






介绍:
设计内存池的目标是为了保证服务器长时间高效的运行,通过对申请空间小而申请频繁的对象进行有效管理,减少内存碎片的产生,合理分配管理用户内存,从而减少系统中出现有效空间足够,而无法分配大块连续内存的情况。
目标:
此次设计内存池的基本目标,需要满足线程安全性(多线程),适量的内存泄露越界检查,运行效率不太低于malloc/free方式,实现对4-128字节范围内的内存空间申请的内存池管理(非单一固定大小对象管理的内存池)。
内存池技术设计与实现
本内存池的设计方法主要参考SGI的alloc的设计方案,为了适合一般的应用,并在alloc的基础上做一些简单的修改。
Mempool的内存池设计方案如下(也可参考候捷《深入剖析STL》)
从系统申请大块heap内存,在此内存上划分不同大小的区块,并把具有相同大小的区块连接起来,组成一个链表。比如A大小的块,组成链表L,当申请A大小时,直接从链表L头部(如果不为空)上取到一块交给申请者,当释放A大小的块时,直接挂接到L的头部。内存池的原理比较简单,但是在具体实现过程中大量的细节需要注意。
1:字节对齐。
为了方便内存池中对象的管理,需要对申请内存空间的进行调整,在Mempool中,字节对齐的大小为最接近8倍数的字节数。比如,用户申请5个字节,Mempool首先会把它调整为8字节。比如申请22字节,会调整为24,对比关系如下
| 序号 | 对齐字节 | 范围 |
| 0 | 8 | 1-8 |
| 1 | 16 | 9-16 |
| 2 | 24 | 17-24 |
| 3 | 32 | 25-32 |
| 4 | 40 | 33-40 |
| 5 | 48 | 41-48 |
| 6 | 56 | 49-56 |
| 7 | 64 | 57-64 |
| 8 | 72 | 65-72 |
| 9 | 80 | 73-80 |
| 10 | 88 | 81-88 |
| 11 | 96 | 89-96 |
| 12 | 104 | 97-104 |
| 13 | 112 | 105-112 |
| 14 | 120 | 113-120 |
| 15 | 128 | 121-128 |
(图1)
对于超过128字节的申请,直接调用malloc函数申请内存空间。这里设计的内存池并不是对所有的对象进行内存管理,只是对申请内存空间小,而申请频繁的对象进行管理,对于超过128字节的对象申请,不予考虑。这个需要与实际项目结合,并不是固定不变的。实现对齐操作的函数如下
static size_t round_up(size_t size)
{
return (((size)+7) &~ 7);// 按8字节对齐
}
2:构建索引表
内存池中管理的对象都是固定大小,现在要管理0-128字节的范围内的对象申请空间,除了采用上面提到的字节对齐外,还需要变通一下,这就是建立索引表,做法如下;
static _obj* free_list[16];
创建一个包含16个_obj*指针的数组,关于_obj结构后面详细讲解。free_list[0]记录所有空闲空间为8字节的链表的首地址;free_list[1]对应16字节的链表,free_list[2]对应24字节的列表。free_list中的下标和字节链表对应关系参考图1中的“序号”和“对齐字节”之间的关系。这种关系,我们很容易用算法计算出来。如下
static size_t freelist_index(size_t size)
{
return (((size)+7)/7-1);// 按8字节对齐
}
所以,这样当用户申请空间A时,我们只是通过上面简单的转换,就可以跳转到包含A字节大小的空闲链表上,如下;
_obj** p = free_list[freelist_index(A)];
3:构建空闲链表
通过索引表,我们知道mempool中维持着16条空闲链表,这些空闲链表中管理的空闲对象大小分别为8,16,24,32,40…128。这些空闲链表链接起来的方式完全相同。一般情况下我们构建单链表时需要创建如下的一个结构体。
struct Obj
{
Obj *next;
Char* p;
Int iSize;
}
next指针指向下一个这样的结构,p指向真正可用空间,iSize用于只是可用空间的大小,在其他的一些内存池实现中,还有更复杂的结构体,比如还包括记录此结构体的上级结构体的指针,结构体中当前使用空间的变量等,当用户申请空间时,把此结构体添加的用户申请空间中去,比如用户申请12字节的空间,可以这样做
Obj *p = (Obj*)malloc(12+sizeof(Obj));
p->next = NULL;
p->p = (char*)p+sizeof(Obj);
p->iSize = 12;
但是,我们并没有采用这种方式,这种方式的一个缺点就是,用户申请小空间时,内存池加料太多了。比如用户申请12字节时,而真实情况是内存池向内存申请了12+ sizeof(Obj)=12+12=24字节的内存空间,这样浪费大量内存用在标记内存空间上去,并且也没有体现索引表的优势。Mempool采用的是union方式
union Obj
{
Obj *next;
char client_data[1];
}
这里除了把上面的struct修改为union,并把int iSize去掉,同时把char*p,修改为char client_data[1],并没有做太多的修改。而优势也恰恰体现在这里。如果采用struct方式,我们需要维护两条链表,一条链表是,已分配内存空间链表,另一条是未分配(空闲)空间链表。而我们使用索引表和union结构体,只需要维护一条链表,即未分配空间链表。具体如下
索引表的作用有两条1:如上所说,维护16条空闲链表2:变相记录每条链表上空间的大小,比如下标为3的索引表内维持着是大小为24字节的空闲链表。这样我们通过索引表减少在结构体内记录p所指向空间大小的iSize变量。从而减少4个字节。
Union的特性是,结构内的变量是互斥存在的。再运行状态下,只是存在一种变量类型。所以在这里sizeof(Obj)的大小为4,难道这里我们也需要把这4字节也加到用户申请空间中去嘛?其实不是,如果这样,我们又抹杀了union的特性。
当我们构建空闲分配链表时,我们通过next指向下一个union结构体,这样我们不使用p指针。当把这个结构体分配出去时,我们直接返回client_data的地址,此时client_data正好指向申请空间的首字节。所以这样,我们就不用在用户申请空间上添加任何东西。
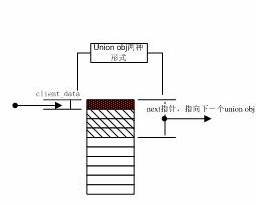
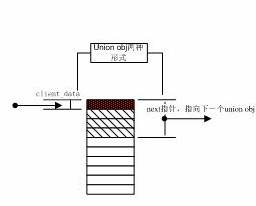
图2
Obj的连接方式如上所示,这样我们无需为用户申请空间添加任何内容。
4:记录申请空间字节数
如果采用面向对象方式,或者我们在释放内存池的空间时能够明确知道释放空间的大小,无需采用这种方式。
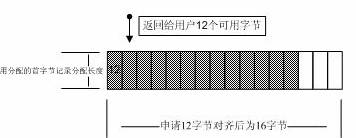
图3
在C语言中的free没有传递释放空间大小,而可以正确释放,在这里也是模仿这种方式,采用这种记录申请空间大小的方式去释放内存。用户申请空间+1操作将在字节对齐之前执行,找到合适空间后,把首字节改写为申请空间的大小,当然1个字节最多纪录256个数,如果项目需要,可以设置为short类型或者int类型,不过这样就需要占用用户比较大的空间。当释放内存空间时,首先读取这个字节,获取空间大小,进行释放。为了便于对大于128字节对象的大小进行合适的释放,同时也对大于128字节的内存申请,添加1字节记录大小。所以现在这里限制了用户内存申请空间不得大于255字节,不过现在已经满足项目要求。当然也可以修改为用short类型记录申请空间的大小。
// 申请
*(( unsigned char *)result) = (size_t)n;
unsigned char * pTemp = (unsigned char*)result;
++pTemp;
result = (_obj*)pTemp;
return result;
// 释放
unsigned char * pTemp = (unsigned char *)ptr;
--pTemp;
ptr = (void*)pTemp;
n = (size_t)(*( unsigned char *)ptr);
5:内存池的分配原理
在内存池的设计中,有两个重要的操作过程1:chunk_alloc,申请大块内存,2:refill回填操作,内存池初始化化时并不是为索引表中的每一项都创建空闲分配链表,这个过程会推迟到,只有用户提取请求时才会创建这样的分配链表。详细参考如下代码(在sgi中stl_alloc.h文件中你也可以看到这两个函数),主要步骤在注释中已经说明。
/**
* @bri: 申请大块内存,并返回size*(*nobjs)大小的内存块
* @param: size,round_up对齐后的大小,nobjs
* @return: 返回指向第一个对象内存指针
*/
static char* chunk_alloc(size_t size, int *nobjs)
{
/**< 返回指针 */
char* __result;
/**< 申请内存块大小 */
size_t __total_bytes = size *(*nobjs);
/**< 当前内存可用空间 */
size_t __bytes_left = _end_free - _start_free;
/**< 内存池中还有大片可用内存 */
if (__bytes_left >= __total_bytes)
{
__result = _start_free;
_start_free += __total_bytes;
return (__result);
}
/**< 至少还有一个对象大小的内存空间 */
else if (__bytes_left >= size)
{
*nobjs = (int)(__bytes_left/size);
__total_bytes = size * (*nobjs);
__result = _start_free;
_start_free += __total_bytes;
return (__result);
}
/**< 内存池中没有任何空间 */
else
{
/**< 重新申请内存池的大小 */
size_t __bytes_to_get = 2 * __total_bytes + round_up(_heap_size >> 4);
/**< 把内存中剩余的空间添加到freelist中 */
if(__bytes_left > 0)
{
_obj *VOLATILE* __my_free_list =
_free_list + freelist_index(__bytes_left);
((_obj*)_start_free)->free_list_link =
*__my_free_list;
*__my_free_list = (_obj*)_start_free;
}
// 申请新的大块空间
_start_free = (char*)malloc(__bytes_to_get);
/*=======================================================================*/
memset(_start_free,0,__bytes_to_get);
/*=======================================================================*/
// 系统内存已经无可用内存,那么从内存池中压缩内存
if(0 == _start_free)
{
size_t __i;
_obj *VOLATILE* __my_free_list;
_obj *__p;
/**< 从freelist中逐项检查可用空间(此时只收集比size对象大的内存空间) */
for (__i = size; __i <= (size_t)__MAX_BYTES; __i += __ALIGN)
{
__my_free_list = _free_list + freelist_index(__i);
__p = *__my_free_list;
/**< 找到空闲块 */
if (__p != 0)
{
*__my_free_list = __p->free_list_link;
_start_free = (char*)__p;
_end_free = _start_free + __i;
return (chunk_alloc(size,nobjs));
}
}
_end_free = 0;
/**< 再次申请内存,可能触发一个异常 */
_start_free = (char*)malloc(__bytes_to_get);
}
/**< 记录当前内存池的容量 */
_heap_size += __bytes_to_get;
_end_free = _start_free + __bytes_to_get;
return (chunk_alloc(size,nobjs));
}
}
/*=======================================================================*/
/**
* @bri: 填充freelist的连接,默认填充20个
* @param: __n,填充对象的大小,8字节对齐后的value
* @return: 空闲
*/
static void* refill(size_t n)
{
int __nobjs = 20;
char* __chunk = (char*)chunk_alloc(n, &__nobjs);
_obj *VOLATILE* __my_free_list;
_obj *VOLATILE* __my_free_list1;
_obj * __result;
_obj * __current_obj;
_obj * __next_obj;
int __i;
// 如果内存池中仅有一个对象
if (1 == __nobjs)
return(__chunk);
__my_free_list = _free_list + freelist_index(n);
/* Build free list in chunk */
__result = (_obj*)__chunk;
*__my_free_list = __next_obj = (_obj*)(__chunk + n);
__my_free_list1 = _free_list + freelist_index(n);
for (__i = 1;; ++__i)
{
__current_obj = __next_obj;
__next_obj = (_obj*)((char*)__next_obj+n);
if(__nobjs - 1 == __i)
{
__current_obj->free_list_link = 0;
break;
}else{
__current_obj->free_list_link = __next_obj;
}
}
return(__result);
}
经过上面操作后,内存池可能会成为如下的一种状态。从图上我们可以看到,已经构建了8,24,88,128字节的空闲分配链表,而其他没有分配空闲分配链表的他们的指针都指向NULL。我们通过判断索引表中的指针是否为NULL,知道是否已经构建空闲分配表或者空闲分配表是否用完,如果此处指针为NULL,我们调用refill函数,重新申请20个这样大小的内存空间,并把他们连接起来。在refill函数内,我们要查看大内存中是否有可用内存,如果有,并且大小合适,就返回给refill函数。
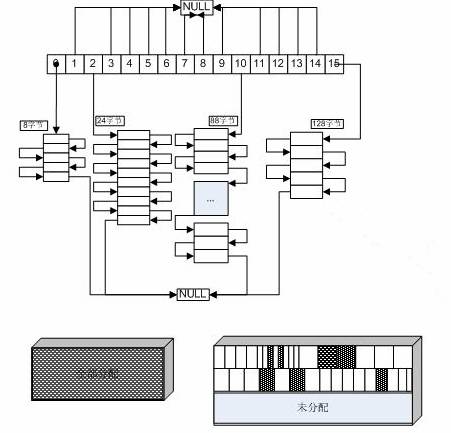
图4
6:线程安全
采用互斥体,保证线程安全。
内存池测试
内存池的测试主要分两部分测试1:单线程下malloc与mempool的分配速度对比2:多线程下malloc和mempool的分配速度对比,我们分为4,10,16个线程进行测试了。
测试环境:操作系统:windows2003+sp1,VC7.1+sp1,硬件环境:intel(R) Celeron(R) CPU 2.53GHz,512M物理内存。
申请内存空间设定如下
#define ALLOCNUMBER0 4
#define ALLOCNUMBER1 7
#define ALLOCNUMBER2 23
#define ALLOCNUMBER3 56
#define ALLOCNUMBER4 10
#define ALLOCNUMBER5 60
#define ALLOCNUMBER6 5
#define ALLOCNUMBER7 80
#define ALLOCNUMBER8 9
#define ALLOCNUMBER9 100
Malloc方式和mempool方式均使用如上数据进行内存空间的申请和释放。申请过程,每次循环申请释放上述数据20次
我们对malloc和mempool,分别进行了如下申请次数的测试(单位为万)
| 2 | 10 | 20 | 30 | 40 | 50 | 80 | 100 | 150 | 200 |
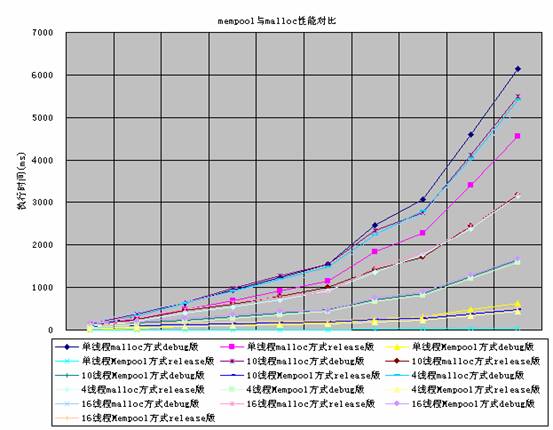
图5
可以看到mempool无论在多线程还是在单线程情况下,mempool的速度都优于malloc方式的直接分配。
Malloc方式debug模式下,在不同的线程下,运行时间如下,通过图片可知,malloc方式,在debug模式下,申请空间的速度和多线程的关系不大。多线程方式,要略快于单线程的运行实现。
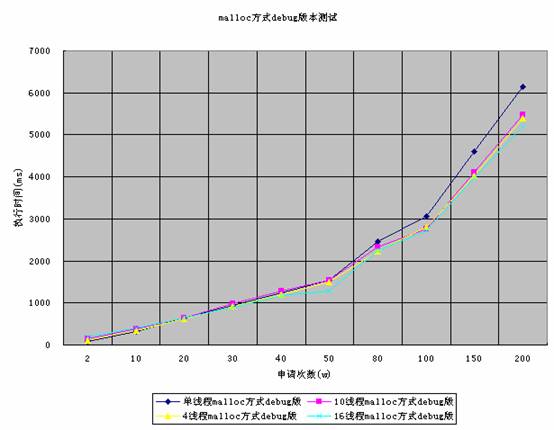
图6
Malloc方式release模式测试结果如下。
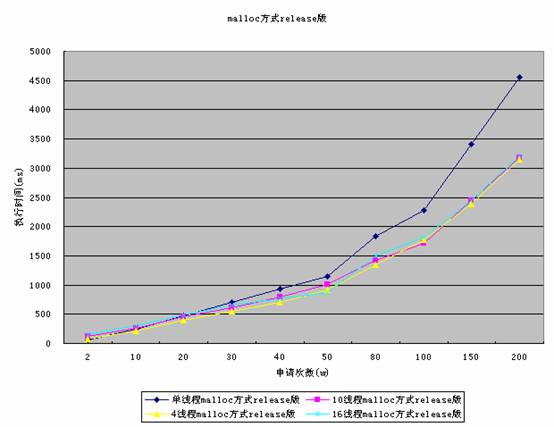
图7
多线程的优势,逐渐体现出来。当执行200w次申请和释放时,多线程要比单线程快1500ms左右,而4,10,16个线程之间的差别并不是特别大。不过整体感觉4个线程的运行时间要稍微高于10,16个线程的情况下,意味着进程中线程越多用在线程切换上的时间就越多。
下面是mempool在debug测试结果
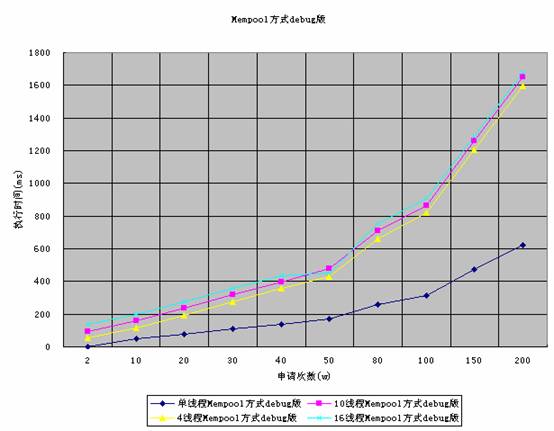
图8
下面是mempool在release模式下的测试结果
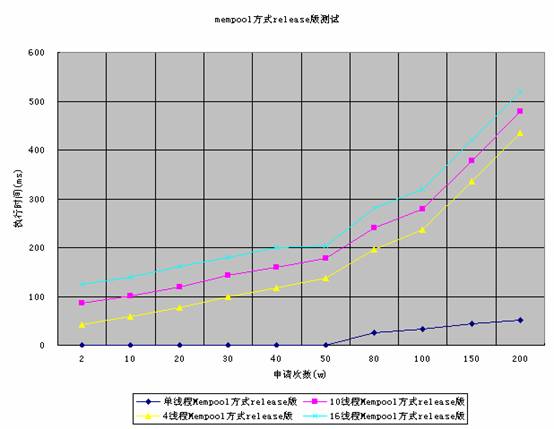
图9
以上所有统计图中所用到的数据,是我们测试三次后平均值。
通过上面的测试,可以知道mempool的性能基本上超过直接malloc方式,在200w次申请和释放的情况下,单线程release版情况下,mempool比直接malloc快110倍。而在4个线程情况下,mempool要比直接malloc快7倍左右。以上测试只是申请速度的测试,在不同的压力情况下,测试结果可能会不同,测试结果也不能说明mempool方式比malloc方式稳定。
小结:内存池基本上满足初期设计目标,但是她并不是完美的,有缺陷,比如,不能申请大于256字节的内存空间,无内存越界检查,无内存自动回缩功能等。只是这些对我们的影响还不是那么重要。
由于这是一个公司项目,代码涉及版权,所以不能发布出来。如果你想做自己的内存池,可以与我联系ugg_xchj#hotmail.com.















 3384
3384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









