







 本文介绍了KMP字符串匹配算法,该算法通过预处理模式串来提高在文本中寻找匹配的效率。文章讨论了有限自动机的概念,如何构建模式串的匹配有限自动机,并阐述了状态转移函数Tr的计算,以及预处理过程中的时间复杂度问题。KMP算法在预处理后能在线性时间内找到匹配结果,且预处理时间更优。
本文介绍了KMP字符串匹配算法,该算法通过预处理模式串来提高在文本中寻找匹配的效率。文章讨论了有限自动机的概念,如何构建模式串的匹配有限自动机,并阐述了状态转移函数Tr的计算,以及预处理过程中的时间复杂度问题。KMP算法在预处理后能在线性时间内找到匹配结果,且预处理时间更优。
KMP字符串匹配算法(一)—模式匹配
KMP是一种通过对“模式串P”进行预处理之后,利用预处理信息来在“文本T”中寻找匹配的算法,这里的“模式串P”和“文本T”可以是任何意义下的可进行”相等“比较的元素集。通常情况下|P|远远小于|T|。
有限自动机
之所以要提到有限自动机,是因为KMP算法与其有很大的共通之处。为在匹配过程中避免不必要的比较,他们都做了针对模式串的预处理。而且我觉得自动机里的理论能辅助对KMP算法的理解。
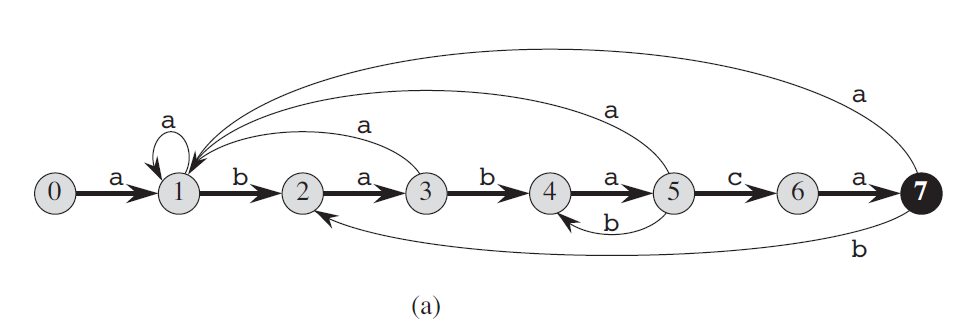
如图(a)所示的有限自动机,如果我们的字母表 ∑={ a,b,c} ,则它可以接收(识别)所有以ababaca结尾的字符串,例如你输入字符串cbbabccababaca,则其对应的状态转换为:
begin c->0b->0b->0a->1b->2c->0c->0a->1b->2a->3b->4a->5c->6a->7end, 能到达终止状态表示输入的串能被接受。
来自有限自动机的启发
在进行字符串的模式匹配的时候,我们需要在一个大的文本T中寻找一个模式字符串P。
我们能不能根据已知的字母表 ∑ 和一个模式串预先一次性的构造一个有限状态自动机,使得算法在扫描文本的每个字符的时候都能查到一个对应的转移状态,当扫描到一个文本字符T[i]时,若状态能转换到end,我们就说文本T包含模式字符串P。所谓包含P是指算法最后扫描的|P|个字符和P是一样的。否则称文本T不包含P,也就是T中没有子串能够匹配P。
有关字符串的助记符
- ∑∗ 表示包含所有由字母表 ∑ 中的字母构成的有限长度的字符串的集合。
- |X| 表示字符串的 X 长度。
XY 表示字符串 X 和字符串Y 的一个连接。- W⊂X 表示 W 是
X 的前缀。 W⊃X 表示 W 是X 的后缀。- Pi 表示字符串 P 的长度为i的前缀。
T[i] 表示字符串 T 的第i 个字符。- LCS(P,T)=max{ k∣Pk⊃T} ,表示字符串 P 的前缀和字符串
T 的后缀相等的集合中长度最长的一个串的长度,叫做 T 相对于P 的后缀函数。
有限自动机的定义
一个有限自动机M是一个5元组 (Q,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 476
476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









