







kafka 常见问题
-
kafka 如何优雅关闭
常用的方式采用jps或者ps ax配合kill -9的方式来快速关闭服务进程。kill -9 是一种强制关闭,不会等待kafka进程合理关闭一些资源以及保存一些运行数据之后再实时关闭。
一般用户希望主动关闭正常运行的服务,我们可以使用kafka自带的kafka-server-stop.sh来关闭
SIGNAL=${SIGNAL:-TERM} PIDS=$(ps ax | grep -i 'kafka\.Kafka' | grep java | grep -v grep | awk '{print $1}') if [ -z "$PIDS" ]; then echo "No kafka server to stop" exit 1 else kill -s $SIGNAL $PIDS fi我们也可以手动获取PID,然后 kill -15 $PID,相当于发送一个关闭的信号,等程序资源释放后,再执行关闭。
-
kafka 分区分配策略

采用了典型的策略模式;Kafka提供了消费者客户端参数partition.assigment.strategy来设定消费者和订阅主题之间的分区分配策略,默认情况下采用的是RangeAssignor。
RangeAssignor是范围分区。
int numPartitionsPerConsumer = numPartitionsForTopic / consumersForTopic.size(); int consumersWithExtraPartition = numPartitionsForTopic % consumersForTopic.size(); List<TopicPartition> partitions = AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic); for (int i = 0, n = consumersForTopic.size(); i < n; i++) { int start = numPartitionsPerConsumer * i + Math.min(i, consumersWithExtraPartition); int length = numPartitionsPerConsumer + (i + 1 > consumersWithExtraPartition ? 0 : 1); assignment.get(consumersForTopic.get(i)).addAll(partitions.subList(start, start + length)); }RoundRobinAssignor是轮询分区,将消费组里的所有消费者和消费者订阅的所有主题分区排序,然后通过轮询的方式依次分配给消费者。
CircularIterator<String> assigner = new CircularIterator<>(Utils.sorted(subscriptions.keySet())); for (TopicPartition partition : allPartitionsSorted(partitionsPerTopic, subscriptions)) { final String topic = partition.topic(); while (!subscriptions.get(assigner.peek()).topics().contains(topic)) assigner.next(); assignment.get(assigner.next()).add(partition); }StickyAssignor主要是为了使分区均匀还尽可能和上次保持一致。
还可以自定义策略,实现AbstractPartitionAssignor这个抽象类。
-
kafka ISR、AR又代表什么?ISR的伸缩又指什么
ISR(In-Sync Replicas) 同步副本列表、OSR(Outof-Sync Replicas)滞后副本、AR(Assigned Replicas)所有副本; AR = ISR + ORS
kafka启动的是时候会开启两个与ISR相关的定时任务,“isr-expiration”和“isr-change-propagation”。
ISR缩减:“isr-expiration”会周期性检测每个分区是否需要缩减ISR集合,当检测到ISR中有失效副本的时候,就会进行缩减ISR的集合。
ISR增加:随着follower不断的进行消息同步,follower的LEO也会不断的往后移动,当追上ISR集合的HW的时候,就会有资格进入ISR集合
-
Kafka中的HW、LEO、LSO、LW等分别代表什么?
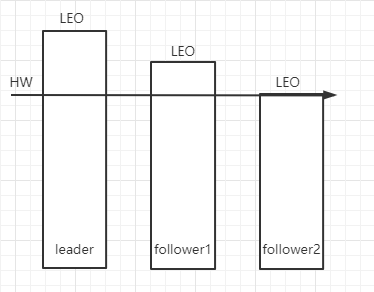
HW:heigh watermark 高水位线 ISR集合中最小的follow的log end offset
LEO:log end offset 每个分区的最后一条消息偏移量 + 1,下一条待写入消息的offset
LSO:log start offest 每个分区的最开始一条消息的偏移量
LW:low watermark 低水位线 表示AR集合中最小的log start offset
-
kafka 为什么不支持主写从读
kafka是生产者写入消息,消费者读取消息都是与leader副本交互的,这是一种主写主读。
延时问题:kafka数据不像redis放在内存,而是在磁盘里面,它需要经过网络->主节点内存->主节点磁盘->网络->从节点内存->从节点磁盘,会比redis更加耗时。
一致性问题:因为主节点到从节点有一定的时间间隔,如果主节点的数据变化,而从节点还没有那么快同步,就很容易导致数据一致性问题。
kafka 采用主写主读,可以简化代码逻辑;直接从主节点拿数据,没有延时影响;能够将负载粒度细化均摊,使负载效果更好。
-
kafka leader选举
分区的副本选举由控制器负责实施。
当创建主题、增加分区、分区中原先的leader下线、分区进行重新分配、某个节点优雅关闭的时候都需要进行leader选举。
从AR集合中找到第一个副本,并且这个副本在ISR集合中,选取改节点作为leader。
-
kafka __consumer_offsets
位移提交的内容会保存在kafka的内存主题 _consumer_offsets中,当集群中第一次有消费者消费消息的时候会自动创建 _consumer_offsets,该主题的分区数默认是50;
在kafkaConsumer中commitSync--> ConsumerCoordinator.sendOffsetCommitRequest会去创建_consumer_offsets的消息数据,具体表现是OffsetCommitRequest.class
// RequestBody 的数据 private final String groupId; private final String memberId; private final int generationId; private final long retentionTime; private final Map<TopicPartition, PartitionData> offsetData;
-
kafka 日志同步机制
通常如果leader不宕机我们就不需要关心follower的情况,如果leader宕机了,我们就需要从follower中选出一个新的leader。日志同步需要保证数据不能重复消费,当客户端已经提交了某条消息,如果现在leader宕机,那么新选出来的leader也需要包含这条消息。但是如果leader消息提交之前要等待很多的follower来消息同步,也会造成性能下降。
“少数服从多数”:如果我们有2n+1个副本,我们必须要确保n+1个副本完成数据同步,并且在不超过n个副本节点失败的情况下,我们可以保证至少有一个节点能够包含已提交的全部信息。“少数服从多数”机制系统的延迟取决于系统最快的几个节点,但是它相对需要的副本数量较多,如果容忍n个副本失败,那么就需要有2n+1个副本。
kafka采用ISR机制,减少所需要的副本数量,减少复制降低了集群的开销。















 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









