







阅读论文Imbalance Problems in Object Detection: A Review
一、目标检测整体模型框架介绍(针对Anchor-based)
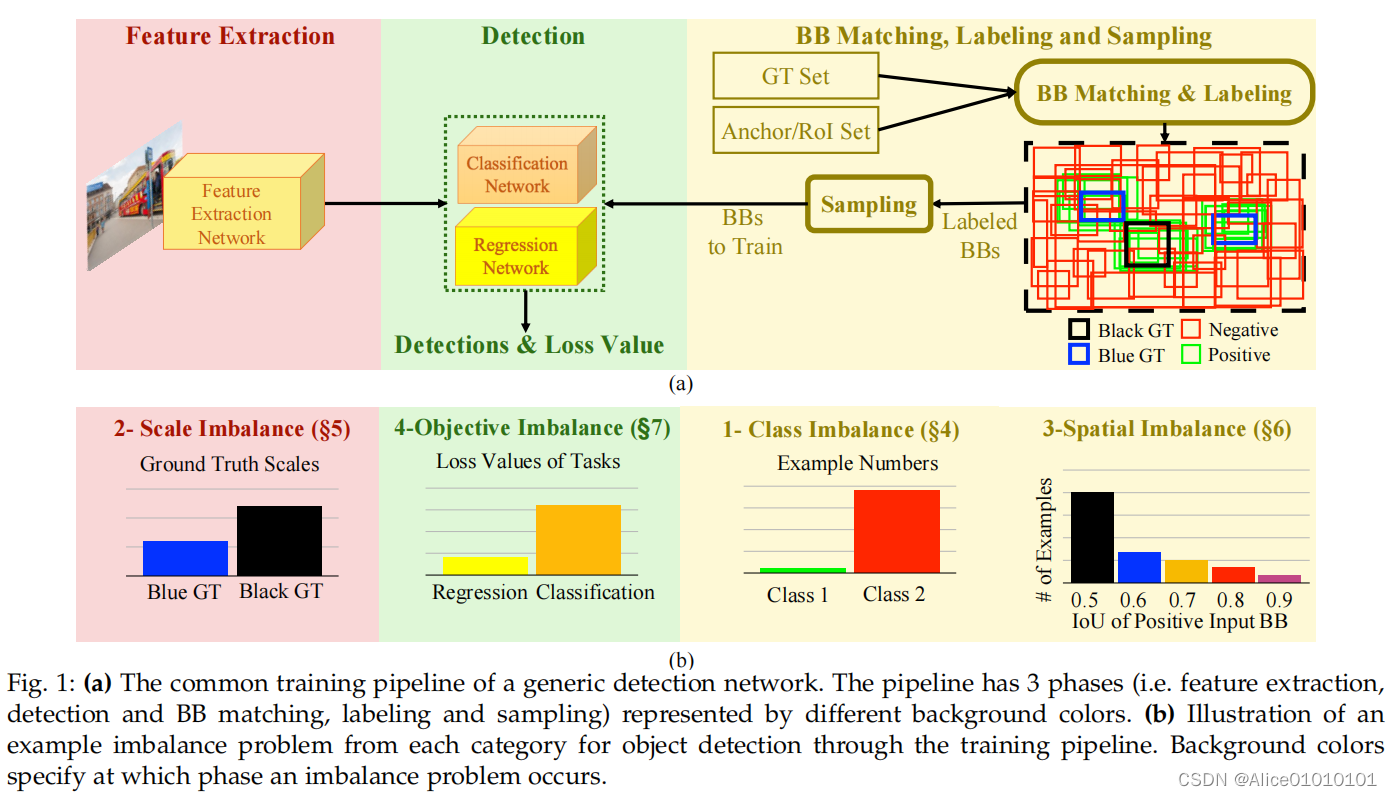
上图为anchor-based的单阶段方法,主要分为三个部分:
- 将输入的图片送入特征提取网络,一般为深度卷积神经网络。
- 产生一个针对目标假设的稠密集合,即Anchors;之后通过将它们和真实值检测框进行匹配和采样(图中蓝色和黑色的groundtruth框,以下简称GT),得到一系列正样本框(绿色框Positive Bounding Boxes,以下简称BB)和负样本框(红色框Negative Bounding Boxes)。
- 最后,带标签的anchors(也即BB)和相对应的特征(即Feature Extraction网络的输出)共同送入分类和回归网络进行训练。
单阶段基于anchor的方法,包括SSD及其变体、YOLO及其变体、以及RetinaNet等,它们直接对anchors和GT进行匹配来输出预测结果。而两阶段的方法,在对输入的图像提取特征之后,还需要经过region proposals进一步缩小采样空间。在上图中,两阶段方法的差异主要表现在Anchor/RoI set之后首先利用其他的网络(例如RPN网络等
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









