







源码中:job提交三个信息(jar包,xml,切片信息),在本地不需要提交jar包,只有在集群上才需要提交。
详细流程
1.WordCountDriver类中job提交
boolean result = job.waitForCompletion(true);
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
...
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
2.waitForCompletion(boolean verbose)进入submit()提交。
public boolean waitForCompletion(boolean verbose) throws IOException, InterruptedException, ClassNotFoundException {
if (this.state == Job.JobState.DEFINE) { //默认是DEFINE
this.submit();
}
if (verbose) {
this.monitorAndPrintJob();
} else {
int completionPollIntervalMillis = getCompletionPollInterval(this.cluster.getConf());
while(!this.isComplete()) {
try {
Thread.sleep((long)completionPollIntervalMillis);
} catch (InterruptedException var4) {
}
}
}
return this.isSuccessful();
}
3.submit()
public void submit() throws IOException, InterruptedException, ClassNotFoundException {
this.ensureState(Job.JobState.DEFINE); //确保状态是正确的,只抛出异常
this.setUseNewAPI(); //处理新旧API的兼容
this.connect(); //建立连接
final JobSubmitter submitter = this.getJobSubmitter(this.cluster.getFileSystem(), this.cluster.getClient());
this.status = (JobStatus)this.ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException, ClassNotFoundException {
return submitter.submitJobInternal(Job.this, Job.this.cluster);
}
});
this.state = Job.JobState.RUNNING;
LOG.info("The url to track the job: " + this.getTrackingURL());
}
4.connect():处理客户端的连接,与集群进行交互。如果与集群连接则需要yarn进行相连。
synchronized void connect() throws IOException, InterruptedException, ClassNotFoundException {
if (this.cluster == null) {
this.cluster = (Cluster)this.ugi.doAs(new PrivilegedExceptionAction<Cluster>() {
public Cluster run() throws IOException, InterruptedException, ClassNotFoundException {
return new Cluster(Job.this.getConfiguration()); //创建Cluster类,即创建提交Job的代理
}
});
}
}
5.Cluster构造器
public Cluster(Configuration conf) throws IOException {
this((InetSocketAddress)null, conf);
}
public Cluster(InetSocketAddress jobTrackAddr, Configuration conf) throws IOException {
this.fs = null;
this.sysDir = null;
this.stagingAreaDir = null;
this.jobHistoryDir = null;
this.providerList = null;
this.conf = conf;
this.ugi = UserGroupInformation.getCurrentUser();
// 判断是本地运行环境还是yarn集群运行环境
this.initialize(jobTrackAddr, conf);
}
6.Cluste初始化initialize(jobTrackAddr, conf)判断是yarn的客户端还是本地客户端
private void initialize(InetSocketAddress jobTrackAddr, Configuration conf) throws IOException {
this.initProviderList();
IOException initEx = new IOException("Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses.");
if (jobTrackAddr != null) {
LOG.info("Initializing cluster for Job Tracker=" + jobTrackAddr.toString());
}
Iterator var4 = this.providerList.iterator();
while(var4.hasNext()) {// 判断是本地运行环境还是yarn集群运行环境
ClientProtocolProvider provider = (ClientProtocolProvider)var4.next(); //有yarn的客户端和本地客户端
LOG.debug("Trying ClientProtocolProvider : " + provider.getClass().getName());
ClientProtocol clientProtocol = null;
try {
if (jobTrackAddr == null) {
clientProtocol = provider.create(conf);
} else {
clientProtocol = provider.create(jobTrackAddr, conf);
}
if (clientProtocol != null) {
this.clientProtocolProvider = provider;
this.client = clientProtocol;
LOG.debug("Picked " + provider.getClass().getName() + " as the ClientProtocolProvider");
break;
}
LOG.debug("Cannot pick " + provider.getClass().getName() + " as the ClientProtocolProvider - returned null protocol");
} catch (Exception var9) {
String errMsg = "Failed to use " + provider.getClass().getName() + " due to error: ";
initEx.addSuppressed(new IOException(errMsg, var9));
LOG.info(errMsg, var9);
}
}
if (null == this.clientProtocolProvider || null == this.client) {
throw initEx;
}
}
7.提交job,submit()中的submitJobInternal(Job.this, Job.this.cluster)
JobStatus submitJobInternal(Job job, Cluster cluster) throws ClassNotFoundException, InterruptedException, IOException {
this.checkSpecs(job); //验证输出路径
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
// 1)创建给集群提交数据的Stag路径,用于临时缓存
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
this.submitHostAddress = ip.getHostAddress();
this.submitHostName = ip.getHostName();
conf.set("mapreduce.job.submithostname", this.submitHostName);
conf.set("mapreduce.job.submithostaddress", this.submitHostAddress);
}
// 2)获取jobid ,并创建Job路径
JobID jobId = this.submitClient.getNewJobID();
job.setJobID(jobId);
//在刚才的路径后面加入jobid
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
JobStatus var25;
try {
conf.set("mapreduce.job.user.name", UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers", "org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set("mapreduce.job.dir", submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir + " as the submit dir");
TokenCache.obtainTokensForNamenodes(job.getCredentials(), new Path[]{submitJobDir}, conf);
this.populateTokenCache(conf, job.getCredentials());
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance("HmacSHA1");
keyGen.init(64);
} catch (NoSuchAlgorithmException var20) {
throw new IOException("Error generating shuffle secret key", var20);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(), job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt("mapreduce.am.max-attempts", 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediatedata spill is enabled");
}
// 3)拷贝jar包到集群
this.copyAndConfigureFiles(job, submitJobDir);
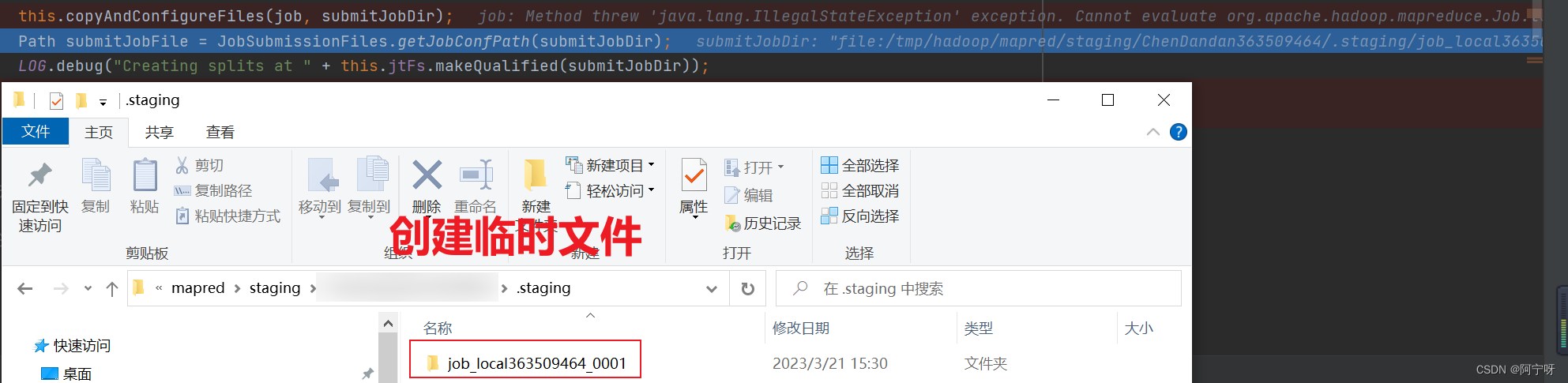
//创建一个带有job_id的临时空文件夹
//如果是集群模式,在向集群提交代码的时候,客户端模式当前代码的Jar包是一定会被上传到yarn集群的。
//如果是本地模式,jar包就在本地,不需要提交
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
LOG.debug("Creating splits at " + this.jtFs.makeQualified(submitJobDir));
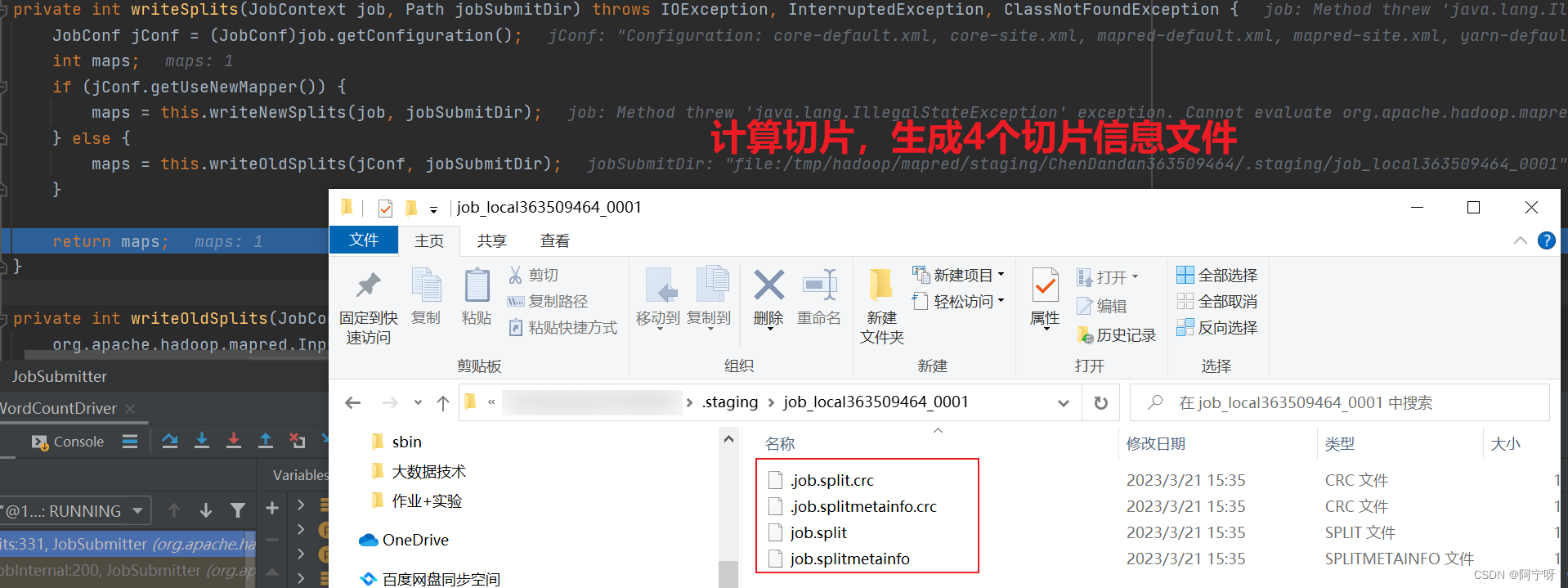
// 4)计算切片,生成切片4个规划文件,
int maps = this.writeSplits(job, submitJobDir);
// MapTask个数 = 切片个数,切片个数给MapTask个数赋值
conf.setInt("mapreduce.job.maps", maps);
LOG.info("number of splits:" + maps);
int maxMaps = conf.getInt("mapreduce.job.max.map", -1);
if (maxMaps >= 0 && maxMaps < maps) {
throw new IllegalArgumentException("The number of map tasks " + maps + " exceeded limit " + maxMaps);
}
String queue = conf.get("mapreduce.job.queuename", "default");
AccessControlList acl = this.submitClient.getQueueAdmins(queue);
conf.set(QueueManager.toFullPropertyName(queue, QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean("mapreduce.job.token.tracking.ids.enabled", false)) {
ArrayList<String> trackingIds = new ArrayList();
Iterator var15 = job.getCredentials().getAllTokens().iterator();
while(var15.hasNext()) {
Token<? extends TokenIdentifier> t = (Token)var15.next();
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings("mapreduce.job.token.tracking.ids", (String[])trackingIds.toArray(new String[trackingIds.size()]));
}
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set("mapreduce.job.reservation.id", reservationId.toString());
}
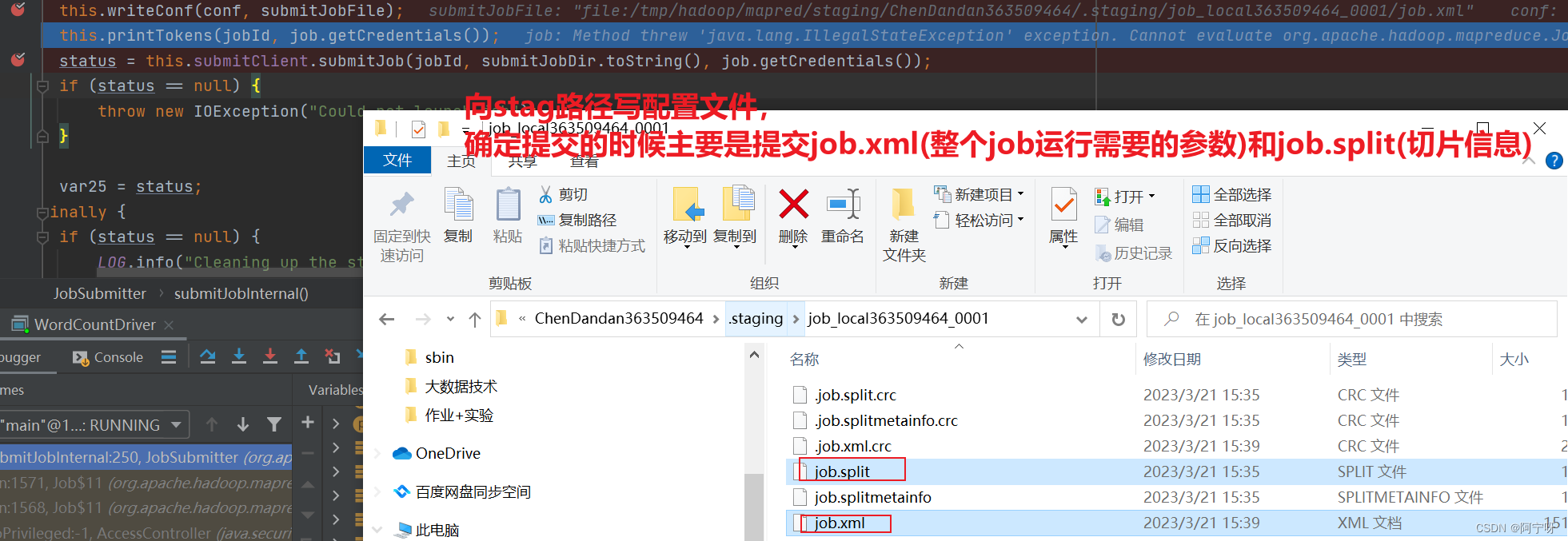
//向Stag路径写XML配置文件
//确定提交的时候主要是提交job.xml(整个job运行需要的参数)和job.split(切片信息),如果是集群yarn模式,还需要提交jar包
this.writeConf(conf, submitJobFile);
this.printTokens(jobId, job.getCredentials());
//客户端提交job信息,完成后,state变成RUNNING
status = this.submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
if (status == null) {
throw new IOException("Could not launch job");
}
var25 = status;
} finally {
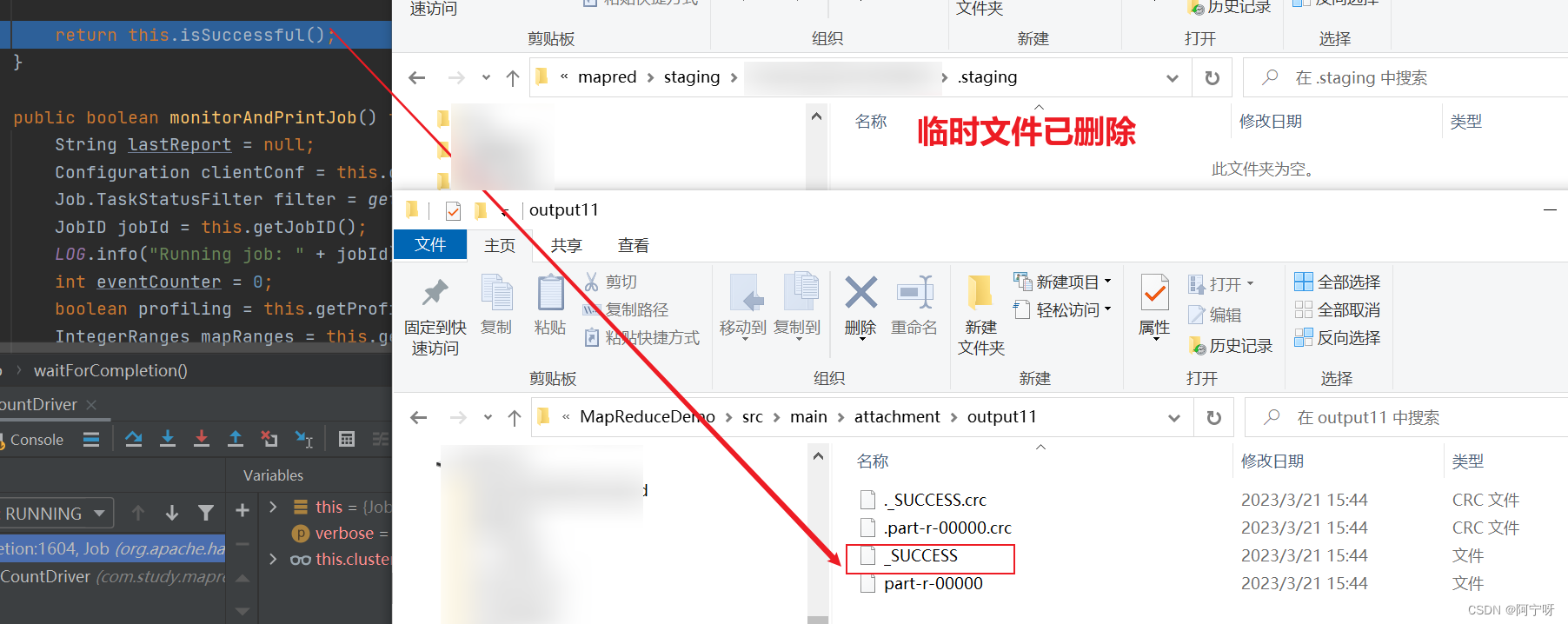
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (this.jtFs != null && submitJobDir != null) {
this.jtFs.delete(submitJobDir, true);
}
}
}
return var25;
}


8.验证输出路径,submitJobInternal(Job.this, Job.this.cluster)中的checkSpecs(job)
private void checkSpecs(Job job) throws ClassNotFoundException, InterruptedException, IOException {
label23: {
JobConf jConf = (JobConf)job.getConfiguration();
if (jConf.getNumReduceTasks() == 0) {
if (jConf.getUseNewMapper()) {
break label23;
}
} else if (jConf.getUseNewReducer()) {
break label23;
}
//checkOutputSpecs检查输出路径是否存在(即输出路径的参数必须给出,且不能存在)
jConf.getOutputFormat().checkOutputSpecs(this.jtFs, jConf);
return;
}
OutputFormat<?, ?> output = (OutputFormat)ReflectionUtils.newInstance(job.getOutputFormatClass(), job.getConfiguration());
output.checkOutputSpecs(job);
}
9.检查输出路径是否存在,checkSpecs(job)中的checkOutputSpecs(this.jtFs, jConf)
private void copyAndConfigureFiles(Job job, Path jobSubmitDir) throws IOException {
Configuration conf = job.getConfiguration();
boolean useWildcards = conf.getBoolean("mapreduce.client.libjars.wildcard", true);
JobResourceUploader rUploader = new JobResourceUploader(this.jtFs, useWildcards);
rUploader.uploadResources(job, jobSubmitDir);
job.getWorkingDirectory();
}
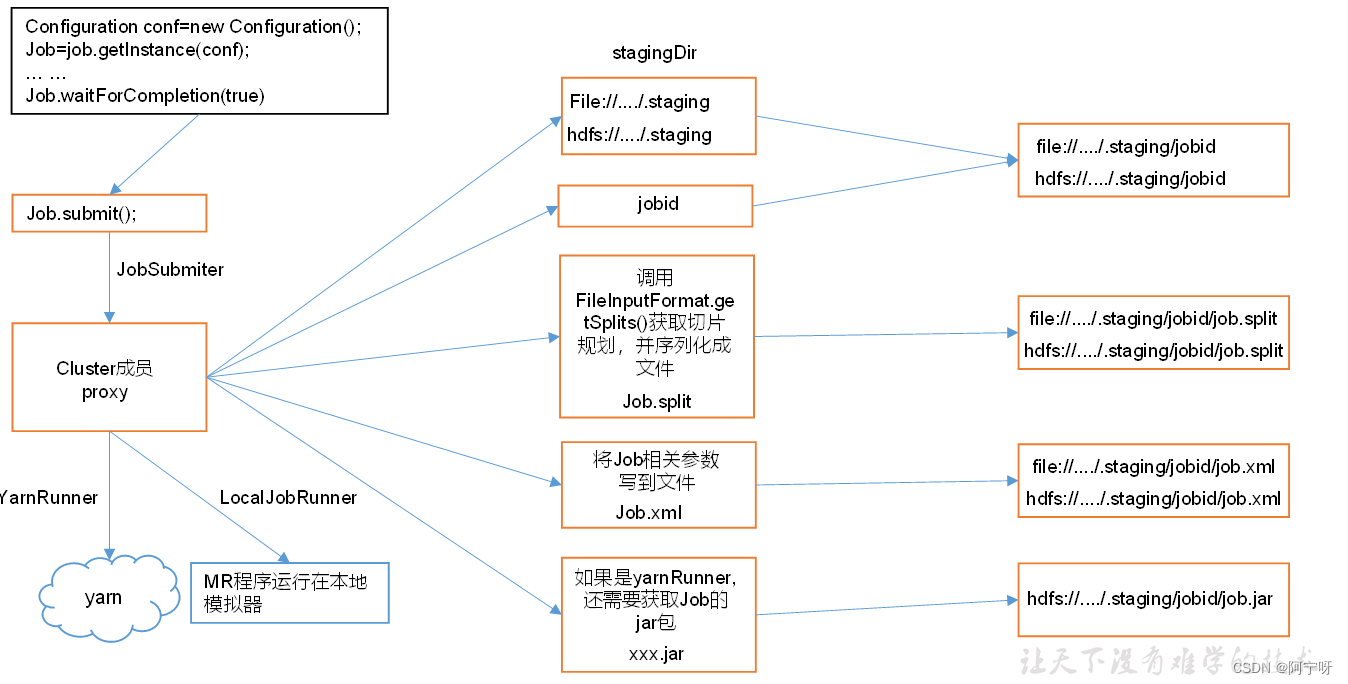
总结
waitForCompletion()
submit();
// 1建立连接
connect();
// 1)创建提交Job的代理
new Cluster(getConfiguration());
//(1)判断是本地运行环境还是yarn集群运行环境
initialize(jobTrackAddr,conf);
// 2 提交job
submitter.submitJobInternal(Job.this,cluster)
// 1)创建Stag路径,提交给集群,用于临时缓存文件
Path jobStagingArea =JobSubmissionFiles.getStagingDir(cluster, conf);
// 2)创建jobid ,并创建Job路径
JobID jobId = submitClient.getNewJobID();
// 3)如果是集群模式,则拷贝jar包到集群;本地则不需要
copyAndConfigureFiles(job,submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4)计算切片,生成切片信息文件
writeSplits(job,submitJobDir);
maps= writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5)向Stag路径写XML配置文件
writeConf(conf,submitJobFile);
conf.writeXml(out);
// 6)提交Job,返回提交状态,即状态从DEFINE转为RUNNIN
status =submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());















 390
390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









