







 本文介绍了MySQL性能优化的方法,包括数据库设计优化、SQL语句优化、表分割和读写分离技术等。具体涵盖三范式的应用、SQL语句的优化策略、慢查询日志的开启与分析、索引的选择与使用、批量数据插入的最佳实践、GROUP BY优化方法、表分割的策略以及读写分离的实现。
本文介绍了MySQL性能优化的方法,包括数据库设计优化、SQL语句优化、表分割和读写分离技术等。具体涵盖三范式的应用、SQL语句的优化策略、慢查询日志的开启与分析、索引的选择与使用、批量数据插入的最佳实践、GROUP BY优化方法、表分割的策略以及读写分离的实现。
mysql优化
简要:
1、数据库设计优化
2、sql语句优化
3、表分割
4、读写分离技术
一、数据库设计优化
1、表设计要符合三范式,当然,有时也需要适当的逆范式
2、什么是三范式
一范式: 具有原子性,不可再分割
二范式: 在满足一范式的基础上,我们考虑是否满足二范式。只要表的记录满足唯一性,也是说,同一张表,不可能出现完全相同的记录,一般说,在表中设计一个主键即可。
三范式: 在满足二范式的基础上,我们考虑是否满足三范式。只要表满足没冗余性。
二、SQL语句优化
1、sql优化的一般步骤
a、通过show status命令了解各种sql的执行效率
b、定位执行效率较低的sql语句
c、通过explain/desc分析低效率的sql语句的执行情况
d、确定问题并采取相应的优化措施
2、showstatus命令
该命令可以显示mysql数据库当前状态,主要关心的是’com’开头的指令
showstatus like ‘com%’ ó show session status like ‘com%’//显示当前控制台的情况
showglobal status like ‘com%’ //显示数据库从启动到现在的情况
3、showvariables命令
该命令可以查看mysql当前的变量设置,主要关心的是慢查询时间
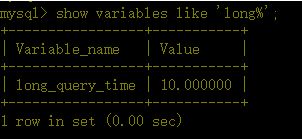
4、如何在mysql中找到慢查询的sql语句
(备注: mysql数据库支持把慢查询语句,记录到日志中给程序员分析;默认情况下,mysql不启用慢查询日志)
步骤: a、启动mysql慢查询
a1、在启动mysql服务时,指定—slow-query-log
a2、在利用客户端登进mysql后,设置变量
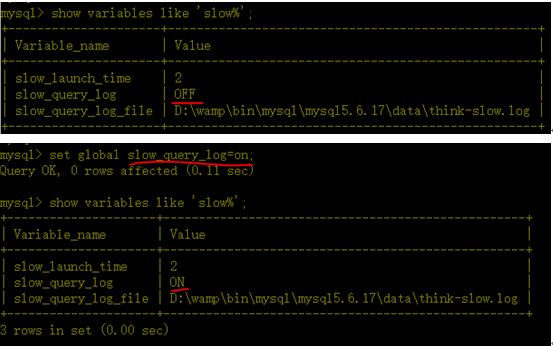
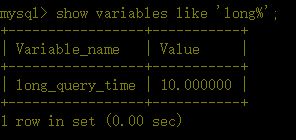
b、查看慢查询时间
c、修改慢查询时间
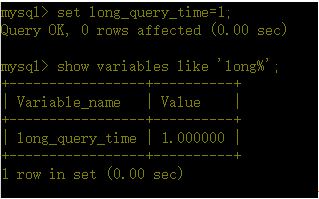
(这个只能在当前环境生效,如果想每次都生效,就修改mysql的配置文件)
d、查看慢查询日志
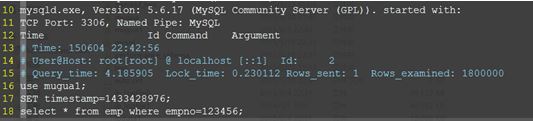
e、根据慢查询的sql语句,进行优化。最廉价的做法就是加索引

f、加上索引后
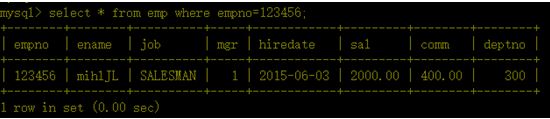
5、索引的影响
a、增加磁盘空间

b、给增删改带来不便
6、哪些列上适合添加索引
a、频繁地作为查询条件字段应该创建索引
b、唯一性太差的字段(即该字段的值变化不大)不适合单独创建索引,即使频繁作为查询条件
c、更新非常频繁的字段不适合创建索引
d、不会出现在where子句中字段也不应该创建索引
7、索引的使用
测试表:
Create Table: CREATE TABLE`t2` (
`id` int(11) NOT NULL DEFAULT '0',
`name` char(5) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULTCHARSET=utf8;
insert into t2(name,age) values('a',2),('aa',3),('b',4),('c',3);
查询要使用索引最重要的条件是查询条件中需要使用索引。
下列几种情况下有可能使用到索引:
a、对于创建的多列索引,只要查询条件使用了最左边的列,索引一般就会被使用。
b、对于使用like的查询,查询如果是 ‘%aaa’不会使用到索引‘aaa%’ 会使用到索引。

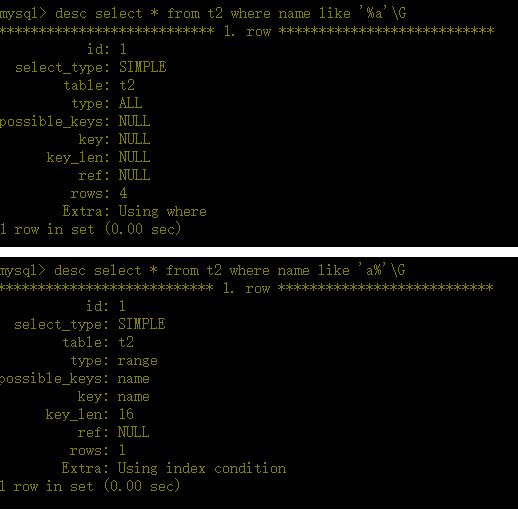
下列的表将不使用索引:
a、如果条件中有or,即使其中有条件带索引也不会使用。
b、对于多列索引,不是使用的第一部分,则不会使用索引。
c、like查询是以%开头
d、如果列类型是字符串,那一定要在条件中将数据使用引号引用起来。否则不使用索引。
e、如果mysql估计使用全表扫描要比使用索引快,则不使用索引。
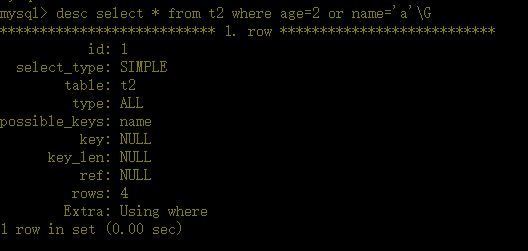
8、验证索引使用情况
showstatus like ‘Handler_read%’;
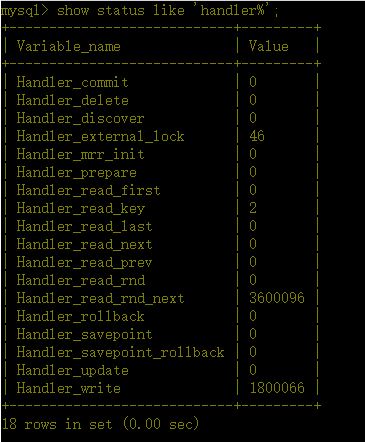
备注:
handler_read_key:这个值越高越好,越高表示使用索引查询到的次数。
handler_read_rnd_next:这个值越高,说明查询低效。
9、常用SQL优化
a、大批量插入数据:
对于MyIsam:
1、alter table table_name disable keys;
2、loading data;
3、alter table table_name enable keys;
对于Innodb:
1、将要导入的数据按照主键排序
2、set unique_checks=0,关闭 唯一性校验
3、set autocommit=0,关闭自动提交
(提示: myisam和innodb的区别是:
a、myisam不支持外接,innodb支持
b、myisam不支持事务,innodb支持)
b、优化group by
默认情况下,mysql对group by后面的列名进行排序。如果查询中包括group by但用户想要避免排序结果的消耗,可以使用order by null禁止排序
三、表分割
当一个表的数据很大的时候,其它的优化方式已经都考虑进去。起到的作用不大时,就要考虑分表了。即把一张大表分割成多张小表。
分表方式:
a、垂直分表
此时,表中存在很多列,这个时候可以通过主键,把表中列分成多张表,然后再根据主键进行关联.(拆分后,每张表的列都不同)
分表前: 个人信息表
| id | name | age | | intro |
| 1 | a | 11 | xxxx | |
| 2 | b | 22 | yyyy | |
|
|
|
|
|
|
分表后: 个人信息表
| id | name | age | |
| 1 | a | 11 | |
| 2 | b | 22 | 22@qq.com |
个人介绍表
| id | intro |
| 1 | xxxx |
| 2 | yyyy |
b、水平分表
可以通过取模的方式,进行分表。因此,需要判断分成几张小表,即模的值为多少。另外,拆分后,每张表的列都是一致的。
分表前: 个人信息表
| id | name | age | | intro |
| 1 | a | 11 | xxxx | |
| 2 | b | 22 | yyyy | |
|
|
|
|
|
|
确定取模的值为2,因此可以把这种表分为两张小表
1、判断id的值,id/2=?
分表后: 个人信息表0
| id | name | age | | intro |
| 1 | a | 11 | xxxx |
个人信息表1
| id | name | age | | intro |
| 2 | b | 22 | yyyy |
四、读写分离
通常来说,一台mysql服务器承载着所有关于数据库的操作。但是在访问量大的时候,mysql服务器很容易出现瓶颈。为了减少mysql服务器的压力,(mysql本身支持主从复制功能)
可以通过分离读写操作。
1、读写分离前示意图

2、读写分离

The quieter you become,the more you are able to hear!















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









