







需要的jar包 \share\hadoop\common下的jar和其子目录下lib中的jar
\share\hadoop\hdfs下的jar和其子目录下lib中的jar
\share\hadoop\mapreduce下的jar和其子目录下lib中的jar
\share\hadoop\yarn下的jar和其子目录下lib中的jar
WordCountMapper.java
package com.test.hadoop.mr.wordcount;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
// 获取到一行文件的内容
String line = value.toString();
// 切分这一行的内容为一个单词数据
String[] words = StringUtils.split(line, " ");
// 遍历输出 <word,1>
for (String word : words) {
context.write(new Text(word), new LongWritable(1));
}
}
}package com.test.hadoop.mr.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
// key:hello ,values:{1,1,1,1,....}
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
// 定义一个累加计数器
long count = 0;
for (LongWritable value : values) {
count += value.get();
}
// 输出<单词:count>键值对
context.write(key, new LongWritable(count));
}
}package com.test.hadoop.mr.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 用来描述一个作业job(使用哪个mapper类,哪个reducer类,输入文件在哪,输出结果放哪。。。。) 然后提交这个job给hadoop集群
*
* @author Administrator com.test.hadoop.mr.wordcount.WordCountRunner
*/
public class WordCountRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job wcjob = Job.getInstance(conf);
// 设置wcjob中的资源所在的jar包
wcjob.setJarByClass(WordCountRunner.class);
// wcjob 要使用哪个mapper类
wcjob.setMapperClass(WordCountMapper.class);
// wcjob要使用哪个reducer类
wcjob.setReducerClass(WordCountReducer.class);
// wcjob的mapper类输出的kv数据类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(LongWritable.class);
// wcjob的reducer类输出的kv数据类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(LongWritable.class);
// 指定要处理的原始数据存放的路径
// FileInputFormat.setInputPaths(wcjob, "D:/wc/words.txt");
FileInputFormat.setInputPaths(wcjob, "hdfs://192.168.169.128:9000/wc/words.txt");
// 指定处理之后的结果输出到哪个路径
FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://192.168.169.128:9000/wc/output"));
boolean res = wcjob.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}这种方式会将这个job提交到yarn集群上去运行
2、在Linux的eclipse中直接启动Runner类的main方法,这种方式可以使job运行在本地,也可以运行在yarn集群
----究竟运行在本地还是在集群,取决于一个配置参数
mapreduce.framework.name == yarn (local)
----如果确实需要在eclipse中提交到yarn执行,必须做好以下两个设置
a/将mr工程打成jar包(wc.jar),放在工程目录下, 把/opt/soft/hadoop-2.7.3/etc/hadoop/目录中的core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml拷贝到src下
b/在工程的main方法中,加入一个配置参数 conf.set("mapreduce.job.jar","hadoop-mapreduce.jar");
3、在windows的eclipse中运行本地模式,步骤为:
----a、在windows中找一个地方放一份hadoop的安装包,并且将其bin目录配到环境变量中
----b、根据windows平台的版本(32?64?win7?win8?),替换掉hadoop安装包中的本地库(bin,lib)
----c、mr程序的工程中不要有参数mapreduce.framework.name的设置
package com.test.hadoop.mr.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 用来描述一个作业job(使用哪个mapper类,哪个reducer类,输入文件在哪,输出结果放哪。。。。) 然后提交这个job给hadoop集群
*
* @author Administrator com.test.hadoop.mr.wordcount.WordCountRunner
*/
public class WordCountRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//System.setProperty("hadoop.home.dir", "D:/BaiduYunDownload/hadoop-2.7.3");
Configuration conf = new Configuration();
Job wcjob = Job.getInstance(conf);
// 设置wcjob中的资源所在的jar包
wcjob.setJarByClass(WordCountRunner.class);
// wcjob 要使用哪个mapper类
wcjob.setMapperClass(WordCountMapper.class);
// wcjob要使用哪个reducer类
wcjob.setReducerClass(WordCountReducer.class);
// wcjob的mapper类输出的kv数据类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(LongWritable.class);
// wcjob的reducer类输出的kv数据类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(LongWritable.class);
// 指定要处理的原始数据存放的路径
// FileInputFormat.setInputPaths(wcjob, "D:/wc/words.txt");
FileInputFormat.setInputPaths(wcjob, "hdfs://192.168.169.128:9000/wc/words.txt");
// 指定处理之后的结果输出到哪个路径
// FileOutputFormat.setOutputPath(wcjob, new Path("D:/wc/output"));
FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://192.168.169.128:9000/wc/output"));
boolean res = wcjob.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}出现的错误:
1.“Could not locate executable null\bin\winutils.exe in the Hadoop binaries”
“Could not locate executable null\bin\winutils.exe in the Hadoop binaries”
1.1 缺少winutils.exe
Could not locate executable null \bin\winutils.exe in the hadoop binaries
1.2 缺少hadoop.dll
Unable to load native-hadoop library for your platform… using builtin-Java classes where applicable
解决办法
下载资源
http://download.csdn.NET/detail/lizhiguo18/8764975。首先将hadoop.dll和winutils.exe放到hadoop的bin目录下,
还是不可以,重启电脑或者在WordCountRunner加代码System.setProperty("hadoop.home.dir", "D:/BaiduYunDownload/hadoop-2.7.3")(本地的hadoop所存的目录。);
2.org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
分析:
C:\Windows\System32下缺少hadoop.dll,把这个文件拷贝到C:\Windows\System32下面即可。
解决:
hadoop-common-2.2.0-bin-master下的bin的hadoop.dll放到C:\Windows\System32下,然后重启电脑,也许还没那么简单,还是出现这样的问题。
3. org.apache.hadoop.security.AccessControlException: Permission denied: user=Administrator, access=WRITE, inode="/wc/output2/_temporary/0":root:supergroup:drwxr-xr-x
解决办法:WordCountRunner中加
用来指明登陆hadoop的用户
System.setProperty("HADOOP_USER_NAME", "hadoop上的用户名");
或者
右键->Run Configurations->Arguments->VM arguments 加入:-DHADOOP_USER_NAME=root
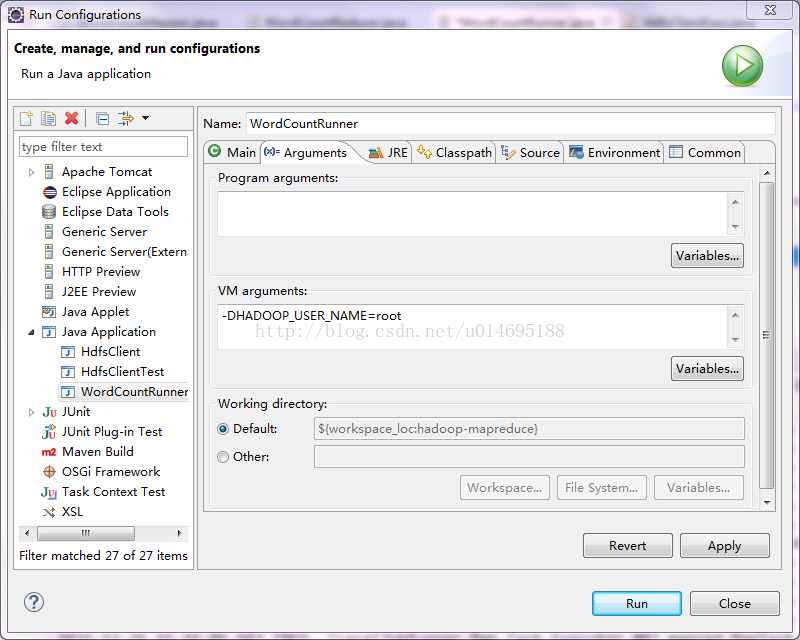
4、在windows的eclipse中运行main方法来提交job到集群执行,比较麻烦
----a、类似于方式3中所描述的对本地库兼容性进行改造
----b、修改YarnRunner这个类
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.mapred;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Vector;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.classification.InterfaceAudience.Private;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileContext;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.UnsupportedFileSystemException;
import org.apache.hadoop.io.DataOutputBuffer;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.ipc.ProtocolSignature;
import org.apache.hadoop.mapreduce.Cluster.JobTrackerStatus;
import org.apache.hadoop.mapreduce.ClusterMetrics;
import org.apache.hadoop.mapreduce.Counters;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.JobID;
import org.apache.hadoop.mapreduce.JobStatus;
import org.apache.hadoop.mapreduce.MRJobConfig;
import org.apache.hadoop.mapreduce.QueueAclsInfo;
import org.apache.hadoop.mapreduce.QueueInfo;
import org.apache.hadoop.mapreduce.TaskAttemptID;
import org.apache.hadoop.mapreduce.TaskCompletionEvent;
import org.apache.hadoop.mapreduce.TaskReport;
import org.apache.hadoop.mapreduce.TaskTrackerInfo;
import org.apache.hadoop.mapreduce.TaskType;
import org.apache.hadoop.mapreduce.TypeConverter;
import org.apache.hadoop.mapreduce.protocol.ClientProtocol;
import org.apache.hadoop.mapreduce.security.token.delegation.DelegationTokenIdentifier;
import org.apache.hadoop.mapreduce.v2.LogParams;
import org.apache.hadoop.mapreduce.v2.api.MRClientProtocol;
import org.apache.hadoop.mapreduce.v2.api.protocolrecords.GetDelegationTokenRequest;
import org.apache.hadoop.mapreduce.v2.jobhistory.JobHistoryUtils;
import org.apache.hadoop.mapreduce.v2.util.MRApps;
import org.apache.hadoop.security.Credentials;
import org.apache.hadoop.security.SecurityUtil;
import org.apache.hadoop.security.UserGroupInformation;
import org.apache.hadoop.security.authorize.AccessControlList;
import org.apache.hadoop.security.token.Token;
import org.apache.hadoop.yarn.api.ApplicationConstants;
import org.apache.hadoop.yarn.api.ApplicationConstants.Environment;
import org.apache.hadoop.yarn.api.records.ApplicationAccessType;
import org.apache.hadoop.yarn.api.records.ApplicationId;
import org.apache.hadoop.yarn.api.records.ApplicationReport;
import org.apache.hadoop.yarn.api.records.ApplicationSubmissionContext;
import org.apache.hadoop.yarn.api.records.ContainerLaunchContext;
import org.apache.hadoop.yarn.api.records.LocalResource;
import org.apache.hadoop.yarn.api.records.LocalResourceType;
import org.apache.hadoop.yarn.api.records.LocalResourceVisibility;
import org.apache.hadoop.yarn.api.records.Resource;
import org.apache.hadoop.yarn.api.records.URL;
import org.apache.hadoop.yarn.api.records.YarnApplicationState;
import org.apache.hadoop.yarn.conf.YarnConfiguration;
import org.apache.hadoop.yarn.exceptions.YarnException;
import org.apache.hadoop.yarn.factories.RecordFactory;
import org.apache.hadoop.yarn.factory.providers.RecordFactoryProvider;
import org.apache.hadoop.yarn.security.client.RMDelegationTokenSelector;
import org.apache.hadoop.yarn.util.ConverterUtils;
import com.google.common.annotations.VisibleForTesting;
/**
* This class enables the current JobClient (0.22 hadoop) to run on YARN.
*/
@SuppressWarnings("unchecked")
public class YARNRunner implements ClientProtocol {
private static final Log LOG = LogFactory.getLog(YARNRunner.class);
private final RecordFactory recordFactory = RecordFactoryProvider.getRecordFactory(null);
private ResourceMgrDelegate resMgrDelegate;
private ClientCache clientCache;
private Configuration conf;
private final FileContext defaultFileContext;
/**
* Yarn runner incapsulates the client interface of
* yarn
* @param conf the configuration object for the client
*/
public YARNRunner(Configuration conf) {
this(conf, new ResourceMgrDelegate(new YarnConfiguration(conf)));
}
/**
* Similar to {@link #YARNRunner(Configuration)} but allowing injecting
* {@link ResourceMgrDelegate}. Enables mocking and testing.
* @param conf the configuration object for the client
* @param resMgrDelegate the resourcemanager client handle.
*/
public YARNRunner(Configuration conf, ResourceMgrDelegate resMgrDelegate) {
this(conf, resMgrDelegate, new ClientCache(conf, resMgrDelegate));
}
/**
* Similar to {@link YARNRunner#YARNRunner(Configuration, ResourceMgrDelegate)}
* but allowing injecting {@link ClientCache}. Enable mocking and testing.
* @param conf the configuration object
* @param resMgrDelegate the resource manager delegate
* @param clientCache the client cache object.
*/
public YARNRunner(Configuration conf, ResourceMgrDelegate resMgrDelegate,
ClientCache clientCache) {
this.conf = conf;
try {
this.resMgrDelegate = resMgrDelegate;
this.clientCache = clientCache;
this.defaultFileContext = FileContext.getFileContext(this.conf);
} catch (UnsupportedFileSystemException ufe) {
throw new RuntimeException("Error in instantiating YarnClient", ufe);
}
}
@Private
/**
* Used for testing mostly.
* @param resMgrDelegate the resource manager delegate to set to.
*/
public void setResourceMgrDelegate(ResourceMgrDelegate resMgrDelegate) {
this.resMgrDelegate = resMgrDelegate;
}
@Override
public void cancelDelegationToken(Token<DelegationTokenIdentifier> arg0)
throws IOException, InterruptedException {
throw new UnsupportedOperationException("Use Token.renew instead");
}
@Override
public TaskTrackerInfo[] getActiveTrackers() throws IOException,
InterruptedException {
return resMgrDelegate.getActiveTrackers();
}
@Override
public JobStatus[] getAllJobs() throws IOException, InterruptedException {
return resMgrDelegate.getAllJobs();
}
@Override
public TaskTrackerInfo[] getBlacklistedTrackers() throws IOException,
InterruptedException {
return resMgrDelegate.getBlacklistedTrackers();
}
@Override
public ClusterMetrics getClusterMetrics() throws IOException,
InterruptedException {
return resMgrDelegate.getClusterMetrics();
}
@VisibleForTesting
void addHistoryToken(Credentials ts) throws IOException, InterruptedException {
/* check if we have a hsproxy, if not, no need */
MRClientProtocol hsProxy = clientCache.getInitializedHSProxy();
if (UserGroupInformation.isSecurityEnabled() && (hsProxy != null)) {
/*
* note that get delegation token was called. Again this is hack for oozie
* to make sure we add history server delegation tokens to the credentials
*/
RMDelegationTokenSelector tokenSelector = new RMDelegationTokenSelector();
Text service = resMgrDelegate.getRMDelegationTokenService();
if (tokenSelector.selectToken(service, ts.getAllTokens()) != null) {
Text hsService = SecurityUtil.buildTokenService(hsProxy
.getConnectAddress());
if (ts.getToken(hsService) == null) {
ts.addToken(hsService, getDelegationTokenFromHS(hsProxy));
}
}
}
}
@VisibleForTesting
Token<?> getDelegationTokenFromHS(MRClientProtocol hsProxy)
throws IOException, InterruptedException {
GetDelegationTokenRequest request = recordFactory
.newRecordInstance(GetDelegationTokenRequest.class);
request.setRenewer(Master.getMasterPrincipal(conf));
org.apache.hadoop.yarn.api.records.Token mrDelegationToken;
mrDelegationToken = hsProxy.getDelegationToken(request)
.getDelegationToken();
return ConverterUtils.convertFromYarn(mrDelegationToken,
hsProxy.getConnectAddress());
}
@Override
public Token<DelegationTokenIdentifier> getDelegationToken(Text renewer)
throws IOException, InterruptedException {
// The token is only used for serialization. So the type information
// mismatch should be fine.
return resMgrDelegate.getDelegationToken(renewer);
}
@Override
public String getFilesystemName() throws IOException, InterruptedException {
return resMgrDelegate.getFilesystemName();
}
@Override
public JobID getNewJobID() throws IOException, InterruptedException {
return resMgrDelegate.getNewJobID();
}
@Override
public QueueInfo getQueue(String queueName) throws IOException,
InterruptedException {
return resMgrDelegate.getQueue(queueName);
}
@Override
public QueueAclsInfo[] getQueueAclsForCurrentUser() throws IOException,
InterruptedException {
return resMgrDelegate.getQueueAclsForCurrentUser();
}
@Override
public QueueInfo[] getQueues() throws IOException, InterruptedException {
return resMgrDelegate.getQueues();
}
@Override
public QueueInfo[] getRootQueues() throws IOException, InterruptedException {
return resMgrDelegate.getRootQueues();
}
@Override
public QueueInfo[] getChildQueues(String parent) throws IOException,
InterruptedException {
return resMgrDelegate.getChildQueues(parent);
}
@Override
public String getStagingAreaDir() throws IOException, InterruptedException {
return resMgrDelegate.getStagingAreaDir();
}
@Override
public String getSystemDir() throws IOException, InterruptedException {
return resMgrDelegate.getSystemDir();
}
@Override
public long getTaskTrackerExpiryInterval() throws IOException,
InterruptedException {
return resMgrDelegate.getTaskTrackerExpiryInterval();
}
@Override
public JobStatus submitJob(JobID jobId, String jobSubmitDir, Credentials ts)
throws IOException, InterruptedException {
addHistoryToken(ts);
// Construct necessary information to start the MR AM
ApplicationSubmissionContext appContext =
createApplicationSubmissionContext(conf, jobSubmitDir, ts);
// Submit to ResourceManager
try {
ApplicationId applicationId =
resMgrDelegate.submitApplication(appContext);
ApplicationReport appMaster = resMgrDelegate
.getApplicationReport(applicationId);
String diagnostics =
(appMaster == null ?
"application report is null" : appMaster.getDiagnostics());
if (appMaster == null
|| appMaster.getYarnApplicationState() == YarnApplicationState.FAILED
|| appMaster.getYarnApplicationState() == YarnApplicationState.KILLED) {
throw new IOException("Failed to run job : " +
diagnostics);
}
return clientCache.getClient(jobId).getJobStatus(jobId);
} catch (YarnException e) {
throw new IOException(e);
}
}
private LocalResource createApplicationResource(FileContext fs, Path p, LocalResourceType type)
throws IOException {
LocalResource rsrc = recordFactory.newRecordInstance(LocalResource.class);
FileStatus rsrcStat = fs.getFileStatus(p);
rsrc.setResource(ConverterUtils.getYarnUrlFromPath(fs
.getDefaultFileSystem().resolvePath(rsrcStat.getPath())));
rsrc.setSize(rsrcStat.getLen());
rsrc.setTimestamp(rsrcStat.getModificationTime());
rsrc.setType(type);
rsrc.setVisibility(LocalResourceVisibility.APPLICATION);
return rsrc;
}
public ApplicationSubmissionContext createApplicationSubmissionContext(
Configuration jobConf,
String jobSubmitDir, Credentials ts) throws IOException {
ApplicationId applicationId = resMgrDelegate.getApplicationId();
// Setup resource requirements
Resource capability = recordFactory.newRecordInstance(Resource.class);
capability.setMemory(
conf.getInt(
MRJobConfig.MR_AM_VMEM_MB, MRJobConfig.DEFAULT_MR_AM_VMEM_MB
)
);
capability.setVirtualCores(
conf.getInt(
MRJobConfig.MR_AM_CPU_VCORES, MRJobConfig.DEFAULT_MR_AM_CPU_VCORES
)
);
LOG.debug("AppMaster capability = " + capability);
// Setup LocalResources
Map<String, LocalResource> localResources =
new HashMap<String, LocalResource>();
Path jobConfPath = new Path(jobSubmitDir, MRJobConfig.JOB_CONF_FILE);
URL yarnUrlForJobSubmitDir = ConverterUtils
.getYarnUrlFromPath(defaultFileContext.getDefaultFileSystem()
.resolvePath(
defaultFileContext.makeQualified(new Path(jobSubmitDir))));
LOG.debug("Creating setup context, jobSubmitDir url is "
+ yarnUrlForJobSubmitDir);
localResources.put(MRJobConfig.JOB_CONF_FILE,
createApplicationResource(defaultFileContext,
jobConfPath, LocalResourceType.FILE));
if (jobConf.get(MRJobConfig.JAR) != null) {
Path jobJarPath = new Path(jobConf.get(MRJobConfig.JAR));
LocalResource rc = createApplicationResource(defaultFileContext,
jobJarPath,
LocalResourceType.PATTERN);
String pattern = conf.getPattern(JobContext.JAR_UNPACK_PATTERN,
JobConf.UNPACK_JAR_PATTERN_DEFAULT).pattern();
rc.setPattern(pattern);
localResources.put(MRJobConfig.JOB_JAR, rc);
} else {
// Job jar may be null. For e.g, for pipes, the job jar is the hadoop
// mapreduce jar itself which is already on the classpath.
LOG.info("Job jar is not present. "
+ "Not adding any jar to the list of resources.");
}
// TODO gross hack
for (String s : new String[] {
MRJobConfig.JOB_SPLIT,
MRJobConfig.JOB_SPLIT_METAINFO }) {
localResources.put(
MRJobConfig.JOB_SUBMIT_DIR + "/" + s,
createApplicationResource(defaultFileContext,
new Path(jobSubmitDir, s), LocalResourceType.FILE));
}
// Setup security tokens
DataOutputBuffer dob = new DataOutputBuffer();
ts.writeTokenStorageToStream(dob);
ByteBuffer securityTokens = ByteBuffer.wrap(dob.getData(), 0, dob.getLength());
// Setup the command to run the AM
List<String> vargs = new ArrayList<String>(8);
//TODO to fix the java_home by dht
// vargs.add(MRApps.crossPlatformifyMREnv(jobConf, Environment.JAVA_HOME) + "/bin/java");
vargs.add("$JAVA_HOME/bin/java");
// TODO: why do we use 'conf' some places and 'jobConf' others?
long logSize = jobConf.getLong(MRJobConfig.MR_AM_LOG_KB,
MRJobConfig.DEFAULT_MR_AM_LOG_KB) << 10;
String logLevel = jobConf.get(
MRJobConfig.MR_AM_LOG_LEVEL, MRJobConfig.DEFAULT_MR_AM_LOG_LEVEL);
int numBackups = jobConf.getInt(MRJobConfig.MR_AM_LOG_BACKUPS,
MRJobConfig.DEFAULT_MR_AM_LOG_BACKUPS);
MRApps.addLog4jSystemProperties(logLevel, logSize, numBackups, vargs);
// Check for Java Lib Path usage in MAP and REDUCE configs
warnForJavaLibPath(conf.get(MRJobConfig.MAP_JAVA_OPTS,""), "map",
MRJobConfig.MAP_JAVA_OPTS, MRJobConfig.MAP_ENV);
warnForJavaLibPath(conf.get(MRJobConfig.MAPRED_MAP_ADMIN_JAVA_OPTS,""), "map",
MRJobConfig.MAPRED_MAP_ADMIN_JAVA_OPTS, MRJobConfig.MAPRED_ADMIN_USER_ENV);
warnForJavaLibPath(conf.get(MRJobConfig.REDUCE_JAVA_OPTS,""), "reduce",
MRJobConfig.REDUCE_JAVA_OPTS, MRJobConfig.REDUCE_ENV);
warnForJavaLibPath(conf.get(MRJobConfig.MAPRED_REDUCE_ADMIN_JAVA_OPTS,""), "reduce",
MRJobConfig.MAPRED_REDUCE_ADMIN_JAVA_OPTS, MRJobConfig.MAPRED_ADMIN_USER_ENV);
// Add AM admin command opts before user command opts
// so that it can be overridden by user
String mrAppMasterAdminOptions = conf.get(MRJobConfig.MR_AM_ADMIN_COMMAND_OPTS,
MRJobConfig.DEFAULT_MR_AM_ADMIN_COMMAND_OPTS);
warnForJavaLibPath(mrAppMasterAdminOptions, "app master",
MRJobConfig.MR_AM_ADMIN_COMMAND_OPTS, MRJobConfig.MR_AM_ADMIN_USER_ENV);
vargs.add(mrAppMasterAdminOptions);
// Add AM user command opts
String mrAppMasterUserOptions = conf.get(MRJobConfig.MR_AM_COMMAND_OPTS,
MRJobConfig.DEFAULT_MR_AM_COMMAND_OPTS);
warnForJavaLibPath(mrAppMasterUserOptions, "app master",
MRJobConfig.MR_AM_COMMAND_OPTS, MRJobConfig.MR_AM_ENV);
vargs.add(mrAppMasterUserOptions);
vargs.add(MRJobConfig.APPLICATION_MASTER_CLASS);
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR +
Path.SEPARATOR + ApplicationConstants.STDOUT);
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR +
Path.SEPARATOR + ApplicationConstants.STDERR);
Vector<String> vargsFinal = new Vector<String>(8);
// Final command
StringBuilder mergedCommand = new StringBuilder();
for (CharSequence str : vargs) {
mergedCommand.append(str).append(" ");
}
vargsFinal.add(mergedCommand.toString());
LOG.debug("Command to launch container for ApplicationMaster is : "
+ mergedCommand);
// Setup the CLASSPATH in environment
// i.e. add { Hadoop jars, job jar, CWD } to classpath.
Map<String, String> environment = new HashMap<String, String>();
MRApps.setClasspath(environment, conf);
// Setup the environment variables for Admin first
MRApps.setEnvFromInputString(environment,
conf.get(MRJobConfig.MR_AM_ADMIN_USER_ENV), conf);
// Setup the environment variables (LD_LIBRARY_PATH, etc)
MRApps.setEnvFromInputString(environment,
conf.get(MRJobConfig.MR_AM_ENV), conf);
// Parse distributed cache
MRApps.setupDistributedCache(jobConf, localResources);
Map<ApplicationAccessType, String> acls
= new HashMap<ApplicationAccessType, String>(2);
acls.put(ApplicationAccessType.VIEW_APP, jobConf.get(
MRJobConfig.JOB_ACL_VIEW_JOB, MRJobConfig.DEFAULT_JOB_ACL_VIEW_JOB));
acls.put(ApplicationAccessType.MODIFY_APP, jobConf.get(
MRJobConfig.JOB_ACL_MODIFY_JOB,
MRJobConfig.DEFAULT_JOB_ACL_MODIFY_JOB));
//TODO to replace the environment by dht
replaceEnvironment(environment);
// Setup ContainerLaunchContext for AM container
ContainerLaunchContext amContainer =
ContainerLaunchContext.newInstance(localResources, environment,
vargsFinal, null, securityTokens, acls);
Collection<String> tagsFromConf =
jobConf.getTrimmedStringCollection(MRJobConfig.JOB_TAGS);
// Set up the ApplicationSubmissionContext
ApplicationSubmissionContext appContext =
recordFactory.newRecordInstance(ApplicationSubmissionContext.class);
appContext.setApplicationId(applicationId); // ApplicationId
appContext.setQueue( // Queue name
jobConf.get(JobContext.QUEUE_NAME,
YarnConfiguration.DEFAULT_QUEUE_NAME));
appContext.setApplicationName( // Job name
jobConf.get(JobContext.JOB_NAME,
YarnConfiguration.DEFAULT_APPLICATION_NAME));
appContext.setCancelTokensWhenComplete(
conf.getBoolean(MRJobConfig.JOB_CANCEL_DELEGATION_TOKEN, true));
appContext.setAMContainerSpec(amContainer); // AM Container
appContext.setMaxAppAttempts(
conf.getInt(MRJobConfig.MR_AM_MAX_ATTEMPTS,
MRJobConfig.DEFAULT_MR_AM_MAX_ATTEMPTS));
appContext.setResource(capability);
appContext.setApplicationType(MRJobConfig.MR_APPLICATION_TYPE);
if (tagsFromConf != null && !tagsFromConf.isEmpty()) {
appContext.setApplicationTags(new HashSet<String>(tagsFromConf));
}
return appContext;
}
@Override
public void setJobPriority(JobID arg0, String arg1) throws IOException,
InterruptedException {
resMgrDelegate.setJobPriority(arg0, arg1);
}
@Override
public long getProtocolVersion(String arg0, long arg1) throws IOException {
return resMgrDelegate.getProtocolVersion(arg0, arg1);
}
@Override
public long renewDelegationToken(Token<DelegationTokenIdentifier> arg0)
throws IOException, InterruptedException {
throw new UnsupportedOperationException("Use Token.renew instead");
}
@Override
public Counters getJobCounters(JobID arg0) throws IOException,
InterruptedException {
return clientCache.getClient(arg0).getJobCounters(arg0);
}
@Override
public String getJobHistoryDir() throws IOException, InterruptedException {
return JobHistoryUtils.getConfiguredHistoryServerDoneDirPrefix(conf);
}
@Override
public JobStatus getJobStatus(JobID jobID) throws IOException,
InterruptedException {
JobStatus status = clientCache.getClient(jobID).getJobStatus(jobID);
return status;
}
@Override
public TaskCompletionEvent[] getTaskCompletionEvents(JobID arg0, int arg1,
int arg2) throws IOException, InterruptedException {
return clientCache.getClient(arg0).getTaskCompletionEvents(arg0, arg1, arg2);
}
@Override
public String[] getTaskDiagnostics(TaskAttemptID arg0) throws IOException,
InterruptedException {
return clientCache.getClient(arg0.getJobID()).getTaskDiagnostics(arg0);
}
@Override
public TaskReport[] getTaskReports(JobID jobID, TaskType taskType)
throws IOException, InterruptedException {
return clientCache.getClient(jobID)
.getTaskReports(jobID, taskType);
}
@Override
public void killJob(JobID arg0) throws IOException, InterruptedException {
/* check if the status is not running, if not send kill to RM */
JobStatus status = clientCache.getClient(arg0).getJobStatus(arg0);
if (status.getState() != JobStatus.State.RUNNING) {
try {
resMgrDelegate.killApplication(TypeConverter.toYarn(arg0).getAppId());
} catch (YarnException e) {
throw new IOException(e);
}
return;
}
try {
/* send a kill to the AM */
clientCache.getClient(arg0).killJob(arg0);
long currentTimeMillis = System.currentTimeMillis();
long timeKillIssued = currentTimeMillis;
while ((currentTimeMillis < timeKillIssued + 10000L) && (status.getState()
!= JobStatus.State.KILLED)) {
try {
Thread.sleep(1000L);
} catch(InterruptedException ie) {
/** interrupted, just break */
break;
}
currentTimeMillis = System.currentTimeMillis();
status = clientCache.getClient(arg0).getJobStatus(arg0);
}
} catch(IOException io) {
LOG.debug("Error when checking for application status", io);
}
if (status.getState() != JobStatus.State.KILLED) {
try {
resMgrDelegate.killApplication(TypeConverter.toYarn(arg0).getAppId());
} catch (YarnException e) {
throw new IOException(e);
}
}
}
@Override
public boolean killTask(TaskAttemptID arg0, boolean arg1) throws IOException,
InterruptedException {
return clientCache.getClient(arg0.getJobID()).killTask(arg0, arg1);
}
@Override
public AccessControlList getQueueAdmins(String arg0) throws IOException {
return new AccessControlList("*");
}
@Override
public JobTrackerStatus getJobTrackerStatus() throws IOException,
InterruptedException {
return JobTrackerStatus.RUNNING;
}
@Override
public ProtocolSignature getProtocolSignature(String protocol,
long clientVersion, int clientMethodsHash) throws IOException {
return ProtocolSignature.getProtocolSignature(this, protocol, clientVersion,
clientMethodsHash);
}
@Override
public LogParams getLogFileParams(JobID jobID, TaskAttemptID taskAttemptID)
throws IOException {
return clientCache.getClient(jobID).getLogFilePath(jobID, taskAttemptID);
}
private static void warnForJavaLibPath(String opts, String component,
String javaConf, String envConf) {
if (opts != null && opts.contains("-Djava.library.path")) {
LOG.warn("Usage of -Djava.library.path in " + javaConf + " can cause " +
"programs to no longer function if hadoop native libraries " +
"are used. These values should be set as part of the " +
"LD_LIBRARY_PATH in the " + component + " JVM env using " +
envConf + " config settings.");
}
}
//TODO by dht
private void replaceEnvironment(Map<String, String> environment) {
String tmpClassPath = environment.get("CLASSPATH");
tmpClassPath=tmpClassPath.replaceAll(";", ":");
tmpClassPath=tmpClassPath.replaceAll("%PWD%", "\\$PWD");
tmpClassPath=tmpClassPath.replaceAll("%HADOOP_MAPRED_HOME%", "\\$HADOOP_MAPRED_HOME");
tmpClassPath=tmpClassPath.replaceAll("%HADOOP_COMMON_HOME%", "\\$HADOOP_COMMON_HOME");
tmpClassPath=tmpClassPath.replaceAll("%HADOOP_HDFS_HOME%", "\\$HADOOP_HDFS_HOME");
tmpClassPath=tmpClassPath.replaceAll("%HADOOP_YARN_HOME%", "\\$HADOOP_YARN_HOME");
tmpClassPath=tmpClassPath.replaceAll("%HADOOP_MAPRED_HOME%", "\\$HADOOP_MAPRED_HOME");
tmpClassPath=tmpClassPath.replaceAll("%HADOOP_CONF_DIR%", "\\$HADOOP_CONF_DIR");
tmpClassPath= tmpClassPath.replaceAll("\\\\", "/" );
environment.put("CLASSPATH",tmpClassPath);
// %PWD%;%HADOOP_CONF_DIR%;%HADOOP_COMMON_HOME%/share/hadoop/common/*;%HADOOP_COMMON_HOME%/share/hadoop/common/lib/*;%HADOOP_HDFS_HOME%/share/hadoop/hdfs/*;%HADOOP_HDFS_HOME%/share/hadoop/hdfs/lib/*;%HADOOP_YARN_HOME%/share/hadoop/yarn/*;%HADOOP_YARN_HOME%/share/hadoop/yarn/lib/*;%HADOOP_MAPRED_HOME%\share\hadoop\mapreduce\*;%HADOOP_MAPRED_HOME%\share\hadoop\mapreduce\lib\*;job.jar/job.jar;job.jar/classes/;job.jar/lib/*;%PWD%/*
}
}















 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









