








上一节我们讲解三种简单的排序算法,虽然这3种排序算法的排序结果都是稳定的,但是他们的时间复杂度都是O(n^2),所以这三种算法不是最佳的排序方法,今天我们讲几个时间复杂度低于这三种的排序算法。
1.希尔排序
基本思想:将待排序列划分为若干组,在每一组内进行插入排序,以使整个序列基本有序,然后再对整个序列进行插入排序。
例如:将 n 个数据元素分成d 个子序列:
{ R[1],R[1+d],R[1+2d],…,R[1+kd] }
{ R[2],R[2+d],R[2+2d],…,R[2+kd] }
…
{ R[d],R[2d],R[3d],…,R[kd],R[(k+1)d]}
其中,d 称为增量,它的值在排序过程中从大到小逐渐缩小,直至最后一趟排序减为 1。
从上面的描述,我们知道希尔算法也就一种插入排序,只不过对其进行了优化,减少了查找的烫数。
希尔排序算法代码
#include <stdio.h>
// 打印序列元素
void println(int array[], int len)
{
int i = 0;
for(i=0; i<len; i++)
{
printf("%d ", array[i]);
}
printf("\n");
}
// 交换序列元素
void swap(int array[], int i, int j)
{
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
// 希尔排序算法
void ShellSort(int array[], int len) // O(n*n)
{
int i = 0;
int j = 0;
int k = -1;
int temp = -1; // 定义临时变量,存放插入值
int gap = len; // 定义变量存放增量
// DO循环,直至增量等于1
do
{
// 改变增量值
gap = gap / 3 + 1;
// 顺序选定第i个元素用于插入
for(i=gap; i<len; i+=gap)
{
k = i;
temp = array[k]; // 当前插入值
// 以增量gap遍历序列,与当前插入值比较,
// 如果插入的元素小于当前有序序列的元素,
// 将当前元素后移gap位并且重新标记插入位置
for(j=i-gap; (j>=0) && (array[j]>temp); j-=gap)
{
array[j+gap] = array[j];
k = j;
}
// 比较完毕后将选定的元素插入
array[k] = temp;
}
}while( gap > 1 );
}
int main()
{
int array[] = {21, 25, 49, 25, 16, 8};
int len = sizeof(array) / sizeof(*array);
println(array, len);
ShellSort(array, len);
println(array, len);
return 0;
}
先是将一个长的序列按照增量为gap的分成若干子序列,对子序列进行简单插入排序,然后变更gap的值继续执行上面的操作,当gap值为1时,得出的序列就是排好序的有序序列。特别要注意的是虽然增量序列可以有各种取法,但是应确保增量序列中的值没有除1之外的公因子,并且最后一个增量必须等于1。这就是为什么 有gap = gap / 3 + 1;加一就是确保gap至少为1。至于为什么这里是除以3,我也不得而知,因为到目前为止尚未有人求得最好的增量序列。
快速排序
基本思想:
1.任取待排序序列中的某个数据元素(例如:第一个元素)作为基准,按照该元素的关键字大小将整个序列划分为左右两个子序列:
1.1.左侧子序列中所有元素都小于或等于基准元素;
1.2.右侧子序列中所有元素都大于基准元素;
1.3. 基准元素排在这两个子序列中间。
2.分别对这两个子序列重复施行上述方法,直到所有的对象都排在相应位置上为止。
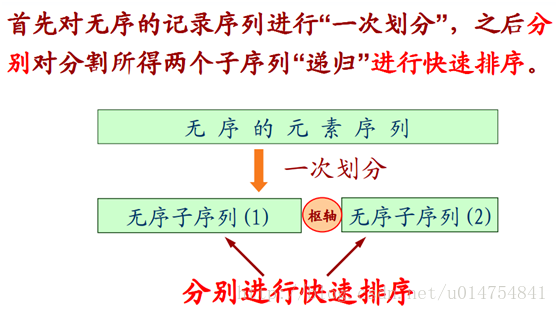
快速排序看上去有点像是冒泡排序,其实,快速排序就是对冒泡排序的一种该进。
假设待排序的序列为{R[s],R[s+1],...,R[t]},首先任意选取一个元素(通常可选第一个元素R[s])作为枢轴(pivot),然后按下述
原则重新排列其余元素:
1.将所有关键字较它小的元素安置在它的位置之前;
2.将所有关键字较它大的元素安置在它的位置之后;
由此可以该“枢轴”记录最后所落的位置i作分界线,将序列{R[s],R[s+1],...,R[t]}分割成两个子序列{R[s],R[s+1],...,R[i-1]}和
{R[i+1],R[i+2],...,R[t]}。这个过程称作一趟快速排序(一次划分)。
一趟快速排序的具体做法:
1.假设两个指针low和high,他们的初值分别为low和high;
2.设枢轴记录的关键字为pv;
3.首先从high所指位置起向前搜索,找到第一个关键字小于pv的元素并与枢轴记录元素调换;
4.然后从low所指位置起向后搜索,找到第一个关键字大于pv的元素并与枢轴记录元素调换;
5.重复3、4两步,直至low=high。
代码如下:
// 划分函数
int partition(int array[], int low, int high)
{
// 保存枢轴元素
int pv = array[low];
// 直至low == high退出循环
while( low < high )
{
// 从high所指位置起向前搜索小于pv的元素并与枢轴记录元素调换
while( (low < high) && (array[high] >= pv) )
{
high--;
}
swap(array, low, high);
// 从low所指位置起向后搜索大于pv的元素并与枢轴记录元素调换
while( (low < high) && (array[low] <= pv) )
{
low++;
}
swap(array, low, high);
}
// 返回枢轴元素位置下标
return low;
}整个快速排序的过程可递归进行。若待排序列中只有一个元素,显然已有序,否则进行一趟快速排序后在分别对划分所得的两个子序列进行快速排序。递归形式的快速算法代码如下:
// 递归快速排序算法
void QSort(int array[], int low, int high)
{
if( low < high )
{
// 获取枢轴元素位置(下标)
int pivot = partition(array, low, high);
// 对划分所得的两个子序列进行快速排序
QSort(array, low, pivot-1);
QSort(array, pivot+1, high);
}
}其他代码:
#include <stdio.h>
// 打印序列
void println(int array[], int len)
{
int i = 0;
for(i=0; i<len; i++)
{
printf("%d ", array[i]);
}
printf("\n");
}
// 交换数据
void swap(int array[], int i, int j)
{
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
void QuickSort(int array[], int len) // O(n*logn)
{
QSort(array, 0, len-1);
}
int main()
{
int array[] = {21, 25, 49, 25, 16, 8};
int len = sizeof(array) / sizeof(*array);
println(array, len);
QuickSort(array, len);
println(array, len);
return 0;
}














 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









