







看了一段时间的目标检测的论文,在这里写个文章总结一下吧。不一定理解正确,如有问题,欢迎指正。
1、RCNN
RCNN是基于selective search(SS) 搜索Region proposal(RP),然后对每个RP进行CNN的Inference,这个算法比较直接。
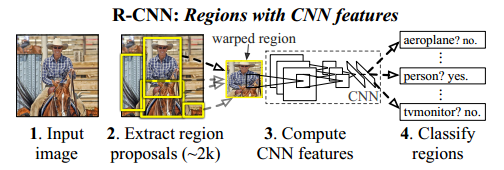
框架应该也挺容易看明白的。
SS对每幅图片提取大约2K个RP,然后对RP进行推理。
2、SPPNET
RCNN的计算很多是没有必要的,因为框有重叠啊,既然被计算过,何必再有让别的框再计算呢?于是Computation Sharing开始了。

conv5以前的计算,对于一幅图片只需要一次进行。
另外,SPPNET主要有三个贡献:
-
(1)SPP可以产生固定大小的特征,这使得输入图片可以是任意大小的。为什么呢?作者发现,在CNN当中,其实出了全连接以外,其他的层基本不需要固定大小。既然如此,那就让全连接之前的计算适应任何尺寸吧,只要在到达全连接的时候,让它固定尺寸就好啦!怎么做呢?就是图中的SPP。将图像以不同的pooling步长,得到固定长度的pooling结果。
-
(2)SPP使用多水平的空间bins,同时保持滑动窗的大小不变,这样可以对目标的变形比较鲁棒。
-
(3)得益于多变的输入图像尺寸,SPP可以做到不同尺度的Pooling。
问题:SPPNet仍然是多部训练的,主要原因是:SPP层是多尺度的,对于后面传过来的梯度来说,它计算梯度时涉及到的Receptive Field比较大,计算很慢。而且后面使用的分类器是SVM,应该来说是比较耗时的吧。其实SPPNET训练时,是先用SS找到RP,然后输入前面层,把特征存起来,然后在把特征加载进来输入后面层,前面层的训练和后面层的训练是分离的。
fast RCNN
这篇文章就是针对SPPNET中的问题做的,主要贡献有:
-
提出了ROIPooling。这个ROIPooling其实就是SPP的简化版。SPP不是使用了金字塔,导致梯度传递困难吗?那就只用一层的金字塔吧。不行,还得换个名字,那就叫ROIPooling。使用了ROIPooling后,得到的也是一个统一尺寸的特征,梯度也没有以前那样涉及到的感受野那么大,所以前后就可以连起来训练了。
-
多任务Loss。以前SPPNET不是Bounding Box(BB)回归和分类是分离的吗?这里就用一个多任务的Loss吧。而且分类器也不要SVM这么复杂了,只需要Softmax。
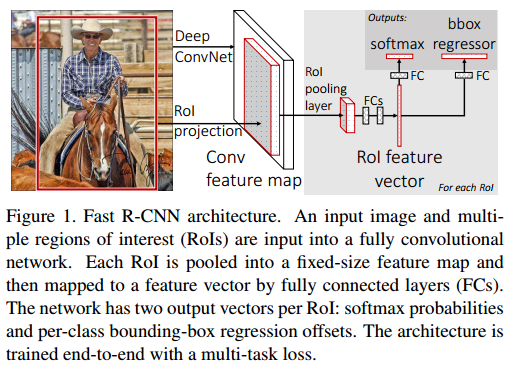
问题:这个也其实有问题的,你看SS在里面不是一直没有参与学习吗?而且SS好像是离线计算的吧?(这个需要再考证一下。)还有一个重要的问题是,后面的BB回归和分类网络再强,你也是受SS提取的RP限制的。也就是说SS可能已经成为了瓶颈。
Faster-RCNN
这篇文章其实也是承接上文的,fast RCNN不是受SS限制没法端到端地训练吗?那就做一个网络来代替SS呗。这就是Faster-RCNN重点 RPN。但是RPN怎么做呢?
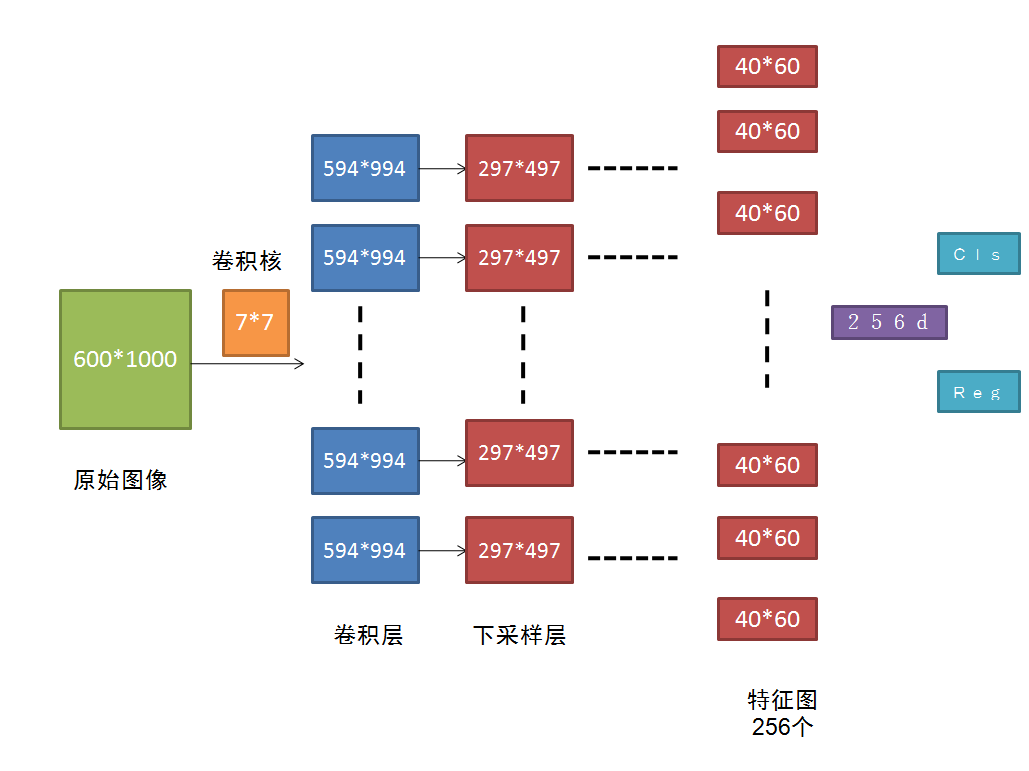
把原始图进行多次卷积后,得到的256个40*60的feature map,接下来就用一个小的卷积神经网络在这些feature map上滑动,这里有讲解。为了获得一定的尺度不变形,使用了Anchor的方式,也就是对每一个RP进行多个尺寸的变换,文章使用了9.这样,对于一个40*60的来说,总共有40*60*9个RP,还是非常多的。
这里还有个东西可能没说清楚,就是RPN的输出是什么?在每一个窗口上,RPN输出的是一个256维的特征。256怎么来的呢?就是在256个feature map上对应位置分别卷积哈。
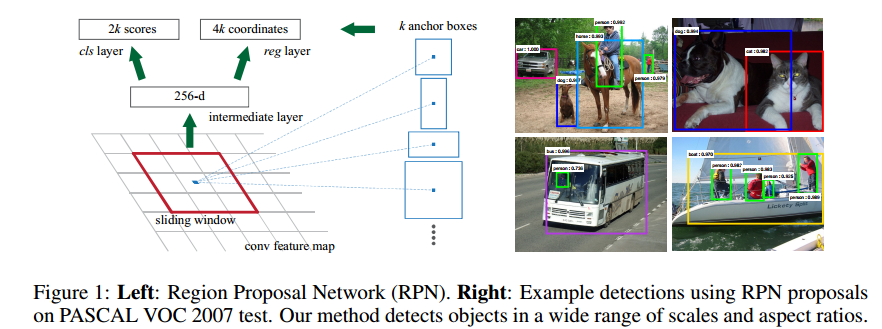
后面的分类和回归也是采用的全连接做的。
这样用来做RP的计算,其实也是被BB回归和分类共享的,因为他们的输入就是这个256d的特征啊。
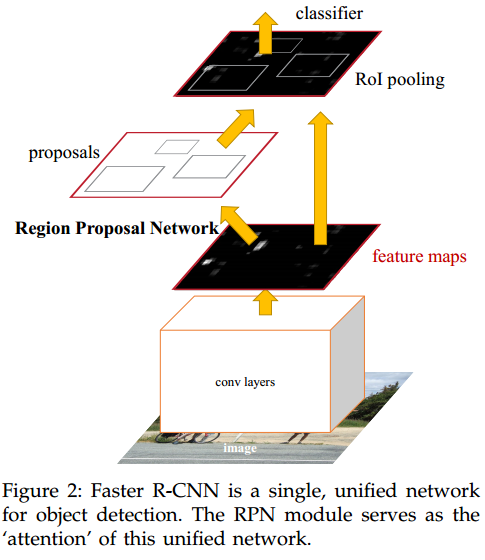
问题:这个计算复杂度还是太高了,没法达到实时性要求。
YOLO
这个网络最大的优势就在于快,怎么做到的呢?首先,那些共享计算的概念肯定是要用到的。然后就是把图像分块。
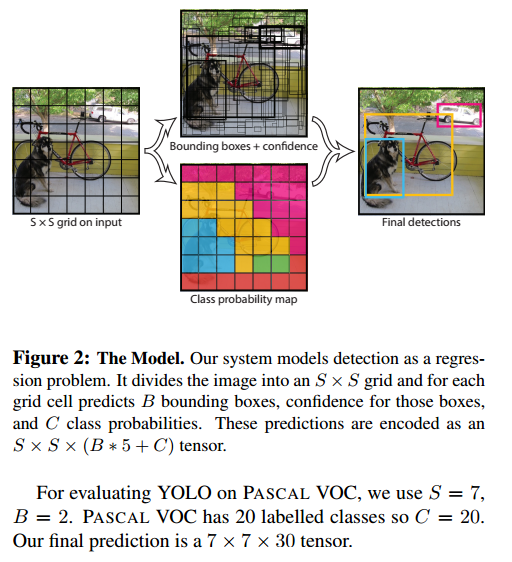
图片被分成了 S*S个格子,每个格子预测出B个BB,而每个BB包含了5个量:
x,y,w,h,confidence
。这个confidence就是对是否含有需要检测目标的一个得分吧。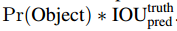
还有每个格子对这C个类的预测分。
在Test阶段,
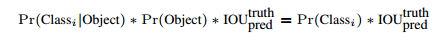
这样不就得到了目标的概率吗?真是不错啊!
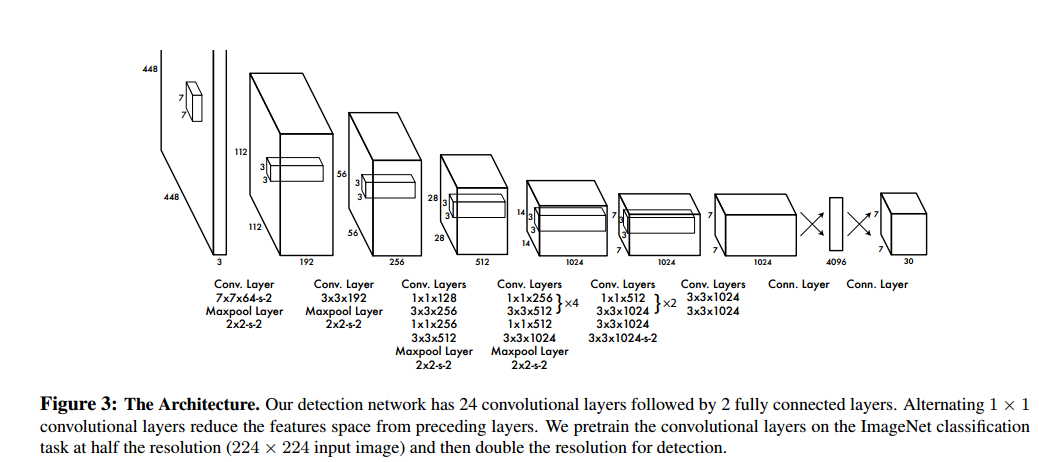
下面是网络结构:
YOLO思想和前面RPN很不一样了,现在不需要RPN了吧,就直接这么训练就好了。但是还是有问题吧,如果一个格子里面包含了多个目标,那岂不是只能回归是其中一个,而且应该是最明显的一个。这是不是就是YOLO对小目标检测很不理想啊,因为小目标在后面层中的feature本来就少。而且SSD虽然快,但是目标检测的效果却并不是令人满意。
SSD
虽然YOLO效果不佳,但是其开创性的Look once的想法还是很值得赞扬和纪念的。SSD继承了YOLO这个工作,并把它拓展开来了。
SSD中的Default Box(DB)是一个重要的工作。feature是通过卷积等操作得到的,那么feature其实还是具有相对位置信息的。把feature划分到不同的DB中,这样就可以做到和YOLO一样的效果了吧。但是这个DB是有Anchor的。
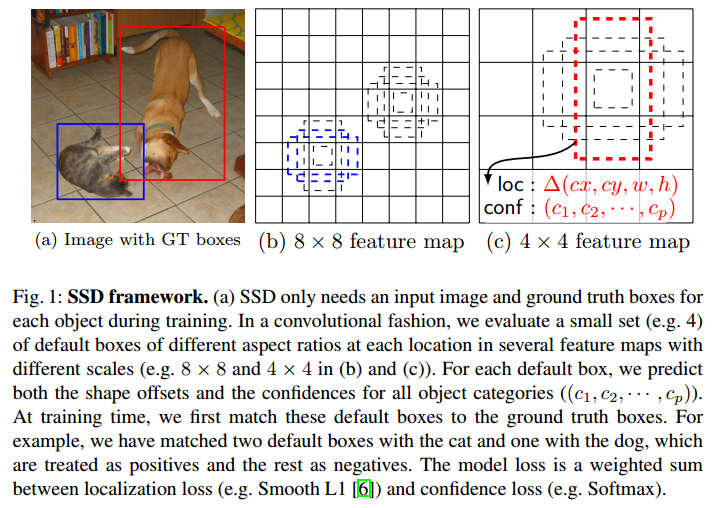
仔细看看这幅图和里面的文字吧。就算label和预测的BB是在一个DB里面,还得看看Anchor是不是吻合的。这样是不是对于回归DB来说更加准确了?
然后看看网络框架吧,这个是和YOLO的一个对比。
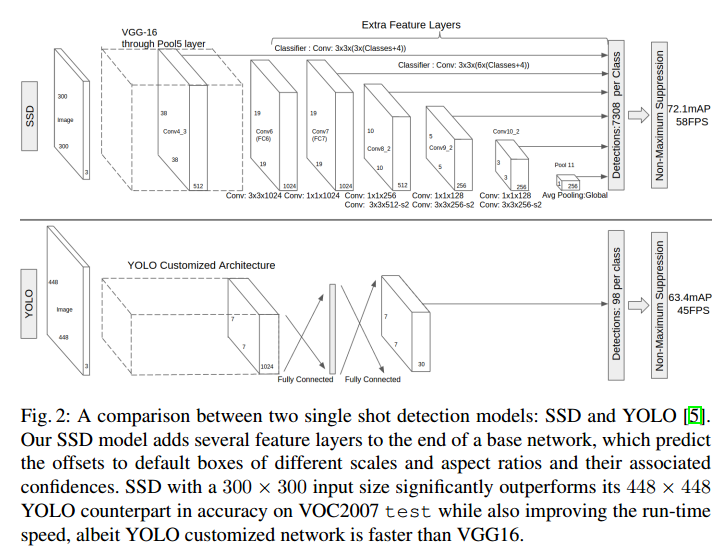
SSD前面的层和YOLO是差不多的,但是后面就不一样了。YOLO是直接拿着feature map回归出BB,还做了分类,SSD是还融合了不同层的特征。
其实,从SSD可以看出,YOLO并没有完全利用好共享计算,因为前面层提取的特征只是用来给下一层作为输入了啊,但是它还是特征啊,你就这么用了一下,其实它还包含了很多有用信息呢。怎么这样说呢?前面层feature map更大,它的细节信息保留更好。而且,一般而言,前面层偏向于提取边缘等信息。边缘对于视觉来说是非常重要的啊,如果利用起来,肯定能够有提升吧。当然,这只是一方面。
顺便提一下,这个作者另外一篇ParseNet也利用了相似的思想,可以一起看看。
Inside-Outside Network
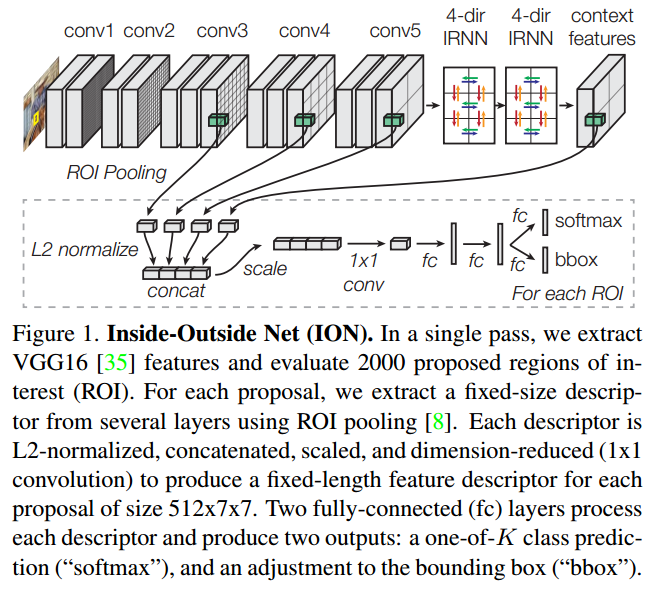
乍一看,这个ION是不是和SSD很像,是的,它也是利用了多层特征融合的方式来获得更好的特征。
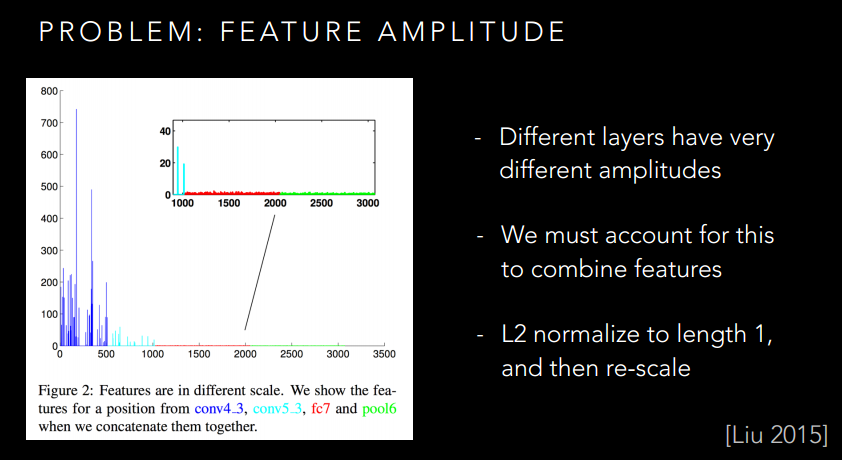
这个Skip-connection就可以很好的利用不同的特征了。然而,还是有问题的,你想想,不同层的特征是不是尺度不一样啊,而且不同层的数值还没有归一化呢?如果生搬硬套的凑在一起,是不是有点破坏原本的特征了,并不一定有很好的提升。
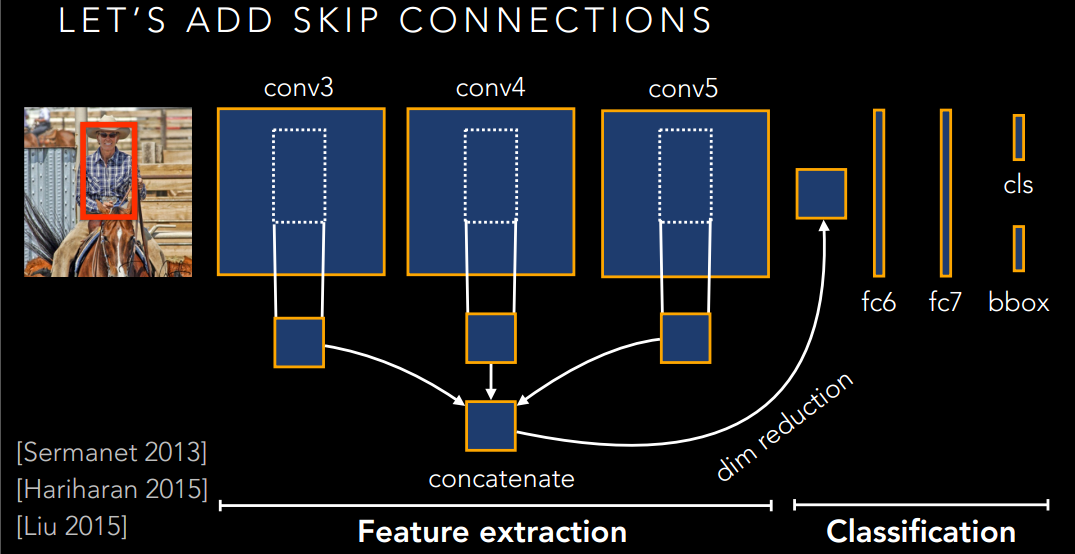
所以作者给出了下面的方法:
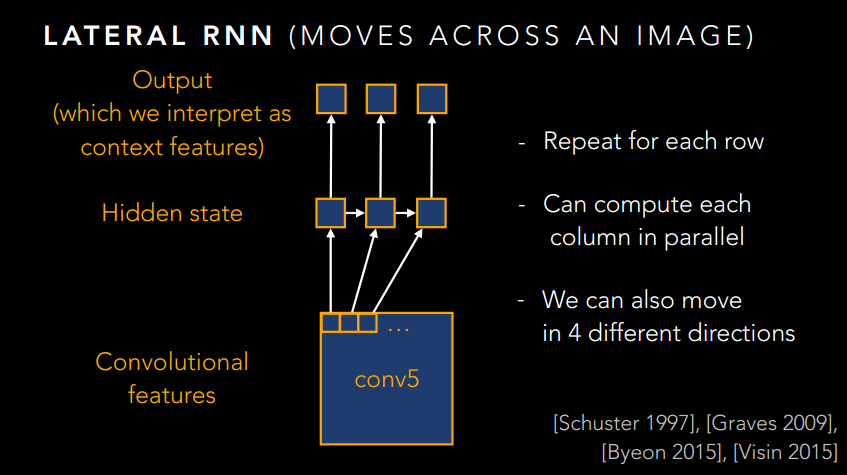
如果仅此而已,那肯定是不能称之为大作的,肯定要玩出新花样。想想这个图像其实也是一个序列问题,只不过不是时间序列的,而是空间序列的。那么,我们是不是可以引入RNN来做点序列化的文章呢?是的,作者就是这么干的!
下面就放一些RNN的图吧,感受一下大神的风采。
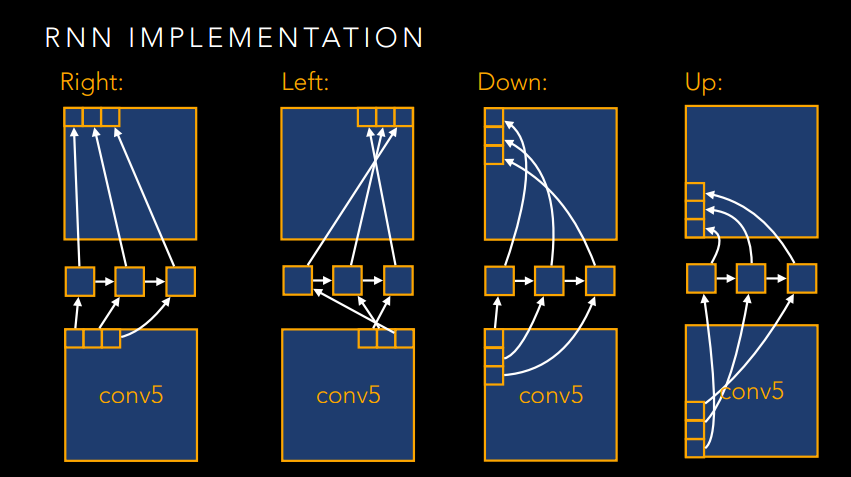
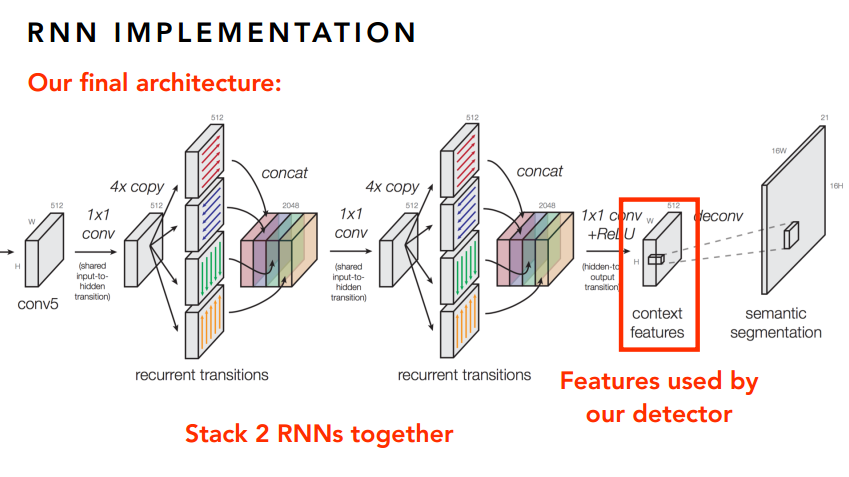
写在最后
好了,已经把目标检测的几篇论文稍微介绍一下了,但是里面很多细节都没有去多讲,要重现这些论文,肯定少不了看看原文,然后读下代码的。最好是把文章的网络可视化出来看看,一定有个不错的体会。这里有个很好的在线可视化工具哦,有兴趣的可以试试。
PS
最后就是求职的事情了。最近一直忙着招工作,却发现视觉的工作好难找啊!可能是自己学艺不精吧,但是本人一直对视觉有强烈的好奇心和兴趣,也希望能够在视觉这方面做出些成果。所以希望有一个有梦想的团队能收留我,不一定是要有很高的工资,但是一定要有抱负。另外,如果是做NLP,我也是挺有兴趣,只是暂时没有深入了解这方面,如果团队愿意带,我也挺想学的。好了,啰嗦完了,欢迎评论。
Reference
做一个相当不专业的参考文献吧,因为找不到工作,实在是有点心累。后面看了更多论文后再补吧。各位客观见谅。

















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









