







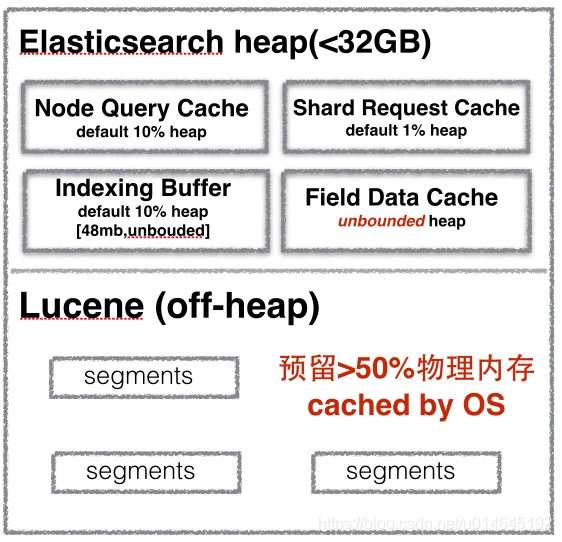
官网:query-cache
官网:shard-request-cache
官网:fileddata
1.NodeQueryCache,没有这个类,对应的是ElasticsearchLRUQueryCache
a.IndicesService类里的loadOrExecuteQueryPhase方法判断是否可以缓存,可以缓存的分支执行loadIntoContext方法。
/**
* Try to load the query results from the cache or execute the query phase directly if the cache cannot be used.
*/
private void loadOrExecuteQueryPhase(final ShardSearchRequest request, final SearchContext context) throws Exception {
final boolean canCache = indicesService.canCache(request, context);
context.getQueryShardContext().freezeContext();
if (canCache) {
indicesService.loadIntoContext(request, context, queryPhase);
} else {
queryPhase.execute(context);
}
}
b.loadIntoContext方法执行cacheShardLevelResult,将结果缓存。
public void loadIntoContext(ShardSearchRequest request, SearchContext context, QueryPhase queryPhase) throws Exception {
assert canCache(request, context);
final DirectoryReader directoryReader = context.searcher().getDirectoryReader();
boolean[] loadedFromCache = new boolean[] { true };
BytesReference bytesReference = cacheShardLevelResult(context.indexShard(), directoryReader, request.cacheKey(), out -> {
queryPhase.execute(context);
try {
context.queryResult().writeToNoId(out);
} catch (IOException e) {
throw new AssertionError("Could not serialize response", e);
}
loadedFromCache[0] = false;
});
......
}
c.IndicesRequestCache的getOrCompute方法,存入本地缓存。
private BytesReference cacheShardLevelResult(IndexShard shard, DirectoryReader reader, BytesReference cacheKey, Consumer<StreamOutput> loader)
throws Exception {
IndexShardCacheEntity cacheEntity = new IndexShardCacheEntity(shard);
Supplier<BytesReference> supplier = () -> {
/* BytesStreamOutput allows to pass the expected size but by default uses
* BigArrays.PAGE_SIZE_IN_BYTES which is 16k. A common cached result ie.
* a date histogram with 3 buckets is ~100byte so 16k might be very wasteful
* since we don't shrink to the actual size once we are done serializing.
* By passing 512 as the expected size we will resize the byte array in the stream
* slowly until we hit the page size and don't waste too much memory for small query
* results.*/
final int expectedSizeInBytes = 512;
try (BytesStreamOutput out = new BytesStreamOutput(expectedSizeInBytes)) {
loader.accept(out);
// for now, keep the paged data structure, which might have unused bytes to fill a page, but better to keep
// the memory properly paged instead of having varied sized bytes
return out.bytes();
}
};
return indicesRequestCache.getOrCompute(cacheEntity, supplier, reader, cacheKey);
}
d.computeIfAbsent 这个方法执行存储。
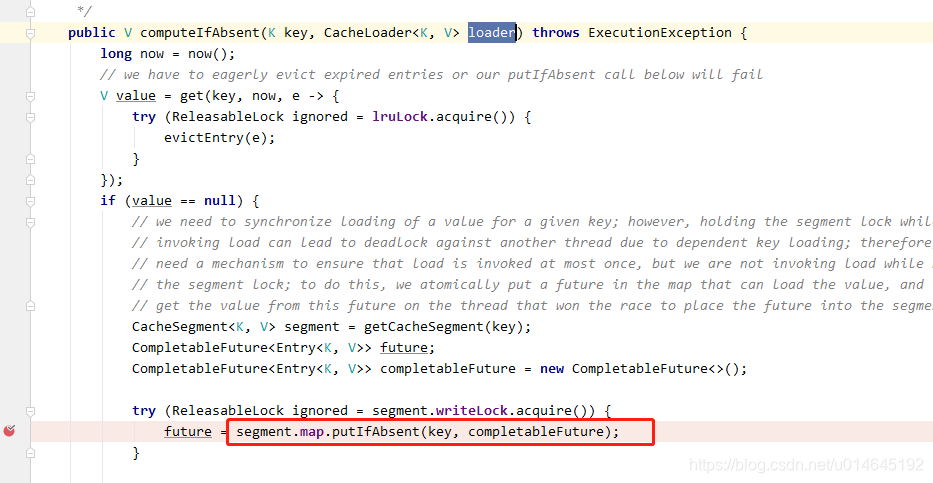
e.segment是cache使用map,避免竞争,使用分段技术,hash方法如下。
private CacheSegment<K, V> getCacheSegment(K key) {
return segments[key.hashCode() & 0xff];
}
2.ShardRequestCache
a.官方说默认指挥存储空结果,除开聚合和建议。https://www.elastic.co/guide/en/elasticsearch/reference/5.6/shard-request-cache.html
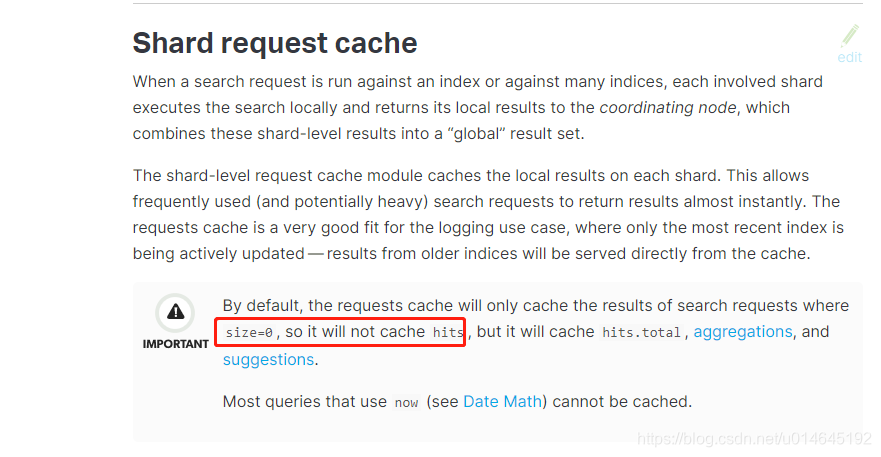
b.从源码看在返回结果存在的话,缓存NodeQueryCache,没有结果的话缓存shardReuestCache.

3.FieldDataCache:
a.Fielddata使用可以通过下面的方式来监控:
对于单个索引使用 {ref}indices-stats.html[indices-stats API]:
GET /_stats/fielddata?fields=*
对于单个节点使用 {ref}cluster-nodes-stats.html[nodes-stats API]:
GET /_nodes/stats/indices/fielddata?fields=*
或者甚至单个节点单个索引
GET /_nodes/stats/indices/fielddata?level=indices&fields=*
https://www.elastic.co/guide/cn/elasticsearch/guide/current/heap-sizing.html














 410
410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









