.10.0/24
---------------------------------
host2:
host-name:worker3
ip:10.57.4.21
pod-cidr:192.168.11.0/24
--------------------------------
首先在host1上执行:
ip netns add ns1
ip link add veth0 type veth peer name veth1
ip link set veth0 netns ns1
ip netns exec ns1 ip addr add 192.168.10.10/24 dev veth0
ip netns exec ns1 ip link set veth0 up
ip netns exec ns1 ip route add 0.0.0.0/0 via 169.2.2.2 dev veth0 onlink
ip link set veth1 up
echo 1 > /proc/sys/net/ipv4/conf/veth1/proxy_arp
echo 1 > /proc/sys/net/ipv4/ip_forward
iptables -P FORWARD ACCEPT
ip route add 192.168.10.10 dev veth1 scope link
然后在host2上执行:
ip netns add ns1
ip link add veth0 type veth peer name veth1
ip link set veth0 netns ns1
ip netns exec ns1 ip addr add 192.168.11.10/24 dev veth0
ip netns exec ns1 ip link set veth0 up
ip netns exec ns1 ip route add 0.0.0.0/0 via 169.2.2.2 dev veth0 onlink
ip link set veth1 up
echo 1 > /proc/sys/net/ipv4/conf/veth1/proxy_arp
echo 1 > /proc/sys/net/ipv4/ip_forward
iptables -P FORWARD ACCEPT
ip route add 192.168.11.10 dev veth1 scope link
如无意外,两台主机和各自的ns1应该是可以相互ping通的了,这时候的状态如下:
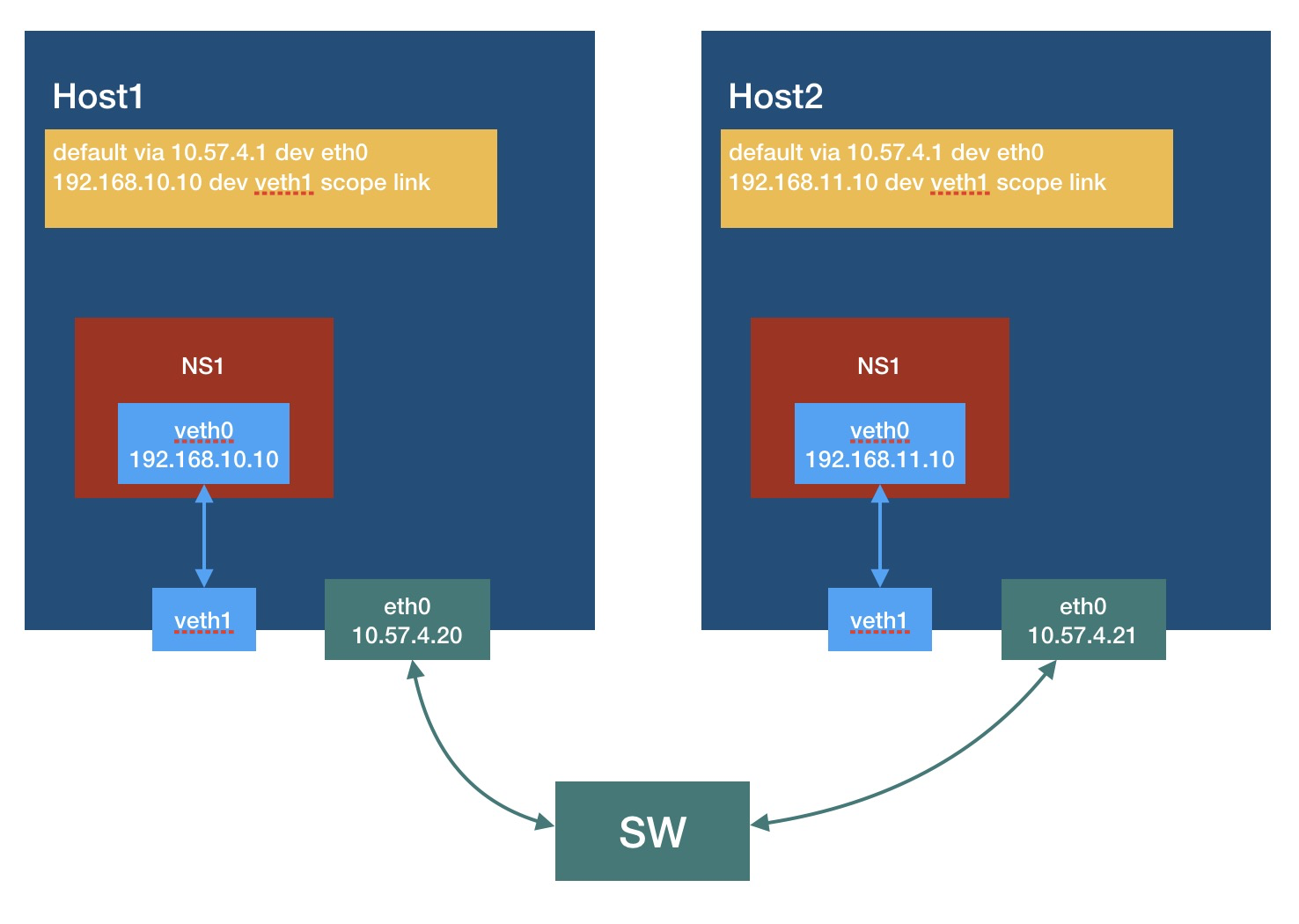
要让两台主机的n1相互通信,只需要在两台主机上再加一条路由即可:
host1:
ip route add 192.168.11.0/24 via 10.57.4.21 dev eth0 onlink
host2:
ip route add 192.168.10.0/24 via 10.57.4.20 dev eth0 onlink
如无意外,这时候 两台主机的NS1已经可以相互ping通了,但这里的意外太多了:
-
首先,如果你的两台主机不在同一个网段,这是不通的,主机所在网络的路由器不知道如何转发192.168.0.0/16网段的流量,数据包应该会被丢弃;
-
其次,如果你是在阿里云或腾讯云的主机上试,也是不通的,因为这两大云平台的主机都不是二层直连的,当数据从host1离开的时候,目的地址为192.168.11.10,这个地址ECS所在的VPC的路由表不知道怎么转发,也会丢弃,所以要去主机所在网络的路由表中添加两条到192.168.10.0/24和192.168.11.0/24两个网段的条目;
-
如果是在华为云的ECS上,则要关闭ECS的网卡的“源/目的检查”;
-
最后,还要记得在ECS所属的安全组里添加对于这两个网段的来源信任。
一个CNI插件通常包含两部分,一个binary和一个daemon,那个daemon的其中一个功能就是一直监听来自api-server的node新增、删除事件,把相关的pod-cidr和node-ip添加到各个节点的主机路由条目上。
IP tunnel
ip tunnel的方式就是在各个主机上建立一个one-to-many的ip tunnel,然后把其它节点的pod-cidr加到主机路由上,只不过dev就不再是eth0了,而是新建的ip tunnel设备,我们接着上面的环境继续操作:
首先删除在两台主机上增加的主机路由
host1:
ip route del 192.168.11.0/24 via 10.57.4.21 dev eth0 onlink
host2:
ip route del 192.168.10.0/24 via 10.57.4.20 dev eth0 onlink
然后在两台主机上分别创建一个one-to-many的ip tunnel(所谓的one-to-many,就是配置ip tunnel时,不指定remote address)
host1:
ip tunnel add mustang.tun0 mode ipip local 10.57.4.20 ttl 64
ip link set mustang.tun0 mtu 1480
ip link set mustang.tun0 up
ip route add 192.168.11.0/24 via 10.57.4.21 dev mustang.tun0 onlink
ip addr add 192.168.10.1/32 dev mustang.tun0
host2:
ip tunnel add mustang.tun0 mode ipip local 10.57.4.21 ttl 64
ip link set mustang.tun0 mtu 1480
ip link set mustang.tun0 up
ip route add 192.168.10.0/24 via 10.57.4.20 dev mustang.tun0 onlink
ip addr add 192.168.11.1/32 dev mustang.tun0
此时的状态:
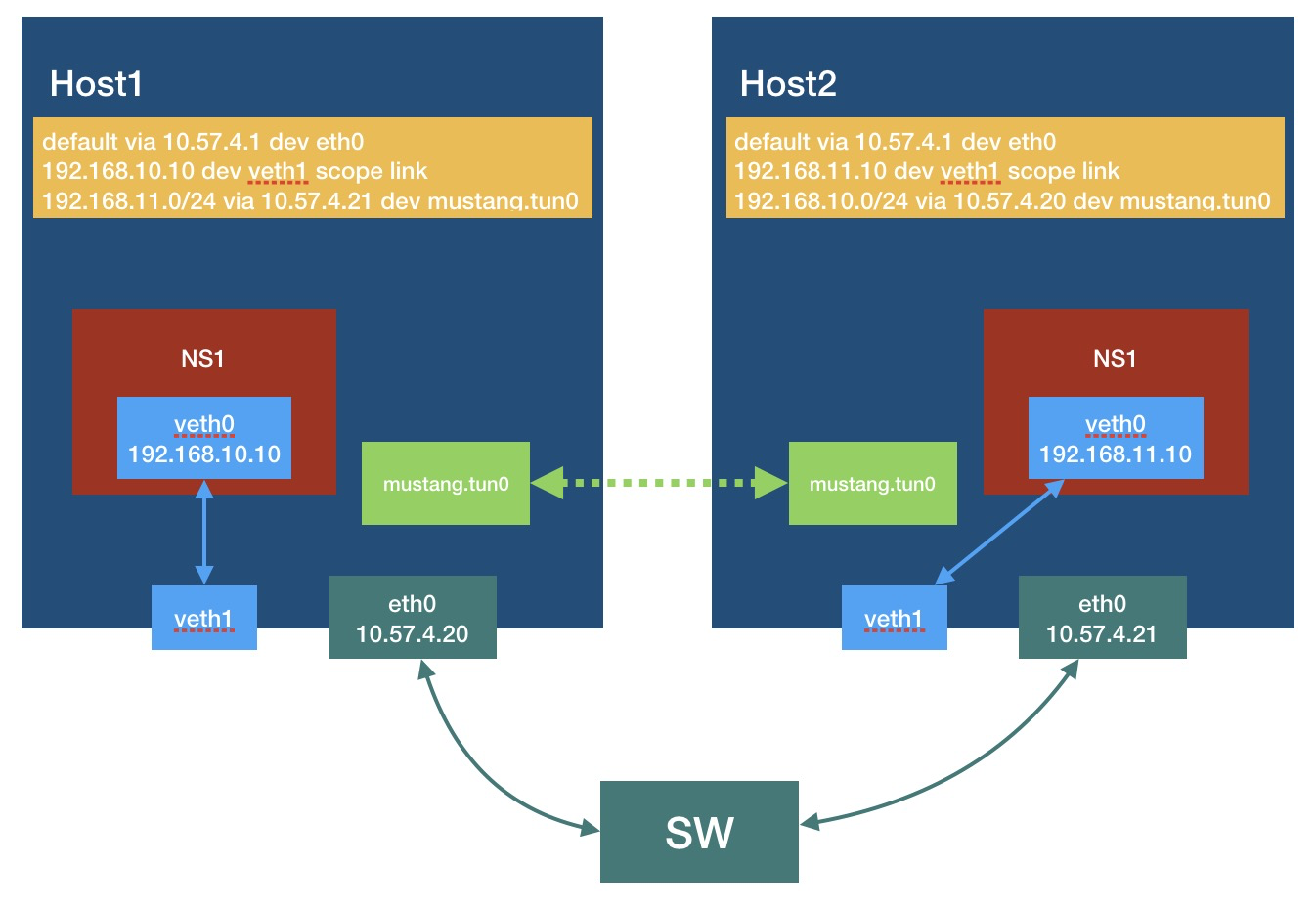
这时候两个ns1应该已经可以相互ping通了,而且这次不管什么云平台不管安全组开没开不管什么源目的检查,应该都能通了,因为ip tunnel的原理是在原来的ip头上再加一层ip头,外层的ip头用的源目的是主机的ip,让主机所在的网络感觉这是正常的主机流量,在host1中执行:
ip netns exec ns1 ping 192.168.11.10 -c 5
在host2的eth0用tcpdump打印一下流量,就能看到有两层ip头:
[root@worker3 ~]# tcpdump -n -i eth0|grep 192.168.11.10
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
18:03:35.048106 IP 10.57.4.20 > 10.57.4.21: IP 192.168.10.10 > 192.168.11.10: ICMP echo request, id 3205, seq 1, length 64 (ipip-proto-4)
18:03:35.049483 IP 10.57.4.21 > 10.57.4.20: IP 192.168.11.10 > 192.168.10.10: ICMP echo reply, id 3205, seq 1, length 64 (ipip-proto-4)
18:03:36.049147 IP 10.57.4.20 > 10.57.4.21: IP 192.168.10.10 > 192.168.11.10: ICMP echo request, id 3205, seq 2, length 64 (ipip-proto-4)
18:03:36.049245 IP 10.57.4.21 > 10.57.4.20: IP 192.168.11.10 > 192.168.10.10: ICMP echo reply, id 3205, seq 2, length 64 (ipip-proto-4)
18:03:37.048860 IP 10.57.4.20 > 10.57.4.21: IP 192.168.10.10 > 192.168.11.10: ICMP echo request, id 3205, seq 3, length 64 (ipip-proto-4)
18:03:37.049178 IP 10.57.4.21 > 10.57.4.20: IP 192.168.11.10 > 192.168.10.10: ICMP echo reply, id 3205, seq 3, length 64 (ipip-proto-4)
18:03:38.048834 IP 10.57.4.20 > 10.57.4.21: IP 192.168.10.10 > 192.168.11.10: ICMP echo request, id 3205, seq 4, length 64 (ipip-proto-4)
18:03:38.048942 IP 10.57.4.21 > 10.57.4.20: IP 192.168.11.10 > 192.168.10.10: ICMP echo reply, id 3205, seq 4, length 64 (ipip-proto-4)
18:03:39.048808 IP 10.57.4.20 > 10.57.4.21: IP 192.168.10.10 > 192.168.11.10: ICMP echo request, id 3205, seq 5, length 64 (ipip-proto-4)
18:03:39.048929 IP 10.57.4.21 > 10.57.4.20: IP 192.168.11.10 > 192.168.10.10: ICMP echo reply, id 3205, seq 5, length 64 (ipip-proto-4)
vxlan
vxlan的方式有点像ip tunnel的方式,也是在两个主机建立一个overlay的网络,只不过vxlan是overlay在二层,我们接着上面的环境继续往下做,先把mustang.tun0删除
在两个节点上执行:
ip link del mustang.tun0
接下来在host1上执行如下命令创建vxlan设备:
ip link add vxlan0 type vxlan id 1 dstport 8472 local 10.57.4.20 dev eth0 nolearning
ip addr add 192.168.10.1/32 dev vxlan0
ip link set vxlan0 up
然后查看vxlan0的设备的mac地址,记下来:
[root@worker2 soft]# ip -d link show vxlan0
151: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/ether 02:40:94:ce:82:cc brd ff:ff:ff:ff:ff:ff promiscuity 0
vxlan id 1 local 10.57.4.20 dev eth0 srcport 0 0 dstport 8472 nolearning ageing 300 noudpcsum noudp6zerocsumtx noudp6zerocsumrx numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
记住如下信息A:(192.168.10.0/24 下一跳192.168.10.1、 下一跳MAC 02:40:94:ce:82:cc 、下一跳的MAC所在主机IP 10.57.4.20)
在host2上执行:
ip link add vxlan0 type vxlan id 1 dstport 8472 local 10.57.4.21 dev eth0 nolearning
ip addr add 192.168.11.1/32 dev vxlan0
ip link set vxlan0 up
查看host2的vxlan0设备的mac,记下来:
[root@worker3 ~]# ip -d link show vxlan0
100: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 02:3f:39:67:7d:f9 brd ff:ff:ff:ff:ff:ff promiscuity 0
vxlan id 1 local 10.57.4.21 dev eth0 srcport 0 0 dstport 8472 nolearning ageing 300 noudpcsum noudp6zerocsumtx noudp6zerocsumrx numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
记住如下信息B:(192.168.11.0/24 下一跳192.168.11.1 、 下一跳MAC 02:3f:39:67:7d:f9 、下一跳的MAC所在主机IP 10.57.4.21)
回到host1上执行如下命令:这里用的是记录的信息B,第一条命令加主机路由,第二条命令加邻居表,第三条加FDB
ip route add 192.168.11.0/24 via 192.168.11.1 dev vxlan0 onlink
ip neigh add 192.168.11.1 lladdr 02:3f:39:67:7d:f9 dev vxlan0 nud permanent
bridge fdb append 02:3f:39:67:7d:f9 dev vxlan0 dst 10.57.4.21 self permanent
host2也一样,只不过用的是记录的信息A:
ip route add 192.168.10.0/24 via 192.168.10.1 dev vxlan0 onlink
ip neigh add 192.168.10.1 dev vxlan0 lladdr 02:40:94:ce:82:cc nud permanent
bridge fdb append 02:40:94:ce:82:cc dev vxlan0 dst 10.57.4.20 self permanent
这时候两台主机的NS1应该可以相互ping通了,在host2的容器里ping一下host1的容器,在host1打开网卡监听,拦截的数据如下:
[root@worker2 ~]# tcpdump -n -i eth0 src 10.57.4.21
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
10:21:01.050849 IP 10.57.4.21.55255 > 10.57.4.20.otv: OTV, flags [I] (0x08), overlay 0, instance 1
IP 192.168.11.10 > 192.168.10.10: ICMP echo request, id 26972, seq 15, length 64
10:21:02.051894 IP 10.57.4.21.55255 > 10.57.4.20.otv: OTV, flags [I] (0x08), overlay 0, instance 1
IP 192.168.11.10 > 192.168.10.10: ICMP echo request, id 26972, seq 16, length 64
......
可以看到也是两层包头,外层包头显示这是otv(overlay transport virtualization)包,对于otv,用一句话解释:
OTV is a “MAC in IP” technique to extend Layer 2 domains over any transport。
对比
用主机路由的方式,因为没有封包拆包的性能损耗,所以速度是最快的,但因为受限的场景较多,反而使用得并不广泛;ip tunnel和vxlan因为要封包拆包,性能会比主机路由的方式差一些,但没有场景限制,基本上只要节点是通的,容器就能通,所以使用比较广泛。
虽然同是overlay模式,vxlan和ip tunnel之间的性能还是有比较大的差异。vxlan在外层是依赖两台主机的UDP通信,而且第一层是到了MAC层才开始再次封包,查FDB和ARP表,相对于ip tunnel只是在IP头的外面再加一层IP头来说性能损耗多了很多,我们通过实测发现vxlan会比ip tunnel性能下降20%左右。
总结
通过前面一系列的文章,我们可以了解到,跨主机容器通信的方式与同主机容器间通信方式是分开的,你可以用纯veth/bridge/macvlan/ipvlan等方式实现同主机容器通信,可以用host-gw/ip tunnel/vxlan/弹性网卡来实现跨主机的容器通信,现在主流的cni基本上就是在这几种选择中组合。
上面的三种跨主机容器通信的方式,其中的主机路由就是flannel的host-gw和calico的BGP模式的原理,而ip tunnel就是calico的IPIP模式的原理(flannel的最新版也应该很快会支持IPIP,看代码已经加上了),vxlan方式就是flannel的vxlan模式的原理。
这个系列的文章出发点是为了剖析k8s常用的CNI组件的原理,到这一步我们已经把主流的几个cni的几种模式的原理都覆盖了,但还差一个,就是flannel最原始的udp模式,这种模式自从flannel出了vxlan后就很少人再用了,因为性能损耗更大,flannel的vxlan用的就是udp协议,跟flannel的udp模式有哪些区别呢?下一章将单独讲flannel的udp模式。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









