







在角色扮演类游戏中,玩家需要在游戏里领取任务。有的人喜欢一次只领取一个任务,把这个任务做完,再去领下一个任务,这就叫作深度优先搜索。还有一些人喜欢先把能够领取的所有任务一次性领取完,然后去慢慢完成,最后再一次性把任务奖励都领取了,这就叫作广度优先搜索。
一、深度优先搜索
假设下图是某在线教育网站的课程分类,需要爬取上面的课程信息。从首页开始,课程有几个大的分类,比如根据语言分为Python、Node.js和Golang。每个大分类下面又有很多的课程,比如Python下面有爬虫、Django和机器学习。每个课程又分为很多的课时。
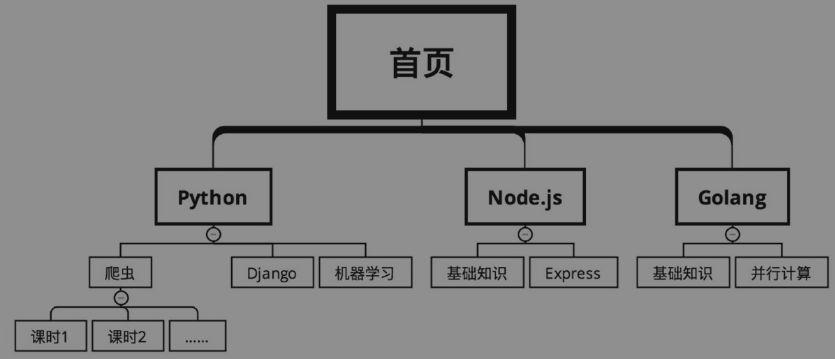
在深度优先搜索的情况下,爬取路线如下图所示(序号从小到大)。

路线为“首页→Python→爬虫→课时1→课时2→……→课时N→Django→机器学习→Node.js→基础知识→Express→Golang→基础知识→并行计算”。也就是说,把爬虫的所有课时都爬取完成,再爬取Django的所有课程,接着爬取机器学习的所有课程,之后再去爬取Node.js的所有信息……
二、广度优先搜索
在广度优先搜索的情况下,爬取路线如下图所示(序号从小到大)。
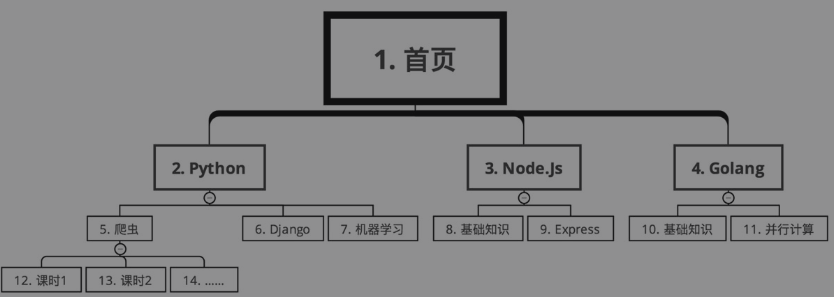
路线为“首页→Python→Node.js→Golang→爬虫→Django→机器学习→基础知识→Express→基础知识→并行计算→课时1→课时2→……→课时N”。也就是说,首先爬取每个大分类的信息,然后从第1个大分类中爬取所有的课程信息,爬完了第1个大分类,再爬第2个大分类,直到所有大分类下面的课程信息都搞定了,再爬第一个课程的所有课时信息……
三、爬虫搜索算法的选择
在爬虫开发的过程中,应该选择深度优先还是广度优先呢?这就需要根据被爬取的数据来进行选择了。
例如要爬取某网站全国所有的餐馆信息和每个餐馆的订单信息。假设使用深度优先算法,那么先从某个链接爬到了餐馆A,再立刻去爬餐馆A的订单信息。由于全国有十几万家餐馆,全部爬完可能需要12小时。这样导致的问题就是,餐馆A的订单量可能是早上8点爬到的,而餐馆B是晚上8点爬到的。它们的订单量差了12小时。而对于热门餐馆来说,12小时就有可能带来几百万的收入差距。这样在做数据分析时,12小时的时间差就会导致难以对比A和B两个餐馆的销售业绩。
相对于订单量来说,餐馆的数量变化要小得多。所以如果采用广度优先搜索,先在半夜0点到第二天中午12点把所有的餐馆都爬取一遍,第二天下午14点到20点再集中爬取每个餐馆的订单量。这样做,只用了6个小时就完成了订单爬取任务,缩小了由时间差异致的订单量差异。同时由于店铺隔几天抓一次影响也不大,所以请求量也减小了,使爬虫更难被网站发现。
又例如,要分析实时舆情,需要爬百度贴吧。一个热门的贴吧可能有几万页的帖子,假设最早的帖子可追溯到2010年。如果采用广度优先搜索,则先把这个贴吧所有帖子的标题和网址都获取下来,然后根据这些网址进入每个帖子里面以获取每一层楼的信息。可是,既然是实时舆情,那么7年前的帖子对现在的分析意义不大,更重要的应该是新的帖子才对,所以应该优先抓取新的内容。
相对于过往的内容,实时的内容才最为重要。因此,对于贴吧内容的爬取,应该采用深度优先搜索。看到一个帖子就赶紧进去,爬取它的每个楼层信息,一个帖子爬完了再爬下一个帖子。
当然,这两种搜索算法并非非此即彼,需要根据实际情况灵活选择,很多时候也能够同时使用。
--------------------------------------
版权声明:本文为【PythonJsGo】博主的文章,同步在【猿小猴子】WeChat平台,转载请附上原文出处链接及本声明。
--------------------------------------














 1168
1168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









