









一Sqoop是什么
Sqoop是一种用于在Hadoop和关系数据库(RDBMS,如MySQL或Oracle)之间传输数据的工具,使用Sqoop可以批量将数据从关系数据库导入到Hadoop分布式文件系统(HDFS)及其相关系统(如HBase和Hive)中,也可以把Hadoop文件系统及其相关系统中的数据导出到关系数据库中,如下图:
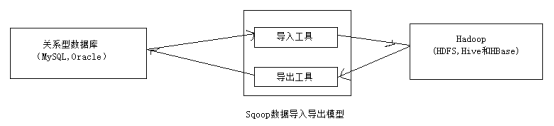
Sqoop基本架构
Sqoop是使用Java语言编写的,Sqoop的架构非常简单,整合了HDFS,HBase和Hive。底层使用MapReduce进行数据传递,从而提供并进行操作和容错功能,如下图:

Sqoop接收到客户端的请求命令后,通过命令翻译器(Task Translater)将命令转换为对应的MapReduce任务,然后通过MapReduce任务将数据在RDBMS和Hadoop系统之间进行导入与导出。
Sqoop导入操作的输入是一个RDBMS数据库表,输出是包含表数据的一系列HDFS文件。导入操作是并行的,可以同时启动多个map任务,每个map任务分别逐行读取表中的一部分数据,并且将这部分数据输出到一个HDFS文件中(即一个map任务对应一个HDFS文件)。
Sqoop导出操作是将数据从HDFS或者Hive导出到关系型数据库中。导出过程并行地读取HDFS上的文件,将每一行内容转化成一条记录添加到关系型数据库表中。除了导入和导出操作,Sqoop还可以查询数据库结构和表信息等。
二Sqoop开发流程
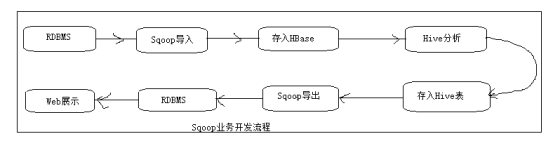
在实际开发中,若数据存储于关系型数据库中,当数据量达到一定规模后需要对其进行分析或统计,此时关系型数据库可能称为瓶颈,这时可以将数据从关系型数据库中导入到HBase中,而后通过数据仓库Hive对HBase中的数据进行统计与分析,并将分析结果存入到Hive表中。最后通过Sqoop将分析结果导出到关系型数据库中作为业务的辅助数据或用于Web页面的展示。
Sqoop的业务开发流程如图所示:
使用Sqoop
要使用Sqoop,需要指定要使用的工具和控制工具的参数。
可以通过进入Sqoop安装目录运行bin/sqoop命令来运行Sqoop。
$ sqoop tool-name [tool-arguments]
Sqoop内置了很多工具,可以通过执行以下命令,显示所有可用工具的列表:
$ sqoop help
常用工具及解析如下:
codegen 生成与数据库记录交互的代码
create-hive-table 导入表的结构到Hive中
eval 执行SQL语句并返回结果
export 导出HDFS目录中的文件数据到数据库表中
help 列出所有可用的工具
import 导入数据库表数据到HDFS中
import-all-tables 导入数据库所有表数到HDFS中
list-databases 列出所有可用数据库
list-tables 列出数据库中所有可用表
version 显示版本信息
也可以执行sqoop help (tool-name)来显示特定工具的帮助信息,例如sqoop help import。还可以将--help参数添加到任何命令,例如sqoop import --help
Sqoop的导入和导出操作主要使用import工具和export工具。这两个工具提供了很多参数帮助我们完成数据的迁移和同步。两个工具中都包含的一些通用参数,如下表所示
| 参数 | 含义 |
| --connect<jdbc-url> | 指定JDBC连接字符串 |
| --connection-manager<class-name> | 指定要使用的连接管理器类 |
| --driver<class-name> | 指定要使用的JDBC驱动类 |
| --hadoop-mapred-home<dir> | 指定$HADOOP_MAPRED_HOME路径(MapReduce主目录) |
| --password-file | 设置用于存放认证的密码信息文件的路径 |
| -P (大写的p) | 从控制台读取设置输入的密码 |
| --password<password> | 设置认证密码 |
| --username<username> | 设置认证用户名 |
| --verbose | 打印详细的运行信息 |
| --connection-param-file<filename> | 指定存储数据库连接参数的属性文件(可选) |
案例分析一:将mysql表数据导入到HDFS中
创建数据库create databases hdfs_hive; 该数据用于实现mysql表数据导入到hdfs分布式文件系统中。
在MySQL中创建数据库hdfs_hive,并在该表中创建表user_info
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for user_info
-- ----------------------------
DROP TABLE IF EXISTS `user_info`;
CREATE TABLE `user_info` (
`userId` int(20) NOT NULL AUTO_INCREMENT,
`userName` varchar(100) DEFAULT NULL,
`password` varchar(50) DEFAULT NULL,
`trueName` varchar(50) DEFAULT NULL,
`addedTime` date DEFAULT NULL,
PRIMARY KEY (`userId`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of user_info
-- ----------------------------
INSERT INTO `user_info` VALUES ('1', '杨洪', '1234565yanghong', 'yanghong', '2020-03-31');
INSERT INTO `user_info` VALUES ('2', '张三', '312321321zhangsan', 'zhangsan', '2020-03-31');
INSERT INTO `user_info` VALUES ('3', '李四', '423432lisi', 'lisi', '2020-03-10');
INSERT INTO `user_info` VALUES ('4', '王五', '234324wangwu', 'wangwu', '2020-03-06');
下面将使用sqoop将表user_info中的数据导入到hdfs中,步骤如下。
1启动Hadoop
在导入数据之前,需要先启动Hadoop集群。执行如下命令,启动Hadoop:
$ start-all.sh
2执行导入命令
执行如下命令,使用Sqoop连接mysql并将表数据到导入到HDFS中
sqoop import \
--connect 'jdbc:mysql://ip:3306/hdfs_hive?characterEncoding=UTF-8' \
--username root \
--password 123456 \
--table user_info \
--columns userId,userName,password,trueName,addedTime \
--target-dir /sqoop/mysql
需要注意的是,”\”后面紧跟回车,表示当前行下一行的续行.
上述代码中各参数含义如下:
--connect: 数据库连接URL
--username: 数据库连接用户名
--password: 数据库密码
--table: 数据库表名
--columns: 数据库列名
--target-dir:数据在HDFS中存放目录。如果HDFS中没有该目录则会自动生成.
20/03/31 21:11:29 INFO mapreduce.Job: map 0% reduce 0%
20/03/31 21:11:38 INFO mapreduce.Job: map 25% reduce 0%
20/03/31 21:11:39 INFO mapreduce.Job: map 50% reduce 0%
20/03/31 21:11:50 INFO mapreduce.Job: map 75% reduce 0%
20/03/31 21:11:53 INFO mapreduce.Job: map 100% reduce 0%
20/03/31 21:11:53 INFO mapreduce.Job: Job job_1585649819788_0001 completed successfully
3查看导入结果
执行下面的命令,查看HDFS中的/sqoop/mysql目录下生成的文件:
$ hadoop fs -ls /sqoop/mysql
-rw-r--r-- 3 hadoop supergroup 0 2020-03-31 21:11 /sqoop/mysql/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 45 2020-03-31 21:11 /sqoop/mysql/part-m-00000
-rw-r--r-- 3 hadoop supergroup 47 2020-03-31 21:11 /sqoop/mysql/part-m-00001
-rw-r--r-- 3 hadoop supergroup 36 2020-03-31 21:11 /sqoop/mysql/part-m-00002
-rw-r--r-- 3 hadoop supergroup 40 2020-03-31 21:11 /sqoop/mysql/part-m-00003
可以看出数据库中的四条数据存储为四个文件,一个文件对应一条数据
执行如下命令,查看/sqoop/mysql/目录下的所有文件的内容:
$ hadoop fs -cat /sqoop/mysql/*
1,杨洪,1234565yanghong,yanghong,2020-03-31
2,张三,312321321zhangsan,zhangsan,2020-03-31
3,李四,423432lisi,lisi,2020-03-10
4,王五,234324wangwu,wangwu,2020-03-06
案例分析二:将HDFS中的数据导出到MySQL中
1在hdfs_hive数据库中创建一个临时表user_info_tmp,字段及类型与表user_info相同,如下:
CREATE TABLE `user_info_tmp` (
`userId` int(20) NOT NULL AUTO_INCREMENT,
`userName` varchar(100) DEFAULT NULL,
`password` varchar(50) DEFAULT NULL,
`trueName` varchar(50) DEFAULT NULL,
`addedTime` date DEFAULT NULL,
PRIMARY KEY (`userId`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
2执行导出命令
执行以下命令,将HDFS文件系统/sqoop/mysql/下的文件中的内容导出到表user_info_tmp中:
sqoop export \
--connect 'jdbc:mysql://ip:3306/hdfs_hive?characterEncoding=UTF-8' \
--username root \
--password 123456 \
--table user_info_tmp \
--export-dir /sqoop/mysql/*
也可以一条一条数据导入
上述代码中各个参数的含义如下:
--table: 目标数据所在的表的名称
--export-dir: 源数据所在的位置
执行成功后输出的部分日志如下:
20/03/31 21:41:44 INFO mapreduce.Job: map 0% reduce 0%
20/03/31 21:41:51 INFO mapreduce.Job: map 100% reduce 0%
20/03/31 21:41:51 INFO mapreduce.Job: Job job_1585649819788_0002 completed successfully
案例分析三:将MySQL表数据导入到HBase中,步骤如下
本例使用sqoop将MySQL中的表user_info的数据导入到HBase中,操作步骤如下。
1启动HBase集群
执行以下命令,启动HBase集群:
start-hbase.sh
新建HBase表,列族为baseinfo:
create 'user_info','baseinfo'
2修改Sqoop配置文件
修改sqoop-env.sh文件,指定HBase的安装目录:
export HBASE_HOME=/home/hadoop/hbase/hbase-1.4.11
3执行以下命令,将MySQL中的数据导入到HBase中:
bin/sqoop import \
--connect 'jdbc:mysql://ip:3306/hdfs_hive?characterEncoding=UTF-8' \
--username root --password 123456 \
--query "select * from user_info where 1=1 and \$CONDITIONS" \
--hbase-table user_info \
--column-family baseinfo \
--hbase-row-key userId \
--split-by addedTime \
--m 2
上述代码中各项参数含义如下:
--query: 指定导入数据的查询条件.
--hbase-table: 指定要导入的HBase中的表名
--column-family: 指定导入的HBase表的列族
--hbase-row-key: 指定MYSQL中的某一列作为HBase表中的rowkey
--split-by: 指定数据库中的某一列作为分区拆分列。默认是主键列(如果存在)。如果主键的实践值不在其范围内均匀分布,那么这可能导致任务分配不平衡。此时应该显式地选择一个具有--split-by参数列
--m: 指定导入过程使用的map任务的数量(并行进程的数量)。若不指定该参数,默认使用4个map任务。一些数据库可以通过将该值增加到8或者16来提高性能,但注意不要增加超过MapReduce集群中可用的并行度。该参数与-m和--num-mappers具有同样的效果。
成功日志:
20/04/01 17:34:36 INFO mapreduce.Job: map 0% reduce 0%
20/04/01 17:34:45 INFO mapreduce.Job: map 50% reduce 0%
20/04/01 17:34:46 INFO mapreduce.Job: map 100% reduce 0%
20/04/01 17:34:46 INFO mapreduce.Job: Job job_1585649819788_0012 completed successfully
查看导入的结果
进入HBase Shell,执行scan ‘user_info’命令,扫描user_info表中的数据:
hbase(main):012:0> scan 'user_info'
ROW COLUMN+CELL
1 column=baseinfo:addedTime, timestamp=1585733684452, value=2020-03-31
1 column=baseinfo:password, timestamp=1585733684452, value=1234565yanghong
1 column=baseinfo:trueName, timestamp=1585733684452, value=yanghong
1 column=baseinfo:userName, timestamp=1585733684452, value=\xE6\x9D\xA8\xE6\xB4\xAA
2 column=baseinfo:addedTime, timestamp=1585733684452, value=2020-03-31
2 column=baseinfo:password, timestamp=1585733684452, value=312321321zhangsan
2 column=baseinfo:trueName, timestamp=1585733684452, value=zhangsan
2 column=baseinfo:userName, timestamp=1585733684452, value=\xE5\xBC\xA0\xE4\xB8\x89
3 column=baseinfo:addedTime, timestamp=1585733684216, value=2020-03-10
3 column=baseinfo:password, timestamp=1585733684216, value=423432lisi
3 column=baseinfo:trueName, timestamp=1585733684216, value=lisi
3 column=baseinfo:userName, timestamp=1585733684216, value=\xE6\x9D\x8E\xE5\x9B\x9B
4 column=baseinfo:addedTime, timestamp=1585733684216, value=2020-03-06
4 column=baseinfo:password, timestamp=1585733684216, value=234324wangwu
4 column=baseinfo:trueName, timestamp=1585733684216, value=wangwu
4 column=baseinfo:userName, timestamp=1585733684216, value=\xE7\x8E\x8B\xE4\xBA\x94
从以上的结果可以看到,四条数据已经成功导入。
如果修改user_info中的数据,重新导入,则会更新替换HBase中相同rowkey对应行的数据。
目前暂不支持将HBase中的数据导出到MySQL,但可以先将HBase中的数据导出到HDFS或者Hive中,再将数据导出到MySQL。















 406
406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









