







一、直接在地址栏中输入URL的情况
在中文Windows环境下,本地编码为GB2312:

假如在浏览器地址栏中直接输入以下URL:
http://localhost:8080/servletTest/中国.do?name=中国1、IE浏览器
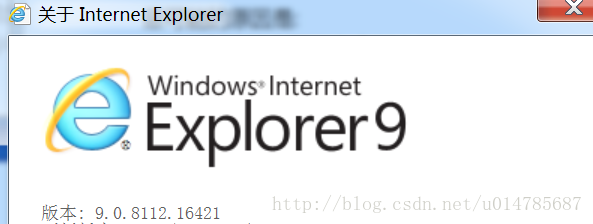
版本:
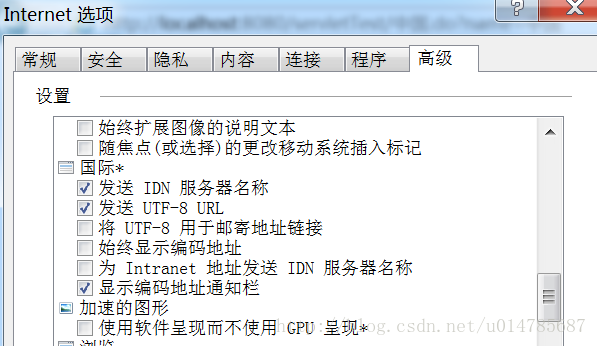
默认情况下,总是以UTF-8发送URL:
这里要用到一个抓包工具Fiddler,安装后启动就行。
打开IE,输入URL:

此时,Fiddler中会抓取到数据:

会发现,pathInfo中的“中国”两个字被编码为:%E4%B8%AD%E5%9B%BD。这个是UTF-8编码。而queryString中的‘中国’两个字是乱码:name=�й�。在Fiddler中切换到十六进制可以看到真实的编码:
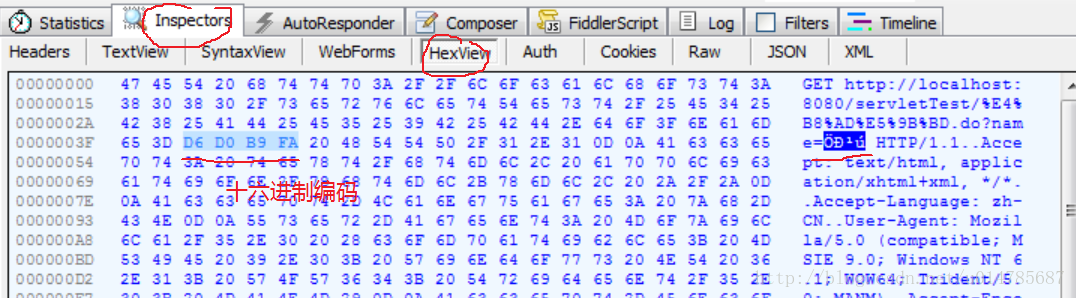
这个十六进制编码D6 D0 B9 FA,就是‘中国’两个字的GB2312编码。
现在将默认修改为不以UTF-8发送:
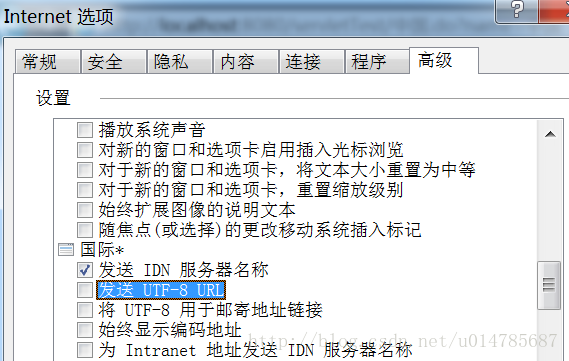
再次在IE的地址栏中输入请求URL:
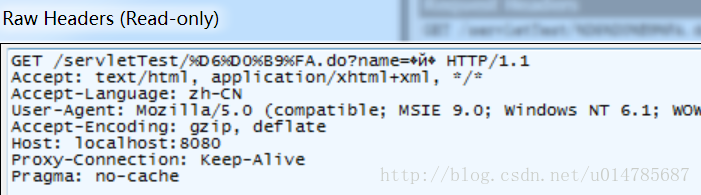
发现pathInfo部分的”中国”两个字的编码是%D6%D0%B9%FA。但是queryString部分依旧是乱码,按照十六进制查看,也是按照GB2312。
小结:IE9 中的编码方式

二、利用FireFox浏览器直接在地址栏输入URL进行访问
浏览器版本:
在默认的情况下,输入URL:
http://localhost:8080/servletTest/中国.do?name=中国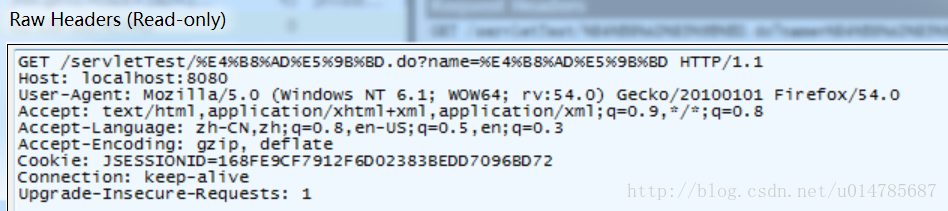
发现URL中pathInfo和queryString中“中国”两个字的编码是:%E4%B8%AD%E5%9B%BD,这是UTF-8编码。
小结:火狐浏览器默认utf-8编码(浏览器版本可能会有差异)

3、Chrome浏览器直接访问URL


发现URL中pathInfo和queryString中“中国”两个字的编码是:%E4%B8%AD%E5%9B%BD,这是UTF-8编码。
小结:Chrome浏览器默认utf-8编码(浏览器版本可能会有差异)
二、根据页面的编码,各种浏览器的URL编码
1、使用Get请求,页面设置为:
<%@ page contentType="text/html;charset=GBK" language="java" %>
<form action="中国.do?contry=中国" method="get" enctype="multipart/form-data">
<table>
<tr>
<td>姓名</td>
<td><input name="name" type="text"></td>
<td>年龄</td>
<td><input name="age" type="text"></td>
</tr>
<tr><input type="submit" value="提交"></tr>
</table>1.1 firefox浏览器(默认设置)

输入以下内容,提交:
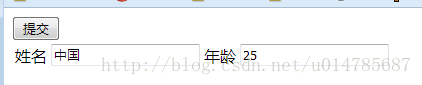
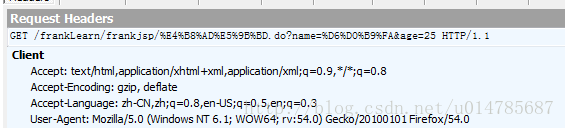
火狐浏览器在页面是GBK编码的情况下,采用GET提交,发现pathInfo部分是UTF-8编码,但是queryString是GBK编码(也就是页面数据部分)。
1.2、将页面编码修改为UTF-8:
<%@ page contentType="text/html;charset=UTF-8" %>重新提交 GET请求:

火狐浏览器在页面是UTF-8编码的情况下,采用GET提交,发现pathInfo部分是UTF-8编码,但是queryString是UTF-8编码(也就是页面数据部分)。
1.3、用Chrome浏览器(默认)
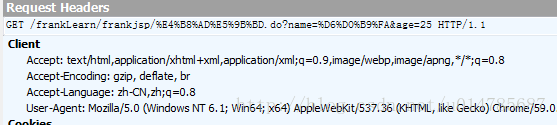
Chrome浏览器在页面是GBK编码的情况下,发现pathInfo部分是UTF-8编码,但是queryString是GBK编码(也就是页面数据部分)。
1.4、采用Chrome浏览器采用PostT提交:

Chrome浏览器在页面是UTF-8编码的情况下,采用GET提交,发现pathInfo部分是UTF-8编码,但是queryString是UTF-8编码(也就是页面数据部分)。
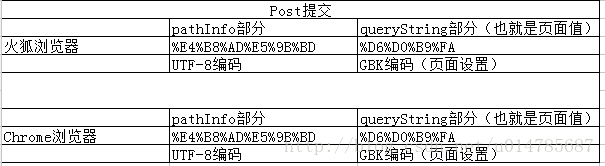
小结:1、页面编码是GBK,提交是GET 的情况下:
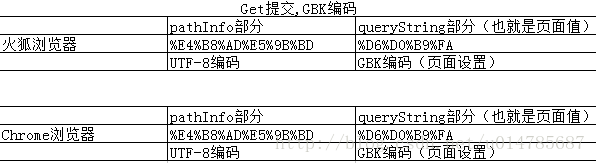
2、页面编码是UTF-8,提交是GET的情况下:

2、采用Post提交,但是页面还是设置GBK:
<%@ page contentType="text/html;charset=GBK" %>
<form action="中国.do?contry=中国" method="post" enctype="multipart/form-data">
<table>
<tr>
<td>姓名</td>
<td><input name="name" type="text"></td>
<td>年龄</td>
<td><input name="age" type="text"></td>
</tr>
<tr><input type="submit" value="提交"></tr>
</table>2.1、火狐浏览器
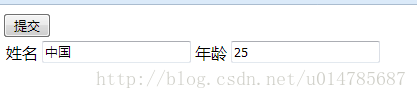

火狐浏览器在页面是GBK编码的情况下,采用POST提交,发现pathInfo部分是UTF-8编码,但是queryString是GBK编码(也就是页面数据部分)。
2.2、修改页面编码格式为UTF-8,:

火狐浏览器在页面是UTF-8编码的情况下,采用POST提交,发现pathInfo部分是UTF-8编码,但是queryString是UTF-8编码(也就是页面数据部分)。
2.3、Chrome浏览器

Chrome浏览器在页面是GBK编码的情况下,采用POST提交,发现pathInfo部分是UTF-8编码,但是queryString是GBK编码(也就是页面数据部分)。
2.4、页面也修改为UTF-8编码:
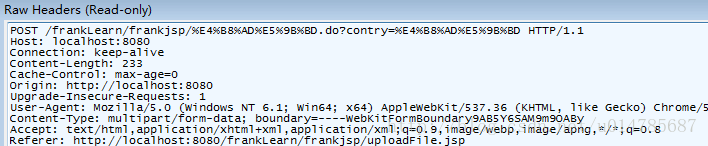
Chrome浏览器在页面是UTF-8编码的情况下,采用POST提交,发现pathInfo部分是UTF-8编码,但是queryString是UTF-8编码(也就是页面数据部分)。
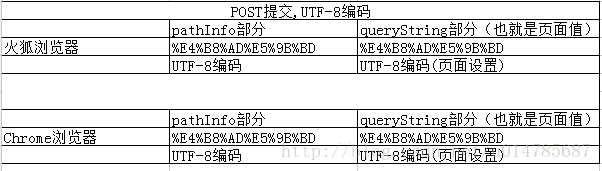
小结:1、页面编码是GBK,提交是POST 的情况下:
2、页面编码是UTF-8,提交是POST 的情况下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









