






1、简介
OpenTelemetry Collector 旨在提供一个与设备无关的采集器,用于接受,处理和输出观测数据。此外,使用OpenTelemetry Collector也避免了我们运行、维护多个agents/collector,以便支持开源观测数据格式(如Jaeger,Prometheus等)到多个开源或商业后端程序。
OpenTelemetry Collector 有以下几个目标:
-
- 易用性:合理的默认配置,支持主流的协议,运行和采集开箱即用
- 高性能:在不同的负载和配置下,具有高度的稳定性和性能
- 可观测:可观测服务的典范
- 可扩展性:在不改变核心代码的情况下进行定制
- 统一性:单一代码库,既可作为代理又可作为采集器部署,支持trace、metrics和logs
2、架构设计
OpenTelemetry Collector支持几个主流的开源协议,用于接收和发送观测数据,同时也提供了可插拔的架构设计用于支持更多的协议。
Collector采用Pipeline方式来接收、处理和导出数据,每个Collector可配置一个或多个Pipeline,每个pipeline包含如下组件:
- 一组接收数据的Receiver集合
- 一系列的用于从Receiver获取数据并处理的Processor(可选的)
- 一组用于从processor获取数据并输出的Exporter
每个receiver可能会被多个pipeline共用,多个pipeline也可能会包含同一个Exporter。
- pipeline
一个pipeline定义了一条数据流动的路径:从Collector数据接收开始,然后进一步的处理或修改,到最后通过exporter导出。
pipeline能够处理3种类型数据:trace、metric和logs。数据类型是需要pipeline配置的一个属性。在pipeline中receiver、processor和exporter必须支持某个特定的数据类型,否则在配置加载阶段会抛出ErrDataTypeIsNotSupported错误。一个pipeline可以用下图表示:

一个pipeline中可能会有多个receiver,多个receiver接受的数据都会推送到第一个processor中,然后数据会被processor处理,之后会被推送到下一个processor中,直到最后一个processor处理完推送数据到exporter中。每个exporter都会获取到所有的数据副本,最后processor使用一个fanoutconsumer组件将数据输出到多个exproter中。
pipeline在Collector启动时基于配置文件pipeline定义创建。
一个典型的pipeline配置如下:
service:
pipelines: # section that can contain multiple subsections, one per pipeline
traces: # type of the pipeline
receivers: [otlp, jaeger, zipkin]
processors: [memory_limiter, batch]
exporters: [otlp, jaeger, zipkin]
这个例子定义了一个"trace"类型数据的pipeline,包含3个receiver、2个processor和3个exporter
- Receiver
receiver监听某个网络端口并且接收观测数据。通常会配置一个receiver将接收到的数据传送到一个pipeline中,当然也可能是同一个receiver将将接收到的数据传送到多个pipeline中。示例配置如下:
receivers:
otlp:
protocols:
grpc:
endpoint: localhost:4317
service:
pipelines:
traces: # a pipeline of “traces” type
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [jaeger]
traces/2: # another pipeline of “traces” type
receivers: [otlp]
processors: [batch]
exporters: [opencensus]
在上面的配置中,otlp这个receiver将会把接收到的数据同时发送到traces和traces/2两个pipeline中。
当Collector加载完配置之后,会生成如下的处理流(为了简化,省略了后面的processor和exporter)

当Collector中存在多个pipeline复用一个receiver时,Collector只会创建一个receiver实例,这个实例会把数据发送到多个pipeline的第一个processor中。从receiver到输出到消费者再到processor的数据传播是通过一个同步函数调用完成的。这也意味着,如果一个processor阻塞调用,那么附属于这个receiver上的其他processor也将被阻塞,无法接收到数据,而receiver本身也会停止处理和转发新收到的数据。
- exporter
exporter通常将收到数据发送到某个网络上地址。允许一个pipeline中配置多个同类型的exporter,例如如下示例配置了2个otlp类型的exporter以发送数据到不同OTLP端点:
exporters:
otlp/1:
endpoint: example.com:4317
otlp/2:
endpoint: localhost:14317
通常情况下一个exporter从一个pipeline中获取数据,但是也可能是多个pipeline发送数据到同一个exporter:
exporters:
jaeger:
protocols:
grpc:
endpoint: localhost:14250
service:
pipelines:
traces: # a pipeline of “traces” type
receivers: [zipkin]
processors: [memory_limiter]
exporters: [jaeger]
traces/2: # another pipeline of “traces” type
receivers: [otlp]
processors: [batch]
exporters: [jaeger]
在上面的实例中,jaeger这个exporter将接受来自pipeline traces和pipeline traces/2 的数据。当Collector加载完配置后,会生成如下的处理流:

Processors
一个pipeline可以包含多个串联的processor。第一个processor接受来自一个或多个recevier的数据,最后一个processor将处理完的数据发送到一个或多个exporter中。第一个和最后一个之间的所有processor严格地只从前面的一个processor接收数据,并严格地只向后面的processor发送数据。
processor能够在转发数据之前对其进行转换(例如增加或删除spans中的属性),也可以丢弃数据(例如probabilisticsampler processor所做的处理),processor也可以生成新数据。例如spanmetrics processor基于span数据生成metrics。
同一个processor可以被多个pipeline引用,在这种场景下,每个processor使用相同的配置,但每个pipeline都会初始化一个自己的processor实例。这些processor实例都有自己的状态,在不同的pipeline之间不共享。如下示例,batch processor被pipeline traces和pipeline traces/2 引用,但每个pipeline都维护了一个自己的实例:
processors:
batch:
send_batch_size: 10000
timeout: 10s
service:
pipelines:
traces: # a pipeline of “traces” type
receivers: [zipkin]
processors: [batch]
exporters: [jaeger]
traces/2: # another pipeline of “traces” type
receivers: [otlp]
processors: [batch]
exporters: [otlp]
当Collector加载完配置后,生成的处理流如下:
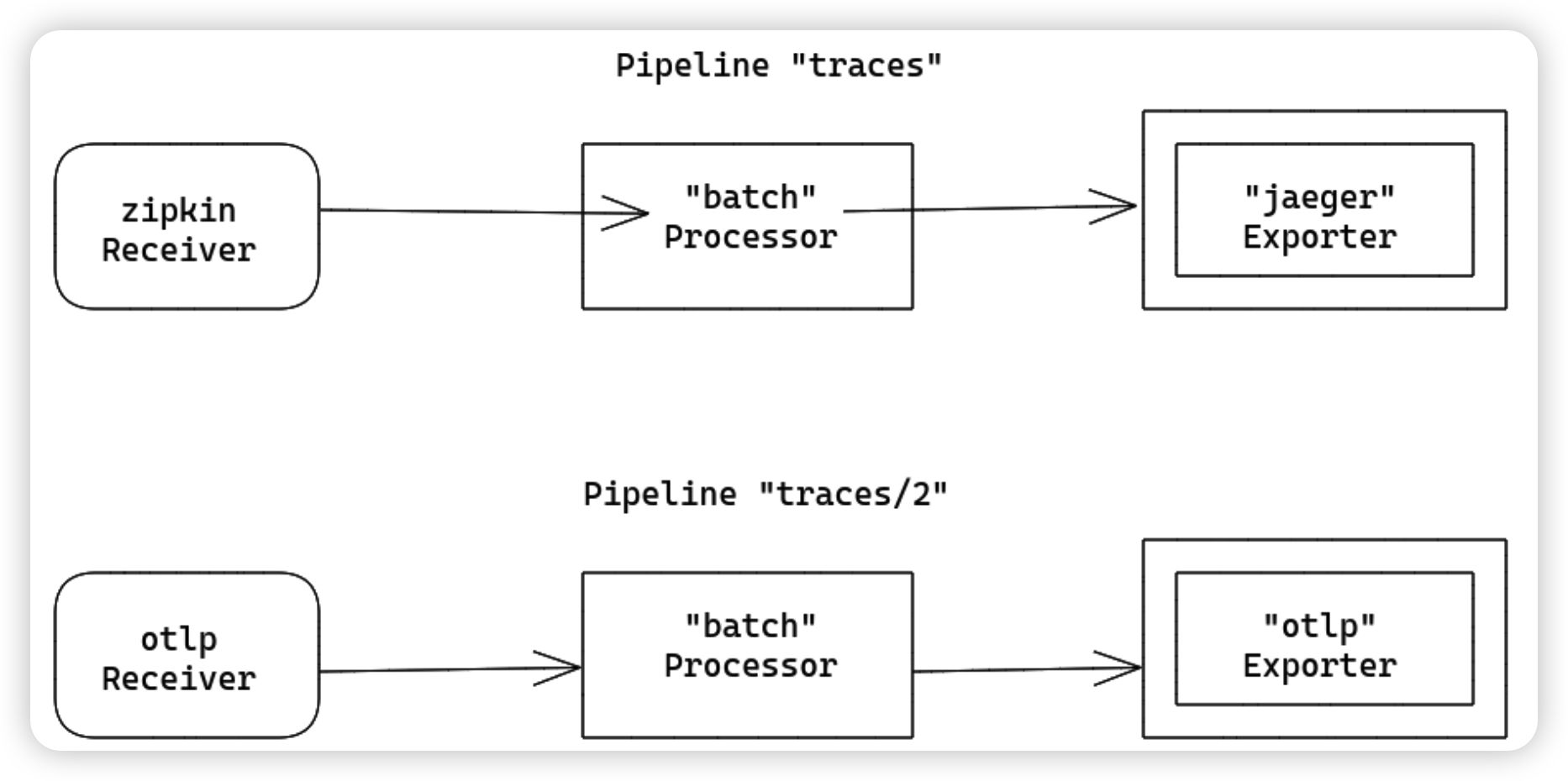
注意,同一个名称的processor不能被一个pipeline引用多次。
Collector既可以作为代理agent运行,也可以作为gateway运行,不同身份运行,其处理逻辑也不同。
- 作为代理运行
在一个典型的VM或容器环境下,用户的应用以进程或pod形式运行,这些应用引用了OpenTelemetry的观测库。在以往的做法中,这些OpenTelemetry库会记录、采集、采样和聚合trace/metric/log数据,并且通过exporter导出到持久化存储组件中,或是在本地的页面上展示。这种模式有一些缺点,例如:
- 对于每一种OpenTelemetry Library,exporter/zpages功能需要用原生语言(java、go等)实现一遍
- 在一些编程语言中(如Ruby、PHP),统计聚合的功能实现难度较大
- 为了能够导出OpenTelemetry spans/stats/metrics数据,用户需要手动添加exporter库并重新部署应用。当用户应用刚好存在故障需要观测时,这种操作很难被接受。
- 用户需要承担配置和初始化exporter的任务,这很容易出错,并且用户可能不愿意OpenTelemetry侵入他们的代码
为了解决上述问题,你可以运行OpenTelemetry Collector作为一个代理agent。代理agent作为一个后台进程运行,并且与库无关。当部署完成,代理agent能够接收traces/metrics/logs 数据,并将数据转发到后端程序。我们也可以让代理agent有能力将配置(例如采样率)下发给应用数据采集Library。同时对于没有聚合到数据,我们也可以让代理agent做一些数据聚合的处理。
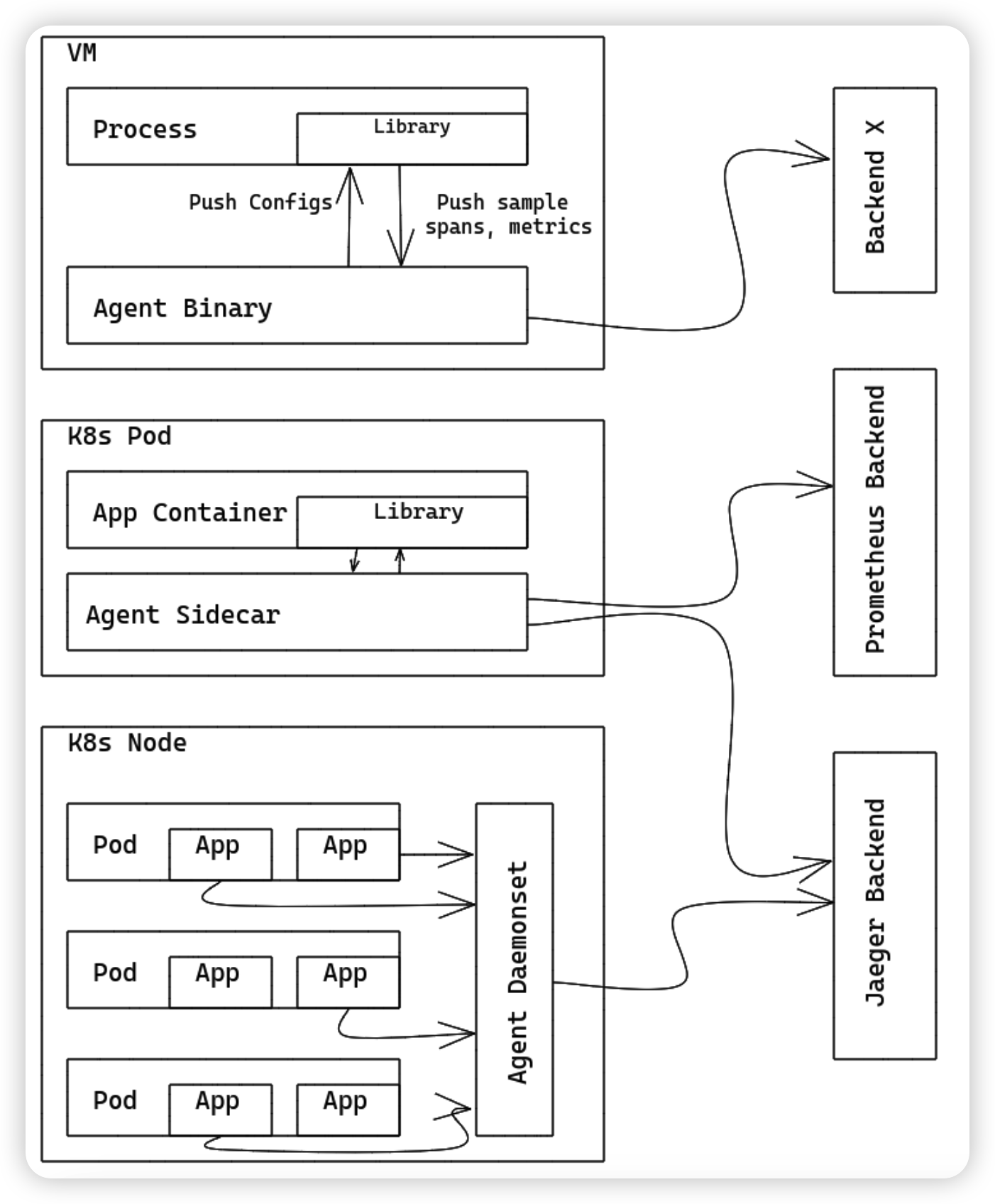
对于其他数据采集Library的开发者/维护者来说,代理agent也可以接收来自其他 追踪/监控 librarie的traces/metrics/logs数据,例如Zipkin, Prometheus等。通过添加特定的receiver即可实现。
- 作为Gateway运行
OpenTelemetry Collector作为Gateway实例运行时,可以接收来自一个/多个Agent或数据采集Libraries导出的span和metrics数据,或者是接收由其他agent发出的符合支持协议的数据。Collector需要配置将数据发送到指定的exporter。如下描述了作为Gateway时的部署架构:
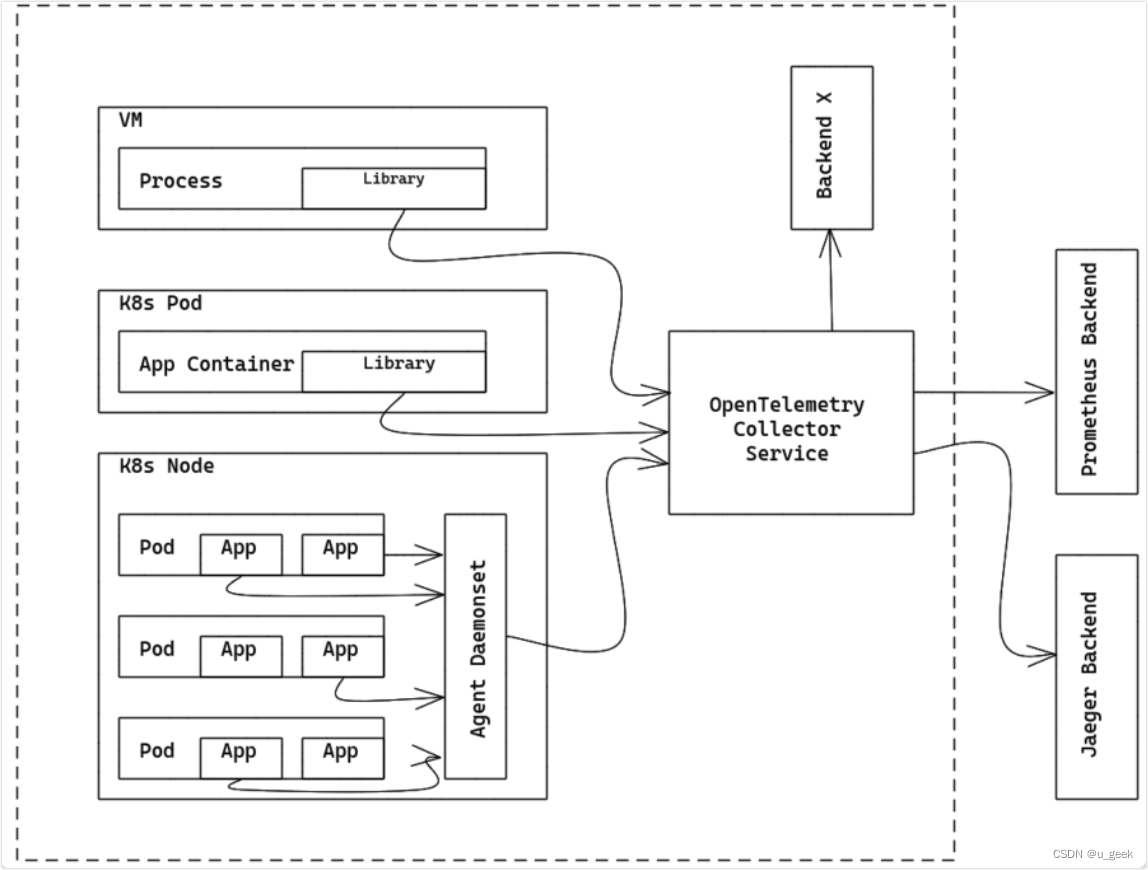
OpenTelemetry收集器也可以使用其他配置部署,例如以其receiver支持的格式之一接收来自其他agent或客户端的数据。
原文链接:1、opentelemetry-collector/design.md at main · open-telemetry/opentelemetry-collector · GitHub














 1874
1874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









