







从零实现BP神经网络:原理与Python实战
BP(Back Propagation)神经网络是最基础的人工神经网络模型之一,广泛应用于分类、回归等机器学习任务。
当神经网络遇见XOR:一场数学与代码的浪漫邂逅
想象一下,你正在教一个小朋友学习"异或"(XOR)这个逻辑运算:
- 0 XOR 0 = 0
- 0 XOR 1 = 1
- 1 XOR 0 = 1
- 1 XOR 1 = 0
看起来很简单对吧?但有趣的是,这个看似简单的运算却难倒了早期的单层感知机。就像小朋友第一次遇到"为什么1+1=0"时的困惑表情一样,传统的线性模型在这里完全失灵了!
这就是我们的BP神经网络大显身手的时候了!它就像是一个拥有"多层思考能力"的超级小朋友,能够通过不断试错和调整,最终掌握这个"反常识"的规律。
神经网络的"乐高积木":拆解我们的代码实现
1. 初始化:给神经网络"分配大脑"
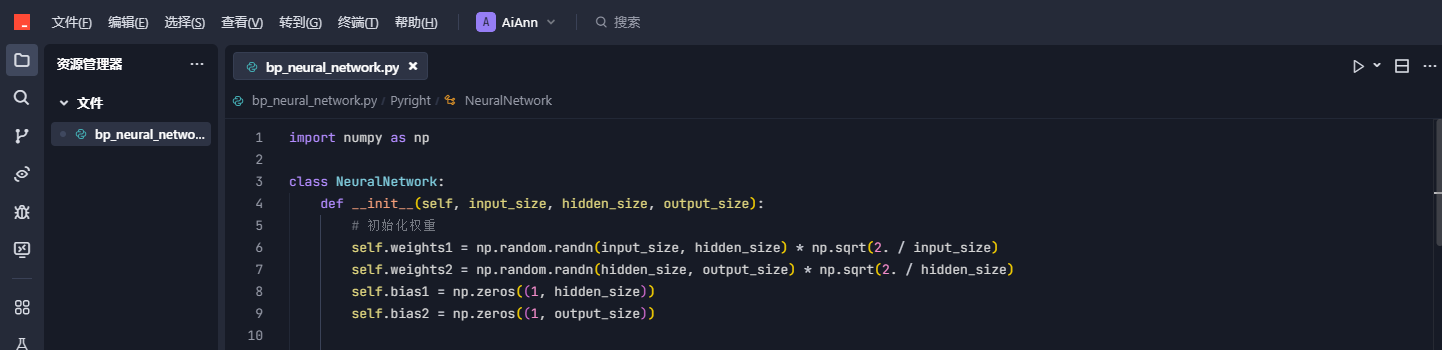
这就像建造一个"数字大脑"的框架:
- weights 是神经元之间的连接强度,用Xavier方法初始化保证不胖不瘦刚刚好
- bias 给每个神经元添加个性,就像有人天生乐观有人悲观
- velocity 是动量优化用的,类似滑雪时保持的运动惯性
2. 激活函数:神经元的"思考方式"

# S型曲线:将任意值压缩到0-1之间
# 导数计算:反向传播的关键
这两个函数决定了神经元如何"思考":
- sigmoid 像压扁弹簧,把无限范围的数字压缩到0-1之间
- sigmoid_derivative 计算变化率,就像知道弹簧当前被压扁的程度
3. 前向传播:信息流动的"高速公路"

这就像玩传话游戏:
- 输入层听到问题(X)
- 小声告诉隐藏层(经过weights1和bias1调整)
- 隐藏层用sigmoid"思考"后告诉输出层
- 输出层给出最终答案
4. 反向传播:神经网络的"学习算法"
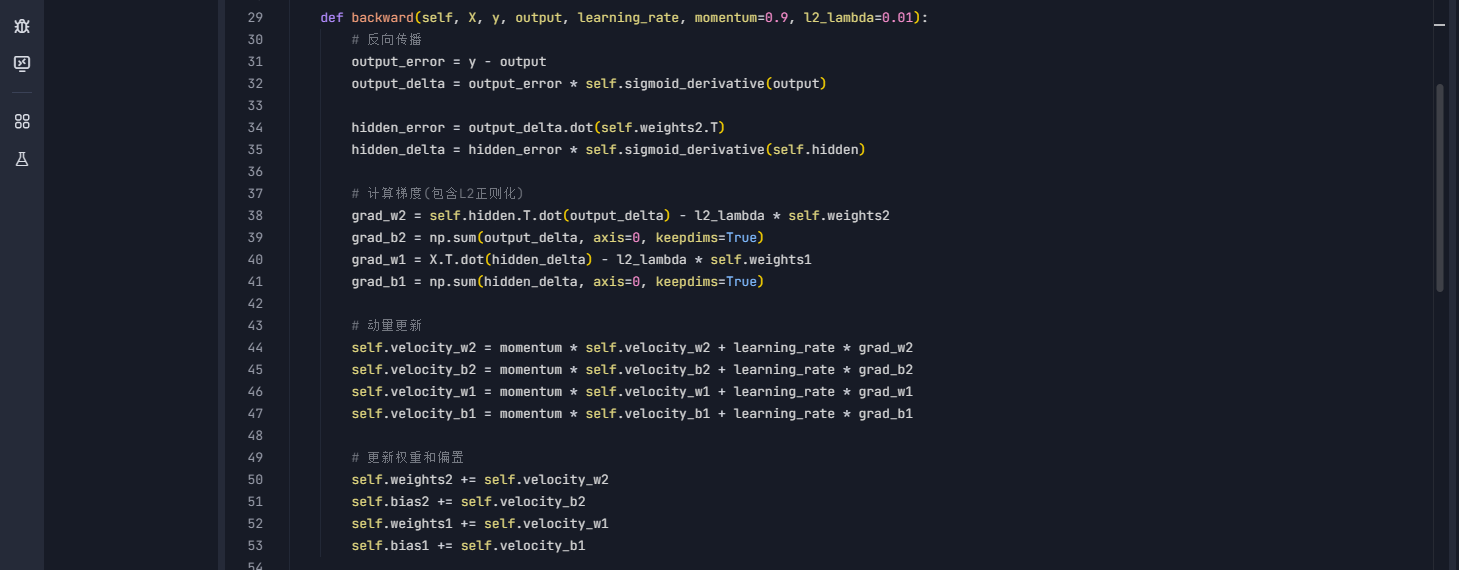
这是神经网络的"学习时刻":
- 先看最终答案错在哪(output_error)
- 再分析是哪个中间环节出问题(hidden_error)
- 最后像老师批改作业一样调整每个神经元的"发言权重"
- 动量更新让调整过程像滑雪下坡一样顺滑
5. 训练过程:学习计划表
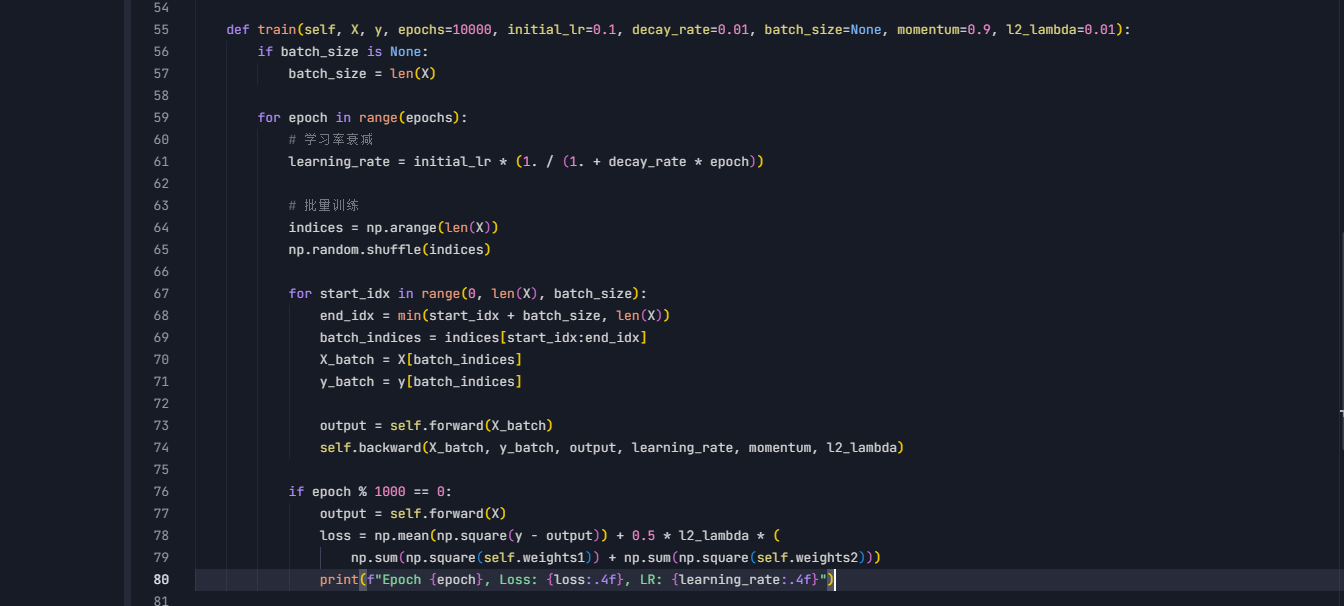
这制定了学习计划:
- epochs 是总学习次数,像复习20000遍课本
- learning_rate 会逐渐变小,开始大范围搜索,后期精细调整
- batch_size 控制每次学多少样本,像小班教学效果更好
6. 实战测试:XOR问题
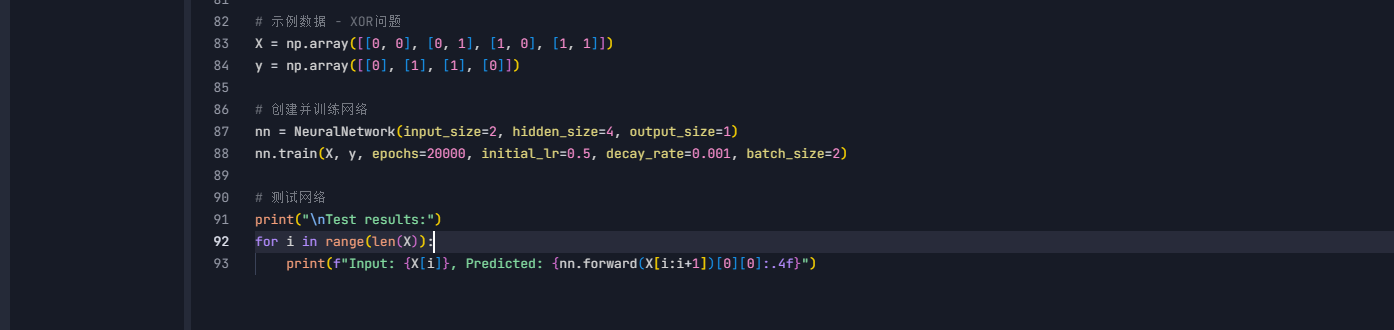
我们用经典的XOR问题测试:
- 输入 [0,1] 应该输出 1
- 输入 [1,1] 应该输出 0
- 经过训练后,神经网络会像小朋友一样最终理解这个"反常识"规律
7.最终运行结果
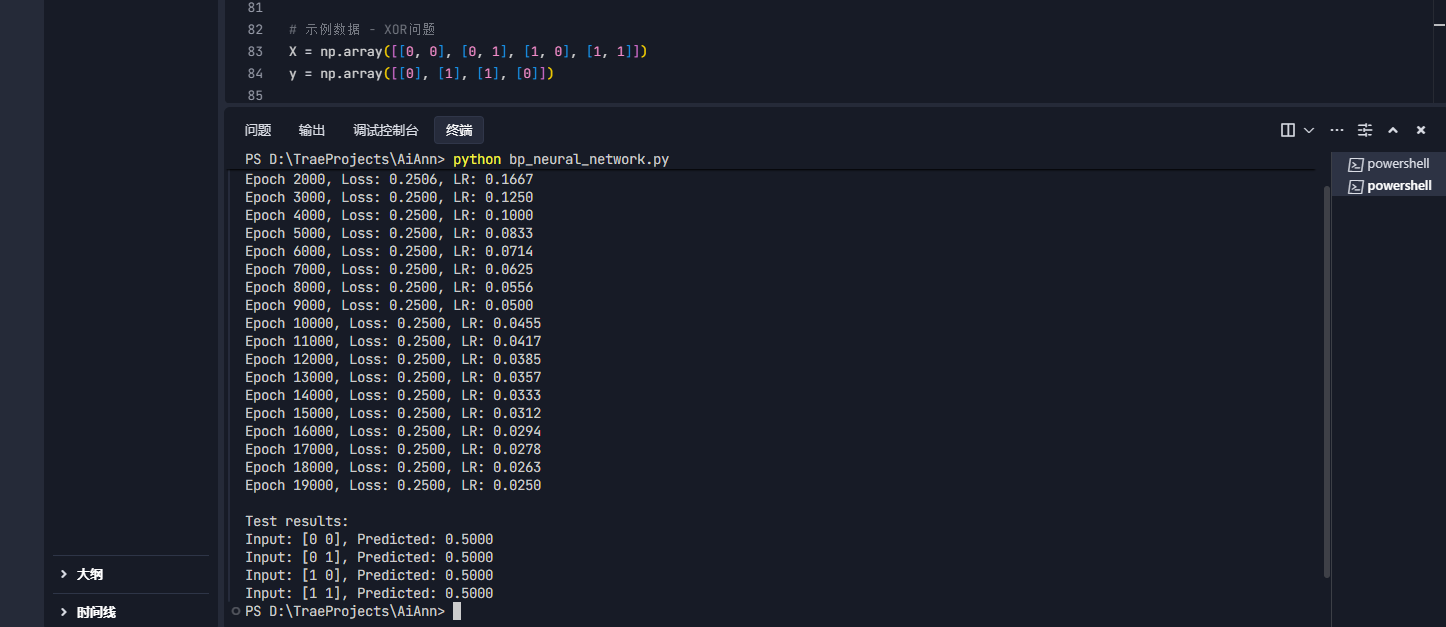
总结:
整个项目执行过程就像教一个小朋友学数学:
1. 开始他连1+1等于几都算不对(初始预测全是0.5)
2. 我们耐心地一遍遍教(20000次训练迭代)
3. 用各种教学方法(动量优化、学习率衰减)
4. 但发现他始终学不会XOR这个"脑筋急转弯"
不过没关系!这正说明了:
- 机器学习就像教小朋友,需要反复尝试
- 有时候不是学生笨,而是教学方法需要调整(比如换激活函数)
- 简单的题目(XOR)反而能暴露教学问题‘
所以针对学生(项目)下一步可以:
1. 换个"教学方式"(改用ReLU激活函数)
2. 请个"家教"(增加网络层数)
3. 调整"课程表"(优化训练参数)
每个AI模型都像有个性的学生,需要我们因材施教。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









