









文章目录
前言
这几天复习数据结构,在看《大话数据结构》,作者:程杰,出版社:清华大学出版社(这里要感谢我的室友Hertter把这本书借给我看,附上他博客的链接:Hertter的博客,哈哈哈哈),前两章主要介绍了数据结构、数据结构和算法的关联,我想通过这篇博客回顾一下我看到的数据结构和算法。
本文代码是用C语言写的,图片皆截取自《大话数据结构》里的图片。
数据结构和算法
程序设计 = 数据结构 + 算法。
怎么去理解这句话呢,为什么都说学好数据结构和算法很重要呢,下面说说我的理解:
作为程序员,我们经常和数据打交道,数据的类型各种各样,但不外乎1.数形;2.字符型。我们想要高效地处理数据,就得从数据的结构入手。把问题量化之后的要处理的数据分类,把具有相同结构的分成一类(这也就是为什么会有基本数据类型),这样处理同一类数据的时候就可以使用相同、相似的方法了,数据处理起来也是大为方便。
上面一段话概括起来:把数据分为不同类型的结构(也就是数据结构)存放在计算机里,方便我们高效地操作这些数据(也就是算法)。
方便地存,也为了方便地取,举个例子:蓝桥杯:特别数的和里,“特别的数”就是一些具有相同结构的数据:它们都可以用数据结构int表示(数据结构)、数中都含有2||0||1||9,那么我们把1-10000里的“特别的数”找出来(算法),再相加,就得到我们想要的结果了,这就是数据结构和算法之间的关系,数据结构的处理离不开算法,特定算法的执行又离不开相同的数据结构。
1.数据结构
我所知道的数据结构有:线性表(Linked List,又名链表)、堆(Heap)、栈(Stack)、队列(Queue)、图(Graph)、树(Tree),通过百度搜索:常用的数据结构,还能知道有数组(Array)、散列表(Hash,即哈希表)、串(String,也叫字符串)、整数(Integer)(备注:int的全称为Integer,在JAVA里int是基本数据类型默认值为0,而integer是为int提供的封装类默认值为null,是不同的,大家不必在这里要用int还是Integer而纠结,这里用英文全称的目的是拓展单词量,以至于面试问到时不至于语塞,平时还能装13用哈哈哈)、布尔(Boolean)、浮点数(Float)(原来常用的数据类型也是数据结构的一种)。
上面一段话是以前我对数据结构的理解(可以说我的理解很局限,只知道很少的一部分数据结构,却不知道数据结构的本质)。
数据结构的定义:数据结构是相互之间存在一种或多种特定关系的数据元素的集合。通过这句话,我们也就不难明白为什么数组(Array)、串(String)、布尔(Boolean)、整数(Integer)、浮点型(Float)这些也是数据结构的一种,因为这些都是一种或多种特定关系的数据元素的集合(比如int a;a的数值大小不会超过int的范围,也不会是像3.14、true、'abc’这些值)。
1.1数据结构的类型
从不同视点来看,数据结构也有不同的分类,可以分为逻辑结构(是指数据对象中数据元素之间的相互关系)和物理结构(是指数据的逻辑结构在计算机中的存储形式)。
逻辑结构包括:
1.集合结构
集合结构(集合结构中的数据元素除了同属于一个集合外,数据元素之间没有其他任何关系,如整数Integer、布尔Boolean):
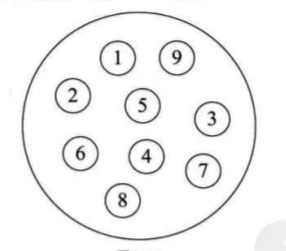
2.线性结构
线性结构(线性结构中的数据元素之间是一对一的关系,如链表Linked List、数组Array,因为线性表的顺序存储结构就是用数组存放的,每个结点都有唯一的前驱和唯一的后继,符合一一对应的关系):
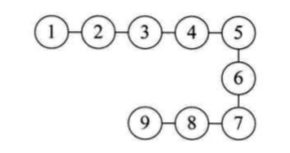
3.树形结构
树形结构(树形结构中的数据元素之间是一对多的关系,如树Tree):
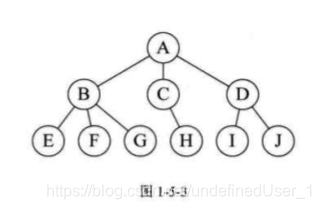
4.图形结构
图形结构(图形结构中的数据元素之间是多对多的关系,如图Graph):
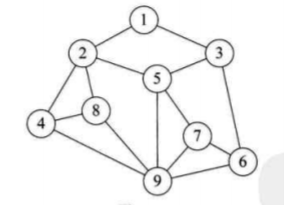
物理结构包括:
1.顺序存储结构
顺序存储结构是把数据元素存放的4在地址连续的存储单元里,其数据间的逻辑关系和物理关系是一致的。(即知道每个数据所占存储单元的大小c,LOC表示获得存储位置的函数,那么顺序存储结构中第 i 个数据元素和第 1个、第i+1个、第i-1个数据元素的位置关系为:
![]()
![]()
![]()
)下图为一个线性表的顺序存储结构示意图
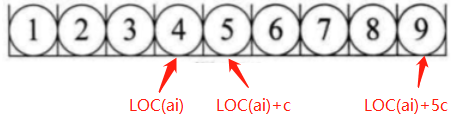
2.链接存储结构
顺序存储结构是把数据元素存放在任意存储单元,这组存储单元可以是连续的,也可以是不连续的。
2.算法
以前我只在学习计算机组成原理时知道KMP算法是一种算法,至于什么是算法就不知道了,其实递归、动态规划、排序(冒泡排序、快速排序等)这些也是算法,那么算法究竟是啥呢?
其实算法是用来处理数据结构的,通过前面的描述我们知道虽然数据结构有很多种,但是同一种数据结构里的数据元素是相类似的,具有某些相同的特质,如何利用这些特质高效地处理同一种数据结构里的数据元素,也就成了算法(有时候就是简单的找规律,比如显示斐波那契数列,斐波那契数列的规律是从第二项开始每一项都等于前两项之和,利用好这个规律就可以很简单地做到用最少的代码、执行最少的次数显示斐波那契数列,这里给出一种算法关键代码:c=${a}; a=${b}; b=$((${c}+${b}));,这种算法也叫动态规划,这里推荐一篇讲“如何理解动态规划”的知乎提问,里面名叫:牛岱的知乎作者阐述了什么是动态算法,并用爬楼梯为例子,其实就是斐波那契数列的实例,帮助理解什么是动态规划。知乎:如何理解动态规划?)。
我们举一个例子:老师要求你写一个求1+2+······+100的程序,来看看有哪些算法可以解决这个求和问题。
1.有的人:
int sum = 1+2+3+4+5+6+······+100;
printf("%d",sum);
2.也有的人:
int i = 1 ,sum = 0;
for(i ;i <= 100;i++)
{
sum = sum + i;
}
printf("%d",sum);
3.熟悉数学的人:
//公差为1的等差数列求和
int a1 =1 ,n = 100,d = 1;//i为等差数列首项,n为等差数列末项,d为公差
int sum = n*a1 + n*(n-1)*d/2;//等差数列求和公式
printf("%d",sum);
4.而最聪明的人(数学家高斯的方法):
//本质是另一种等差数列求和公式,用倒序相加法,(首项+末项)×项数/2
int sum = 0,n = 100;
sum = (1 + n) * n / 2;
printf("%d",sum);
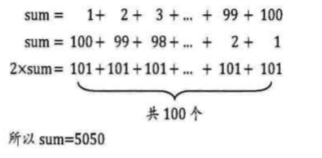
这四个算法相比而言第3、第4条是最简洁、可读性最好、占用内存最少、用时最短的。我们说针对1+2+······+100的求和问题,第3、第4条是最好的算法。
算法的定义:算法是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每一条指令表示一个或多个操作。通过这句话,我们能知道算法即方法,同一个问题,可以有很多种解决问题的方法,但并不是每个方法都是最好的方法。
好的算法应该满足1.正确。2.可读性好。3.健壮(面对输入数据不合法时算法也能有相关的处理而不是产生异常或莫名其妙的结果)。4.时间效率高和存储量低
有了时间效率高和存储量低这一标准,衍生出了判断算法效率的标准:比较算法的时间复杂度和空间复杂度。其中推导时间复杂度的方法有:推导大O阶方法,由于我们在写程序时完全可以用空间来换取时间,当然也有用时间来换取空间的,要根据具体情况做调整,一般来说我们所讲的复杂度指的是时间复杂度,空间复杂度咱们就不做重点讲。
2.1推导大O阶方法
推导大O阶:
1.用常数1取代运行时间中的所有加法常数。
2.在修改后的运行次数函数中,只保留最高阶。
3.如果最高阶项存在且不是1,则除去与这个项相乘的常数。
得到的结果就是大O阶。
常见的时间复杂度所耗费时间从小到大依次是:
| 常数阶 | 对数阶 | 线性阶 | nlogn阶 | 平方阶 | 立方阶 | 指数阶 | 阶乘阶 | n的n次方阶 |
|---|---|---|---|---|---|---|---|---|
| O(1) | O(logn) | O(n) | O(nlogn) | O(n^2) | O(n^3) | O(2^n) | O(n!) | O(n^n) |
对于立方阶O(n3)及后面的大O阶在现实中很少会遇到,一般我们不去讨论它们。
常数阶O(1)和线性阶O(n)
以上面计算1+2+······+100为例子,计算每个算法的时间复杂度,不过在这之前我们把100改成n,这样得出来的结果才是真正的时间复杂度:
算法1:
int i;//执行一次
int sum = 1+2+3+4+5+6+······+n;//执行1+1+1+1+1+···+1次,n个1相加,虽然只是一行代码,但是要执行的次数不是1次而是n次
printf("%d",sum);//执行一次
算法1的总执行次数为1+n+1,算法4后会讲到为什么是1+n+1而不是1+1+1,根据推导大O阶方法:
1.用常数1取代运行时间中的所有加法常数,结果为n+1。
2.只保留最高阶,结果为n,所以最终的得出这个算法的时间复杂度为O(n)。
另外,这个算法的可行性很差,我们在给sum赋值时需要从1加到100、1000、1000、一亿,这个赋值的时间可比程序运行时间多得多得多得多。
算法2:
int i = 1 ,sum = 0;//执行一次
//把循环看作一个整体,循环体内的代码执行多少次就是循环体的时间复杂度
for(i ;i <= n;i++)//循环体内代码执行了n次
{
sum = sum + i;
}
printf("%d",sum);//执行一次
算法2的总执行次数为:1+n+1,根据推导大O阶方法:
1.用常数1取代运行时间中的所有加法常数,结果为n+1。
2.只保留最高阶,结果为n,所以最终的得出这个算法的时间复杂度为O(n)。
算法3:
int a1 = 1 ,n ,d = 1;//执行一次
int sum = n*a1 + n*(n-1)*d/2;//执行一次
printf("%d",sum);//执行一次
算法3的总执行次数为:1+1+1,根据推导大O阶方法:
1.用常数1取代运行时间中的所有加法常数,结果为1。
2.只保留最高阶,这里没有最高阶,所以最终的得出这个算法的时间复杂度为O(1)。
算法4:
//本质是另一种等差数列求和公式,倒序相加法,(首项+末项)×项数/2
int sum = 0,n;//执行一次
sum = (1 + n) * n / 2;//执行一次
printf("%d",sum);//执行一次
算法4跟算法3类似,时间复杂度也为O(1)。
为什么算法1时间复杂度为O(n)而不是O(1)呢?
我们先来看看算法2、3为什么时间复杂度为O(1)而不是O(3)、O(100):
算法3、4都很类似,不管n有多大,只要n在int的范围内,得到的结果sum也在int范围内,如算法3中:1001 + 100(100-1)1/2 和 10001 + 1000*(1000-1)*1/2、算法4中:(1 + 100) * 100 / 2 和 (1 + 10000) * 10000/ 2 得出结果sum的时间是非常接近的,几乎可以忽略不记,像这样跟n的大小无关的,执行时间恒定的算法,我们称之为具有O(1)的时间复杂度,又叫常数阶。
在算法3中的int sum = n*a1 + n*(n-1)*d/2;其实可以看做先算na1(得到结果为a)、再算n-1(得到结果为c)、再算nc(得到结果为D)、再算D* d(得到结果为e)、再算 n*(n-1)*d/2(得到结果为b)、最后算a + b,结果是1+1+1+1+1+1=6次,根据推导大O阶方法,1+1+1+1+1+1其实就是1,所以这就是为什么算法3、4是1+1+1,时间复杂度为O(1),而算法1是1+n+1,时间复杂度为O(n)。
上面的例子介绍了常数阶O(1)和线性阶O(n),接下来介绍对数阶O(logn)和平方阶O(n2)
对数阶O( logn):
以二分法查找(也叫折半查找)为例查找元素n(假设n的数值再1到100之间)的
float low = 1,heigh = 100;
float mid = (low+heigh)/2;
//n>=50的情况,误差在0.01内
while(n >= mid && n-mid<0.001 || mid-n<0.001 )
{
low= (low+heigh)/2;
mid = (low+heigh)/2;
}
//n<50的情况
while(n < mid && n-mid<0.001 || mid-n<0.001 )
{
high= (low+heigh)/2;
mid = (low+heigh)/2;
}
printf("%d",mid);
两个while循环执行执行其中一个,因为n不可能又大于等于50又小于50,不存在这种情况,我们去其中一个while循环做分析,每当(low+heigh)/2,mid就距离n更近一分。也就是说执行的次数x为:2的x次方 = n,即x = log2n。所以时间复杂度为O( log2n),我们说像这样形似logn的(如log2n、log4n、log33n)时间复杂度为对数阶;
平方阶O( n2):
对于嵌套循环的算法,先算内层循环的执行次数,再算外层循环的次数,两个循环次数相乘,就是整个嵌套循环的执行次数如:
int i,j;
for(i=1;i<=n,i++)
{
for(j=1;j<=n,j++)
{
//时间复杂度为O(1)的程序步骤序列
}
}
内层循环for(j=1;j<=n,j++)执行次数为n,外层for(i=1;i<=n,i++)执行次数也为n,整个嵌套循环体的执行次数为n*n=n的2次方,所以时间复杂度为O(n2),即平方阶。
以上就是《大话数据结构》前两章的主要内容和我自己的一些理解,快2020年了,祝自己身体健康学业有成爱情美满,祝大家心想事成顺顺利利出入平安,哈哈哈哈哈。
The past, is everything we were don’t make us who we are.














 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









