







1.案例背景说明
1.该项目为互联网电商项目,随着互联网金融业务的发展,订单量逐渐的增大;
2.当前订单总量为 20000万
3.当前当前订单表为10张(ebiz_third_order),分表分别为
ebiz_third_order_0
ebiz_third_order_1
ebiz_third_order_2
ebiz_third_order_3
ebiz_third_order_4
ebiz_third_order_5
ebiz_third_order_6
ebiz_third_order_7
ebiz_third_order_8
ebiz_third_order_9
4.10张表中,每张表大概数量为200万
5.当前数据库连接
6.当前每日订单增量15万2.案例目标
1.将10张表扩张为20张表ebiz_third_order_{00~19},表明如下:
ebiz_third_order_00,ebiz_third_order_01,ebiz_third_order_02,
ebiz_third_order_03,ebiz_third_order_04,ebiz_third_order_05,
ebiz_third_order_06,ebiz_third_order_07,ebiz_third_order_08,
ebiz_third_order_09,ebiz_third_order_10,ebiz_third_order_11,
ebiz_third_order_12,ebiz_third_order_13,ebiz_third_order_14,
ebiz_third_order_15,ebiz_third_order_16,ebiz_third_order_17,
ebiz_third_order_18,ebiz_third_order_19
2.需要先将10张表的数据同步到20张表中
3.后续新增数据不再存储在之前的10张表中,新增数据全部存储新增的20张表建表sql
CREATE TABLE `ebiz_third_order_00` (
`ORDER_ID` BIGINT(20) NOT NULL,
`BUSINESS_TYPE` VARCHAR(20) NULL DEFAULT NULL,
`PARTNER` VARCHAR(50) NULL DEFAULT NULL,
`PARTNER_ORDER_NO` VARCHAR(50) NULL DEFAULT NULL,
`PARTNER_REF_NO` VARCHAR(50) NULL DEFAULT NULL,
`PARTNER_USER_ID` VARCHAR(50) NULL DEFAULT NULL,
`PARTNER_USER_NAME` VARCHAR(50) NULL DEFAULT NULL,
`PARTNER_PAY_NO` VARCHAR(50) NULL DEFAULT NULL,
`PARTNER_PAY_DATE` DATETIME NULL DEFAULT NULL,
`SKU_CODE` VARCHAR(20) NULL DEFAULT NULL,
`CUSTOMER_ID` DECIMAL(19,0) NULL DEFAULT NULL,
`TG_PLATFORM` VARCHAR(50) NULL DEFAULT NULL,
`TG_ORDER_NO` VARCHAR(30) NULL DEFAULT NULL,
`BUSINESS_NO` VARCHAR(200) NULL DEFAULT NULL,
`TG_PRODUCT_CODE` VARCHAR(20) NULL DEFAULT NULL,
`AMOUNT` DECIMAL(12,2) NULL DEFAULT NULL,
`BUSINESS_REMARK` VARCHAR(4000) NULL DEFAULT NULL,
`CALLBACK_URL` VARCHAR(1000) NULL DEFAULT NULL,
`STATUS` VARCHAR(20) NULL DEFAULT NULL,
`CREATED_DATE` DATETIME NULL DEFAULT NULL,
`MODIFIED_DATE` DATETIME NULL DEFAULT NULL,
`CREATED_USER` VARCHAR(45) NULL DEFAULT NULL,
`MODIFIED_USER` VARCHAR(45) NULL DEFAULT NULL,
`IS_DELETE` INT(1) NULL DEFAULT NULL,
PRIMARY KEY (`ORDER_ID`),
INDEX `EBIZ_THIRD_ORDER_INDEX_1` (`PARTNER_ORDER_NO`),
INDEX `EBIZ_THIRD_ORDER_INDEX_2` (`PARTNER_REF_NO`),
INDEX `EBIZ_THIRD_ORDER_INDEX_3` (`BUSINESS_TYPE`),
INDEX `EBIZ_THIRD_ORDER_INDEX_4` (`PARTNER`),
INDEX `EBIZ_THIRD_ORDER_INDEX_5` (`TG_ORDER_NO`),
INDEX `EBIZ_THIRD_ORDER_INDEX_6` (`STATUS`),
INDEX `ebiz_third_order_index_7` (`CUSTOMER_ID`)
)
COLLATE='utf8_general_ci'
ENGINE=InnoDB
;其他的ebiz_third_order00到~19以及ebiz_third_order_0~9都是一样的方法,就是表名变化一下就可以了
3.案例备注
1.涉及到分表的参照表内容,在这里不赘述,详见 https://blog.csdn.net/u014636209/article/details/82141779
4.kettle
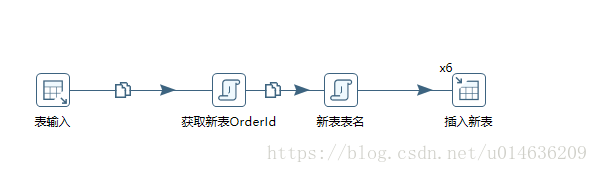
4.1. 表输入
4.1.1.主要是拉去0-9的原始数据
select * from ebiz_third_order_0 o where order_id >=22900000 and order_id <22975800
union all
select * from ebiz_third_order_1 o where order_id >=22900000 and order_id <22975800
union all
select * from ebiz_third_order_2 o where order_id >=22900000 and order_id <22975800
union all
select * from ebiz_third_order_3 o where order_id >=22900000 and order_id <22975800
union all
select * from ebiz_third_order_4 o where order_id >=22900000 and order_id <22975800
union all
select * from ebiz_third_order_5 o where order_id >=22900000 and order_id <22975800
union all
select * from ebiz_third_order_6 o where order_id >=22900000 and order_id <22975800
union all
select * from ebiz_third_order_7 o where order_id >=22900000 and order_id <22975800
union all
select * from ebiz_third_order_8 o where order_id >=22900000 and order_id <22975800
union all
select * from ebiz_third_order_9 o where order_id >=22900000 and order_id <229758004.1.2.表输入控件截图
4.1.3.备注
1.从效率上来讲,建议每次拉去300-400万的数据,具体要看每条记录的内容大小;
2.9个表union all 数据 性能还好,不是特别慢
3.注意用主键Order_id4.2. 获取新表OrderId
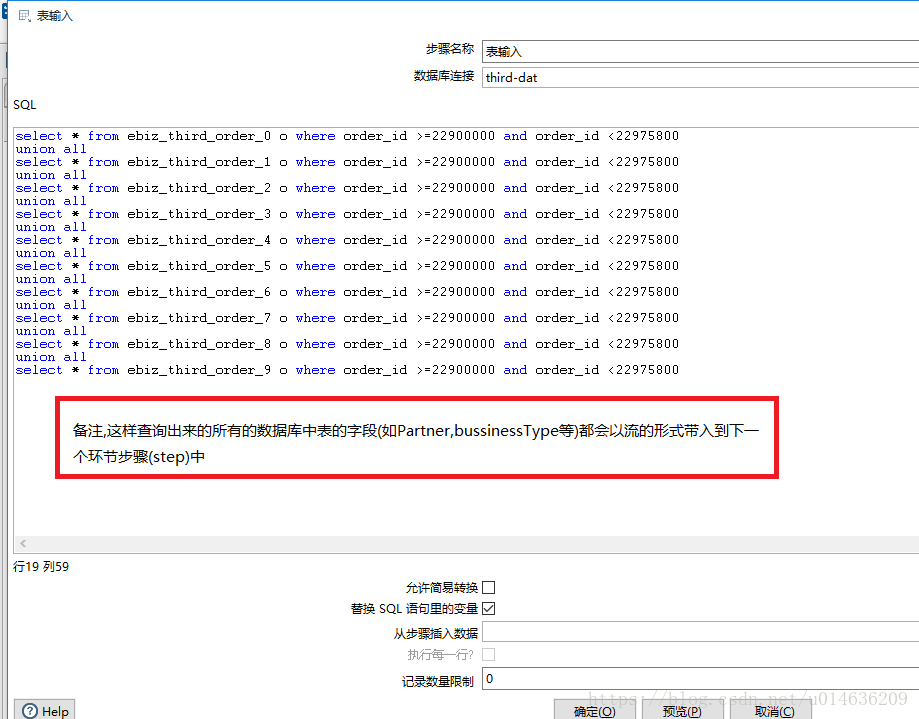
4.2.1 java代码
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws Exception
{
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
r = createOutputRow(r, data.outputRowMeta.size());
String partner = get(Fields.In, "PARTNER").getString(r);
String partnerOrderNo = get(Fields.In, "PARTNER_ORDER_NO").getString(r);
String businessType = get(Fields.In, "BUSINESS_TYPE").getString(r);
String originOrderId = get(Fields.In, "ORDER_ID").getString(r);
String newOrderId=(Long.valueOf(originOrderId)*100 + Math.abs((partner+partnerOrderNo+businessType).hashCode()%100))+"";
get(Fields.Out,"ORDER_ID").setValue(r,Long.valueOf(newOrderId));
putRow(data.outputRowMeta, r);
return true;
}4.2.2 业务功能
1.这段代码主要是决定新表的OrderId逻辑
2.新表的OrderId=原OrderId*100+Math.abs((partner+partnerOrderNo+businessType).hashCode()%100)4.2.3.截图
4.3.新表表名
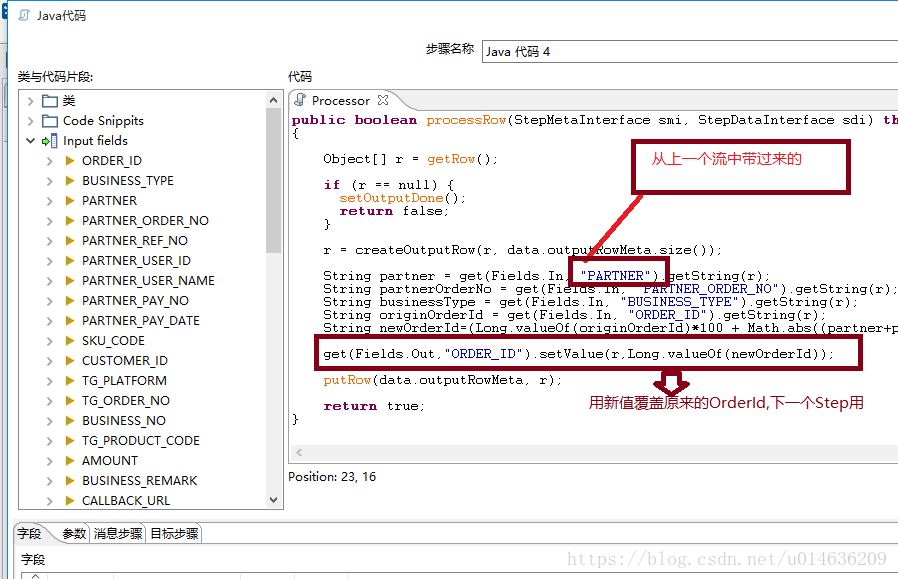
4.3.1. java代码
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws Exception
{
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
r = createOutputRow(r, data.outputRowMeta.size());
String partner = get(Fields.In, "PARTNER").getString(r);
String partnerOrderNo = get(Fields.In, "PARTNER_ORDER_NO").getString(r);
String businessType = get(Fields.In, "BUSINESS_TYPE").getString(r);
String order_n =String.valueOf(Math.abs((partner+partnerOrderNo+businessType).hashCode()%20));
if (order_n.length()<2) {
order_n = "0" + order_n;
}
get(Fields.Out,"table_name").setValue(r,"ebiz_third_order_"+order_n);
putRow(data.outputRowMeta, r);
return true;
}4.3.2.截图说明
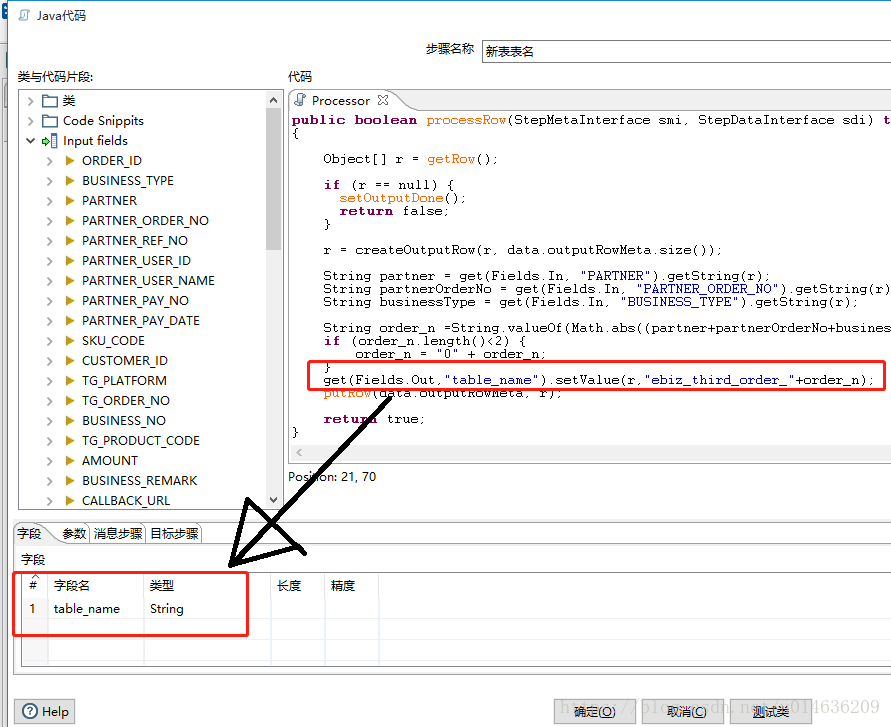
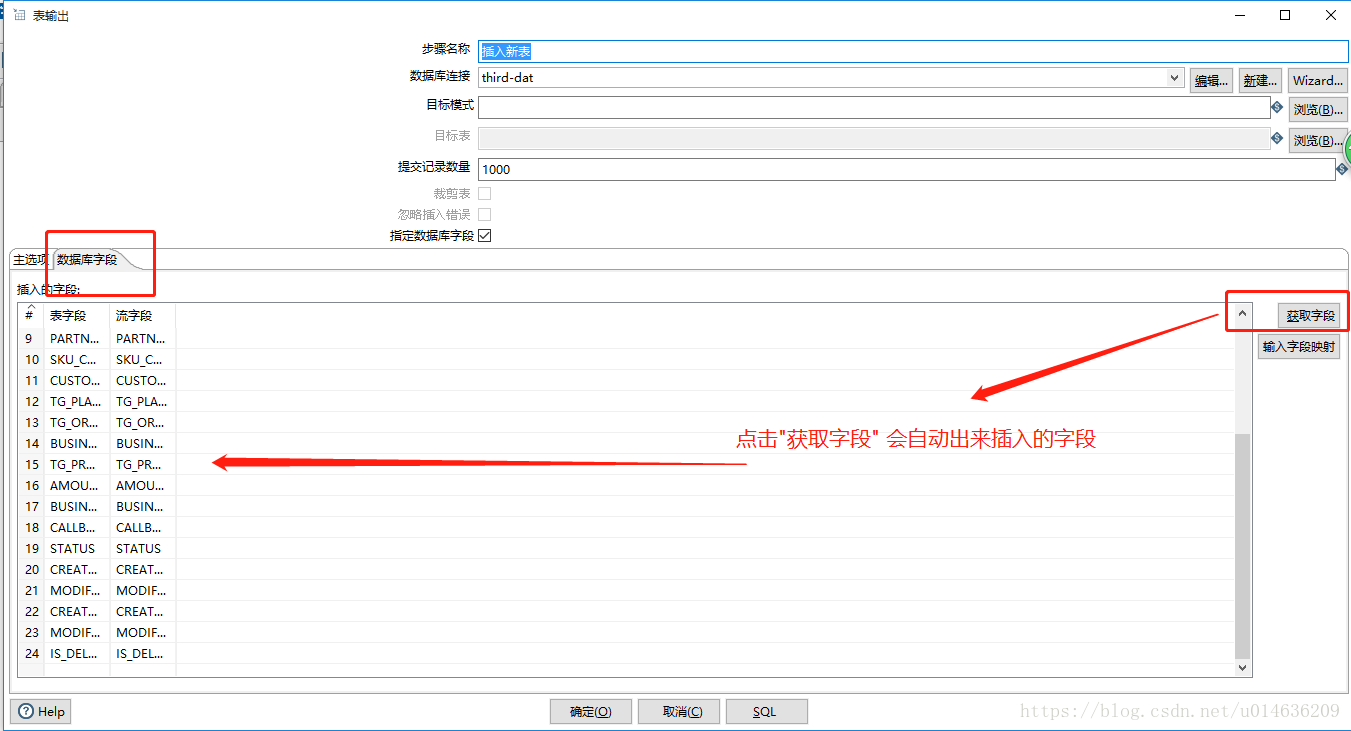
1.注意从流中定义的新的标量,必须在左下方,将字段设置一下,这样,在下一个流程中,才能拿到table_name的值4.3.2.业务功能
1.新表是20张
2.Math.abs((partner+partnerOrderNo+businessType).hashCode()%20)
3.用partner parnterOrderNo bussinessType三个字段加起来进行hash取余数,由于我们的表都是00~19两位数的,所以一位的我们补0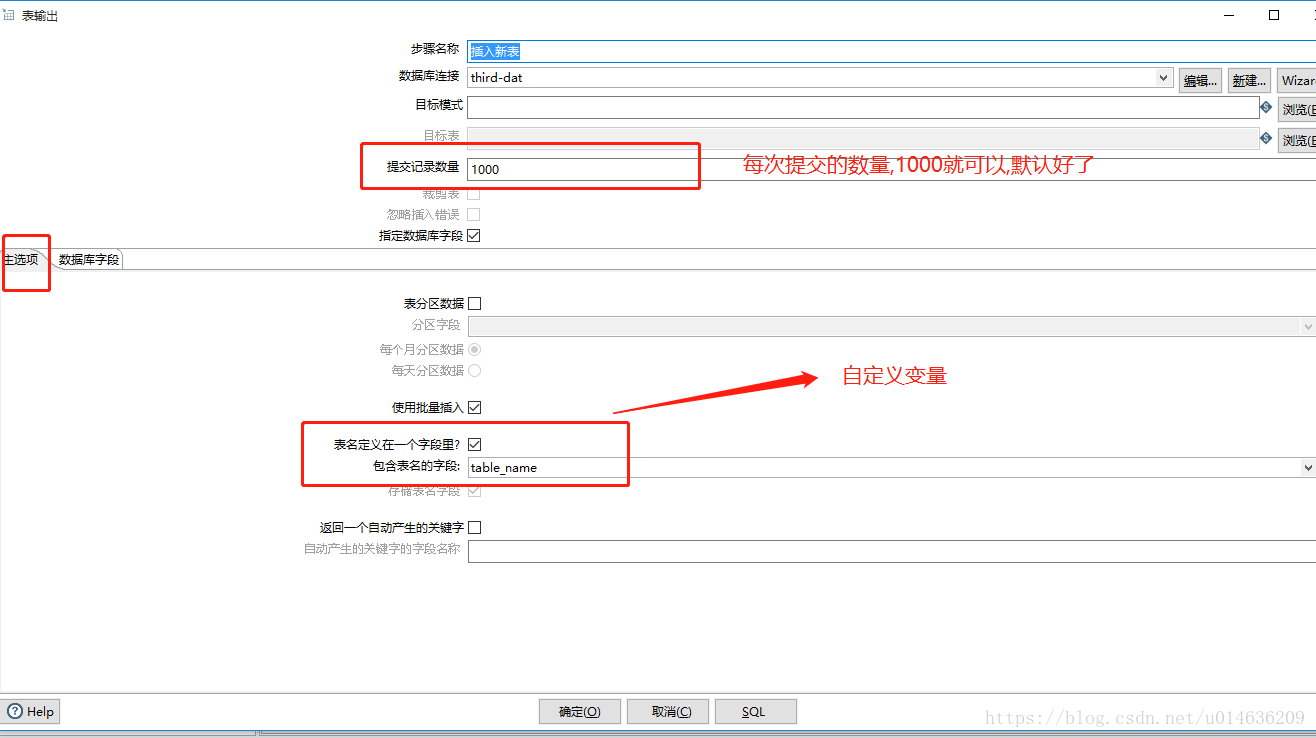















 1664
1664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











