







1.随着业务系统的越来越庞大,hbase的表越来越多,分区规则,TLL时间等需要时刻去维护。所以从0到1学会用python爬取hbase信息。
第一步下载hbase:https://mirrors.cnnic.cn/apache/hbase/1.3.3/
第二步解压:tar -zxvf hbase-1.3.3-bin.tar.gz
第三步下载hadoop :http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop-3.0.2/
第四步解压:tar -zxvf hadoop-3.0.2.tar.gz
安装方法多种:一种是跟着教程走,当然我是第二种缺啥补啥(以前安装过hbase)
安装hadoop:
vi etc/hadoop/hadoop-env.sh配置HADOOP_HOME
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.201.b09-2.el7_6.x86_64/jre/
配置 core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
执行:cp mapred-site.xml.template mapred-site.xml指定MR框架的
编辑mapred-site.xml:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
vi hdfs-site.xml编辑:
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
初始化bin目录下执行:sh hadoop namenode -format
cd sbin目录下执行:sh start-dfs.sh输入密码后就安装成功了
hbase配置 编写hbase-site.xml:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:/home/test/hbase_data/hbase</value>
</property>
</configuration>
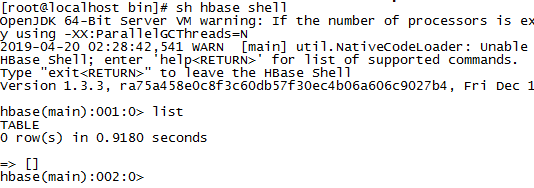
hbase shell 进去
访问UI界面:
1.博主遇到UI界面不能访问的问题,?
我狠心直接禁用防火墙了,本人是在VM中安装的。
[root@localhost bin]# sudo systemctl stop firewalld.service
[root@localhost bin]# sudo systemctl disable firewalld.service

现在真正的开始了,创建一个hbase表设置TTL时间,设置一个版本:
create 'magina_t',{NAME =>'cf',VERSIONS =>1,TTL => 5184000},{SPLITS => ['1','2','3','4','5','6','7','8','9']}
查询表结构

分区开始的值和结束的值:
如果是hbase高版本,hbase shell的命令就可以。
get_splits 'ns1:t1'
p=subprocess.Popen(‘’, shell=True, stdin=subprocess.PIPE,stdout=subprocess.PIPE)
p.stdin.write("echo HELLW_WORLD!\r\n".encode("GBK"))
p.stdin.flush()
低版本用API或者直接页面上爬取,低版本的 hbase python原始爬虫开始操作了(强烈不建议这样做!!!):
class TitleParser(HTMLParser):
def __init__(self):
self.taglevels = []
self.handledtags = ['h2', 'table', 'tr']
self.processing = -1
self.append=-1
self.do=-1
HTMLParser.__init__(self)
def handle_starttag(self, tag, attrs):
if tag =='table':
for a,b in attrs:
if a=='class' and b=='table table-striped':
self.processing=1
break
def handle_data(self, data):
if self.processing == 1:
if data.strip() == 'Name':
print "name"
self.append = 1
if self.append == 1:
self.taglevels.append(data)
def handle_endtag(self, tag):
if tag =='table':
self.append=-1
def handle_charref(self, name):
try:
charnum = int(name)
except ValueError:
return
self.handle_data(chr(charnum))
import urllib
fd = urllib.urlopen("http://xxx.xx:16010/table.jsp?name=magina_t")
tp = TitleParser()
tp.feed(fd.read())
s=[x.strip() for x in tp.taglevels if x.strip()!='' ]















 1737
1737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









