







一 数组名指针
c++编译器将数组名解释为指针
#include <iostream>
using namespace std;
int main()
{
int sz[5];
for (int i=0; i<5; i++)
{
sz[i]=i;
}
cout<<"sz:"<<sz<<endl;
cout<<"&sz[0]:"<<&sz[0]<<endl;
cout<<"*zs:"<<(*sz)<<endl;
cout<<"*(sz+3):"<<*(sz+3)<<endl;
return 0;
}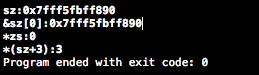
编译器将数组名解释为数组内存区域的首地址,对一维数组来说要实现对某个元素的访问,既可以用数组名+下标的形式,也可以用间接引用*(数组名+偏移)
数组元素的指针形式:
指向数组的指针
数组名可以当指针来使用,但是数组名是常量,其值是不变的,c++不允许修改数组名的值,所以数组名不是很灵活。
数组名指针恒指向数组所占内存区域的第一个字节,对一维数组来说数组名指针指向第0个元素,对多维数组来说,数组名指针指向第[0][0][0].....[0]个元素。
指向数组的指针:
#include <iostream>
using namespace std;
int main()
{
int sz[5];
int *p;
for (int i=0; i<5; i++)
{
sz[i]=i;
}
p=sz; //p=&sz[0]
for (int i=0; i<5; i++)
{
cout<<*(p+i)<<" ";
}
return 0;
}
如果数组是多维数组,有两种指针声明方式:普通指针形式,数组名试用法
1.普通指针形式
#include <iostream>
using namespace std;
int main()
{
int a[2][3][4],*p;
for (int i=0; i<2; i++)
{
for (int j=0; j<3; j++)
{
for (int k=0; k<4; k++)
{
a[i][j][k]=i+j+k;
}
}
}
p=a[0][0];
for (int i=0; i<2; i++)
{
for (int j=0; j<3; j++)
{
for (int k=0; k<4; k++)
{
cout<<*(p+3*4*i+4*j+k)<<" ";
}
}
}
return 0;
}初始化指针p时有以下几种方式,是其指向数组所占内存单元的首字节
int *p=&a[0][0][0];
int *p=a[0][0];
int *p=(int*)a[0];
int *p=(int*)a;在访问 a[i][j][k]时采用了语句 *(p+ 3 * 4 *i+ 4 *j+k),解释一下:要访问a[i][j][k],那么相当于指针要跳过a[i][j]的所有元素再访问第k个元素
每个a[i]对应了3*4个元素(j*k),每个a[i][j]对应了4个元素(k)。其实多维数组在内存中也是线性存储的,要访问后边的元素,需要跳过前面的元素。(个人理解,若有错,请指出,谢谢)。不能用*(*(*(p+i)+j)+k)访问元素哟,原因在于p是普通的int指针,对p的算术运算,指针在内存中的移动单位只取决于int型数据的大小,所以访问不到正确地元素啦,如果想要使用这种形式,需要指出第二维开始的大小,这就是数组名试用法。
2.数组名试用法
#include <iostream>
using namespace std;
int main()
{
int a[2][3][4],(*p)[3][4];
for (int i=0; i<2; i++)
{
for (int j=0; j<3; j++)
{
for (int k=0; k<4; k++)
{
a[i][j][k]=i+j+k;
}
}
}
p=a;
for (int i=0; i<2; i++)
{
for (int j=0; j<3; j++)
{
for (int k=0; k<4; k++)
{
cout<<*(*(*(p+i)+j)+k)<<" ";
}
}
}
return 0;
}*(*(*(p+i)+j)+k)
数组指针(也称行指针) 定义 int (*p)[n];因为[]的优先级比*高,不加括号的话p要先与[]结合就成了指针数组了,首先说明p是一个指针,指向一个整型的一维数组,这个一维数组的长度是n,也可以说是p的步长。也就是说执行p+1时,p要跨过n个整型数据的长度。
如要将二维数组赋给一指针,应这样赋值:
int a[3][4];
int(*p)[4]; //该语句是定义一个数组指针,指向含4个元素的一维数组。
p=a; //将该二维数组的首地址赋给p,也就是a[0]或&a[0][0] .
p++; //该语句执行过后,也就是p=p+1;p跨过行a[0][]指向了行a[1][]
所以数组指针也称指向一维数组的指针,亦称行指针。
#include<stdio.h>
int a[100][100];
int main(void)
{
a[2][1] = 100;
int (*p)[100]=a;
///如何用指针取出a[2][1]?
printf("%d\n", *(*(a + 2) + 1));
printf("%d\n", *(*(p + 2) + 1));
return 0;
}指针数组 定义 int *p[n]; []优先级高,先与p结合成为一个数组,再由int*说明这是一个整型指针数组,它有n个指针类型的数组元素。这里执行p+1是错误的,这样赋值也是错误的:p=a;因为p是个不可知的表示,只存在p[0]、p[1]、p[2]...p[n-1],而且它们分别是指针变量可以用来存放变量地址。但可以这样 *p=a[0]; 这里*p表示指针数组第一个元素的值,a的首地址的值。
如要将二维数组赋给一指针数组:
int *p[3];
int a[3][4];
for(i=0;i<3;i++)
{
p[i]=a[i];
}这里int *p[3] 表示一个一维数组内存放着三个指针变量,分别是p[0]、p[1]、p[2] 所以要分别赋值。
这样两者的区别就豁然开朗了,数组指针只是一个指针变量,似乎是C语言里专门用来指向二维数组的,它占有内存中一个指针的存储空间。指针数组是多个指针变量,以数组形式存在内存当中,占有多个指针的存储空间。 还需要说明的一点就是,同时用来指向二维数组时,其引用和用数组名引用都是一样的。 比如要表示数组中i行j列一个元素: *(p[i]+j)、*(*(p+i)+j)、(*(p+i))[j]、p[i][j]。
#include<stdio.h>
#include <stdlib.h>
int main()
{
int *p[5];
int a[5][6];
for (int i=0; i<5; i++)
{
for (int j=0; j<6; j++)
{
a[i][j]=i+j;
}
}
for (int i=0; i<5; i++)
{
p[i]=a[i]; //p[i]分别指向二维数组中的每一行开头
}
for (int i=0; i<5; i++)
{
for (int j=0; j<6; j++)
{
printf("%3d",*(*(p+i)+j)); //*(p[i]+j)
}
printf("\n");
}
return 0;
}指针数组可以直接为其分配空间,就成了二维数组了。
#include<stdio.h>
#include <stdlib.h>
int main()
{
int *p[5];
for (int i=0; i<5; i++)
{
p[i]=(int*)malloc(sizeof(int)*6); //为p[i]分配空间
}
for (int i=0; i<5; i++)
{
for (int j=0; j<6; j++)
{
p[i][j]=i+j;
}
}
for (int i=0; i<5; i++)
{
for (int j=0; j<6; j++)
{
printf("%3d",*(*(p+i)+j)); //*(p[i]+j)
}
printf("\n");
}
return 0;
}利用二级指针
#include<stdio.h>
#include <stdlib.h>
//动态分配二维数组
int main()
{
int **p; //二级指针
int a,b;
int i,j;
printf("请输入二维数组大小a,b:");
scanf("%d%d",&a,&b);
p=(int **)malloc(sizeof(int*)*a); //这里让二级指针p成为了指针数组了
for(i=0; i<a; i++)
{
p[i]=(int*)malloc(sizeof(int)*b); //再分别数组中得每个指针分配空间,形成二维
for(j=0; j<b; j++)
{
p[i][j]=i+j;
}
}
for(i=0; i<a; i++)
{
for(j=0; j<b; j++)
{
printf("%3d",*(*(p+i)+j));
}
printf("\n");
}
for(i=0; i<a; i++) //释放每个指针所指的空间
{
free(p[i]);
}
free(p); //释放指针数组
return 0;
}优先级:( ) > [] > *















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









