







代码Test.java
public class Test {
public static void main(String[] args) {
int a = 0xae;
int b = 0x10;
int c = a + b;
int d = c + 1;
String s;
s = "hello";
}
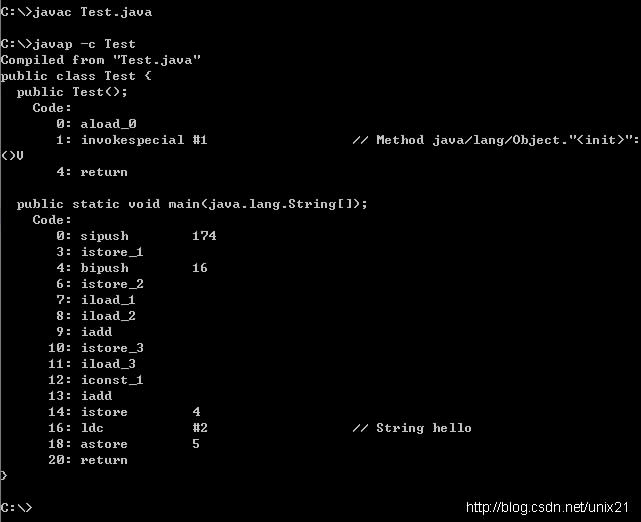
}# javac Test.java
# javap -c Test
参考:http://codemacro.com/2015/03/31/intro-java-bytecode/
*.class文件就已经是编译好的byte code文件,就像C/C++编译出来的目标文件一样,已经是各种二进制指令了。这个时候可以通过JDK中带的javap工具来反汇编,以查看对应的byte code。
JVM中每个指令只占一个字节,操作数是变长的,所以其一条完整的指令(操作码+操作数)也是变长的。上面每条指令前都有一个偏移,实际是按字节来偏移的。
从上面的byte code中,以x86汇编的角度来看会发现一些不同的东西:
局部变量竟是以索引来区分:istore_1 写第一个局部变量,istore_2写第二个局部变量,第4个局部变量则需要用操作数来指定了:istore 4
函数调用invokespecial #1竟然也是类似的索引,这里调用的是Object基类构造函数
常量字符串也是类似的索引:ldc #2
整个class文件完全可以用以下结构来描述:
ClassFile {
u4 magic; //魔数
u2 minor_version; //次版本号
u2 major_version; //主版本号
u2 constant_pool_count; //常量池大小
cp_info constant_pool[constant_pool_count-1]; //常量池
u2 access_flags; //类和接口层次的访问标志(通过|运算得到)
u2 this_class; //类索引(指向常量池中的类常量)
u2 super_class; //父类索引(指向常量池中的类常量)
u2 interfaces_count; //接口索引计数器
u2 interfaces[interfaces_count]; //接口索引集合
u2 fields_count; //字段数量计数器
field_info fields[fields_count]; //字段表集合
u2 methods_count; //方法数量计数器
method_info methods[methods_count]; //方法表集合
u2 attributes_count; //属性个数
attribute_info attributes[attributes_count]; //属性表
}
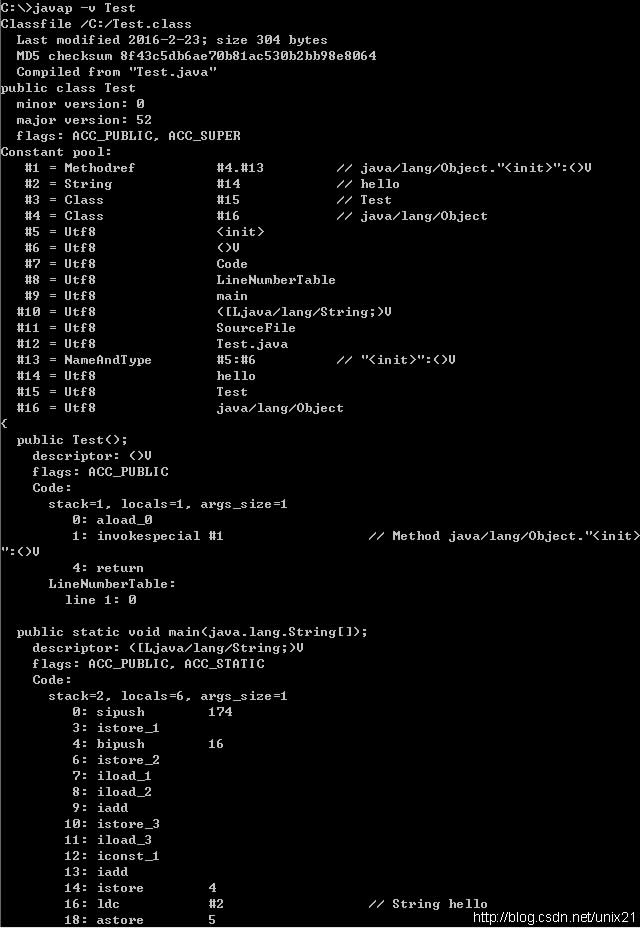
这明显已经不是以区段来分的格式了,上面提到的函数索引、常量字符串索引,都是保存在constant_pool常量池中。常量池中存储了很多信息,包括:
各种字面常量,例如字符串
类、数据成员、接口引用
常量池的索引从1开始。
Java Class文件详解 【写的极好】
常量池的索引从1开始。对于上面例子Test.java,可以使用
# javap -v Test
查看其中的常量池
代码Foo.java
<pre name="code" class="java">public class Foo{
private static final int MAX_COUNT=1000;
private static int count=0;
public int bar() throws Exception{
if(++count >= MAX_COUNT){
count=0;
throw new Exception("count overflow");
}
return count;
}# javac -g Foo.java
# javap -c -s -l -verbose Foo
















 2251
2251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









