







在前一段时间在看论文相关的工作,没有时间整理对这篇论文的理解。在前面的一篇博客【1】中有提到Selective Search【2】,其前期工作利用图像分割的方法得到一些原始区域(具体内容请查看【1】),然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,而这些结构就包含着可能需要的物体。
博客【3】已经有对这篇论文的一些简单介绍,写这篇博客不免有重复发明轮子之嫌,不想想太多,只想把自己的一些理解记录下来,加深自己的理解。
这篇论文是J.R.R. Uijlings发表在2012 IJCV上的一篇文章,主要介绍了选择性搜索(Selective Search)的方法。物体识别(Object Recognition),在图像中找到确定一个物体,并找出其为具体位置,经过长时间的发展已经有了不少成就。之前的做法主要是基于穷举搜索(Exhaustive Search),选择一个窗口(window)扫描整张图像(image),改变窗口的大小,继续扫描整张图像。显然这种做法是比较“原始的”,改变窗口大小,扫描整张图像,直观上就给人一种非常耗时,结果太杂的印象。作者能够突破思维定式,从另一个角度给出一种简单而又有效的方法,油生敬意。我们不禁会想,为什么这么简单的方法之前没有想到呢。我想这个应该跟对图像认识的观念有关系,在都不知道如何做物体识别(Object Recognition)的时候,较为“原始的”穷举搜索方法,给了大家一个方向,之后所有的人都沿着这个方向走,最后就忽略了对其他方向的认识。花费了这么多年,才找到另一个方向,这个转变实属不易。扯远了,总之,这种方法确实让人耳目一新。
一、介绍(Introduction)
图像(Image)包含的信息非常的丰富,其中的物体(Object)有不同的形状(shape)、尺寸(scale)、颜色(color)、纹理(texture),要想从图像中识别出一个物体非常的难,还要找到物体在图像中的位置,这样就更难了。下图给出了四个例子,来说明物体识别(Object Recognition)的复杂性以及难度。(a)中的场景是一张桌子,桌子上面放了碗,瓶子,还有其他餐具等等。比如要识别“桌子”,我们可能只是指桌子本身,也可能包含其上面的其他物体。这里显示出了图像中不同物体之间是有一定的层次关系的。(b)中给出了两只猫,可以通过纹理(texture)来找到这两只猫,却又需要通过颜色(color)来区分它们。(c)中变色龙和周边颜色接近,可以通过纹理(texture)来区分。(d)中的车辆,我们很容易把车身和车轮看做一个整体,但它们两者之间在纹理(texture)和颜色(color)方面差别都非常地大。

上面简单说明了一下在做物体识别(Object Recognition)过程中,不能通过单一的策略来区分不同的物体,需要充分考虑图像物体的多样性(diversity)。另外,在图像中物体的布局有一定的层次(hierarchical)关系,考虑这种关系才能够更好地对物体的类别(category)进行区分。
在深入介绍Selective Search之前,先说说其需要考虑的几个问题:
1. 适应不同尺度(Capture All Scales):穷举搜索(Exhaustive Selective)通过改变窗口大小来适应物体的不同尺度,选择搜索(Selective Search)同样无法避免这个问题。算法采用了图像分割(Image Segmentation)以及使用一种层次算法(Hierarchical Algorithm)有效地解决了这个问题。
2. 多样化(Diversification):单一的策略无法应对多种类别的图像。使用颜色(color)、纹理(texture)、大小(size)等多种策略对(【1】中分割好的)区域(region)进行合并。
3. 速度快(Fast to Compute):算法,就像功夫一样,唯快不破!
二、区域合并算法
这里是基于区域的合并,区域包含的信息比像素丰富,更能够有效地代表物体的特征。关于区域用于物体识别的的方法,请参考论文【4】,这里不再多说,以后有空话,在博客中写点东西。首先原始区域的获取方法,可以查看博客【1】以及其相关的论文。区域的合并方式是有层次的(hierarchical),类似于哈夫曼树的构造过程。

输入:彩色图片(三通道)
输出:物体位置的可能结果L
1. 使用 Efficient Graph-Based Image Segmentation【1】的方法获取原始分割区域R={r1,r2,…,rn}
2. 初始化相似度集合S=∅
3. 计算两两相邻区域之间的相似度(见第三部分),将其添加到相似度集合S中
4. 从相似度集合S中找出,相似度最大的两个区域 ri 和rj,将其合并成为一个区域 rt,从相似度集合中除去原先与ri和rj相邻区域之间计算的相似度,计算rt与其相邻区域(原先与ri或rj相邻的区域)的相似度,将其结果添加的到相似度集合S中。同时将新区域 rt 添加到 区域集合R中。
5. 获取每个区域的Bounding Boxes,这个结果就是物体位置的可能结果L
三、多样化策略
论文作者给出了两个方面的多样化策略:颜色空间多样化,相似多样化。
颜色空间多样化
作者采用了8中不同的颜色方式,主要是为了考虑场景以及光照条件等。这个策略主要应用于【1】中图像分割算法中原始区域的生成。主要使用的颜色空间有:(1)RGB,(2)灰度I,(3)Lab,(4)rgI(归一化的rg通道加上灰度),(5)HSV,(6)rgb(归一化的RGB),(7)C(具体请看论文【2】以及【5】),(8)H(HSV的H通道)
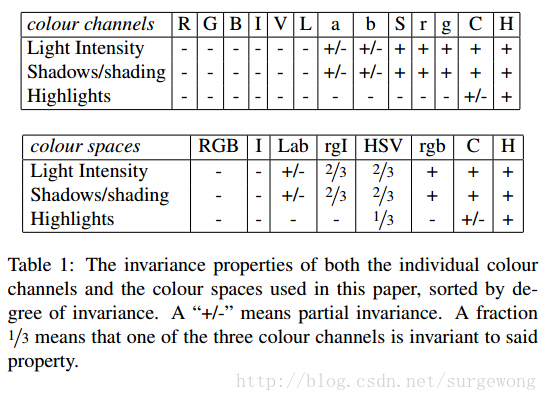
对颜色空间了解不深,在此不便深入说明,等着以后慢慢深入计算机视觉领域。
相似度计算多样化
在区域合并的时候有说道计算区域之间的相似度,论文章介绍了四种相似度的计算方法。
1. 颜色(color)相似度
使用L1-norm归一化获取图像每个颜色通道的25 bins的直方图,这样每个区域都可以得到一个75维的向量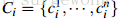 ,区域之间颜色相似度通过下面的公式计算:
,区域之间颜色相似度通过下面的公式计算:
,区域之间颜色相似度通过下面的公式计算:
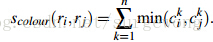
在区域合并过程中使用需要对新的区域进行计算其直方图,计算方法:
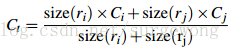
2. 纹理(texture)相似度
这里的纹理采用SIFT-Like特征。具体做法是对每个颜色通道的8个不同方向计算方差σ=1的高斯微分(Gaussian Derivative),每个通道每个颜色获取10 bins的直方图(L1-norm归一化),这样就可以获取到一个240维的向量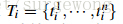 ,区域之间纹理相似度计算方式和颜色相似度计算方式类似,合并之后新区域的纹理特征计算方式和颜色特征计算相同:
,区域之间纹理相似度计算方式和颜色相似度计算方式类似,合并之后新区域的纹理特征计算方式和颜色特征计算相同:
,区域之间纹理相似度计算方式和颜色相似度计算方式类似,合并之后新区域的纹理特征计算方式和颜色特征计算相同:

3. 大小(size)相似度
这里的大小是指区域中包含像素点的个数。使用大小的相似度计算,主要是为了尽量让小的区域先合并:
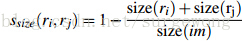
4. 吻合(fit)相似度
这里主要是为了衡量两个区域是否更加“吻合”,其指标是合并后的区域的Bounding Box(能够框住区域的最小矩形(没有旋转))越小,其吻合度越高。其计算方式:
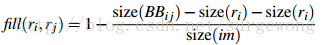
最后将上述相似度计算方式组合到一起,可以写成如下,其中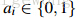 :
:
:
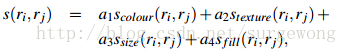
四、使用选择搜索(Selective Search)进行物体识别
通过前面的区域合并,可以得到一些列物体的位置假设L。接下来的任务就是如何从中找出物体的真正位置并确定物体的类别。 常用的物体识别特征有HOG(Histograms of oriented gradients)和 bag-of-words 两种特征。在穷举搜索(Exhaustive Search)方法中,寻找合适的位置假设需要花费大量的时间,能选择用于物体识别的特征不能太复杂,只能使用一些耗时少的特征。由于选择搜索(Selective Search)在得到物体的位置假设这一步效率较高,其可以采用诸如SIFT等运算量大,表示能力强的特征。在分类过程中,系统采用的是SVM。
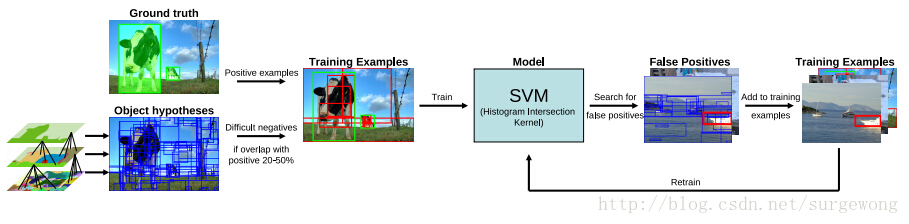
特征生成
系统在实现过程中,使用color-SIFT特征【6】以及spatial pyramid divsion方法【7】。在一个尺度下σ=1.2下抽样提取特征。使用SIFT、Extended OpponentSIFT【8】、RGB-SIFT【6】特征,在四层金字塔模型 1×1、2×2、3×3、4×4,提取特征,可以得到一个维的特征向量。(注:对SIFT特征以及金字塔模型还不是很了解,讲得不是很清楚)
训练过程
训练方法采用SVM。首先选择包含真实结果(ground truth)的物体窗口作为正样本(positive examples),选择与正样本窗口重叠20%~50%的窗口作为负样本(negative examples)。在选择样本的过程中剔除彼此重叠70%的负样本,这样可以提供一个较好的初始化结果。在重复迭代过程中加入hard negative examples(得分很高的负样本)【9】,由于训练模型初始化结果较好,模型只需要迭代两次就可以了。(样本的筛选很重要!!)
五、性能评价
很自然地,通过算法计算得到的包含物体的Bounding Boxes与真实情况(ground truth)的窗口重叠越多,那么算法性能就越好。这是使用的指标是平均最高重叠率ABO(Average Best Overlap)。对于每个固定的类别 c,每个真实情况(ground truth)表示为 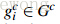 ,令计算得到的位置假设L中的每个值l,那么 ABO的公式表达为:
,令计算得到的位置假设L中的每个值l,那么 ABO的公式表达为:
,令计算得到的位置假设L中的每个值l,那么 ABO的公式表达为:
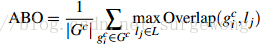
重叠率的计算方式:
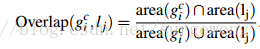
上面结果给出的是一个类别的ABO,对于所有类别下的性能评价,很自然就是使用所有类别的ABO的平均值MABO(Mean Average Best Overlap)来评价。
上面基本上讲了一下,这篇论文的框架,在【2】中可以下载得到该论文相对应的matlab代码(也可以在【10】中下载)。通过该代码,获取得到图像中物体的位置假设L。之后我们可以利用这个结果进行更加深入的研究。由于原matlab代码中部分代码经过了加密,正在使用C++对其进行重写,得到结果完善之后,会将其公开。由于入门不深,上面的理解不免有些错误,望各位指正,希望与大家多多交流~~
补充于: 2015-02-05
受各种杂事的影响,很久没有更新博客。现在在学机器学习相关的知识,图像分割相关的代码没有来得及整理,只好把之前的工程直接打包。其中不免有些错误或者不足,忘广大博友们指正。C++代码只是对相关的matlab代码部分工程的重写,没有仔细比对两者之间的性能,不过对雨了解其原理还是有很大帮助的,希望对初学者有所帮助。代码下载链接【11】。
参考资料:
【8】Illumination-invariant descriptors for discrimative visual object categorization,Technical report, University of Amsterdam(没有找到相关链接)
【10】相关源代码(matlab)
【11】C++简版代码















 1358
1358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









