







1.什么是Kafka
Kafka是一个高通过率的分布式消息系统

2.消息队列(Message Queue)MQ的模型
消息队列的简单架构图
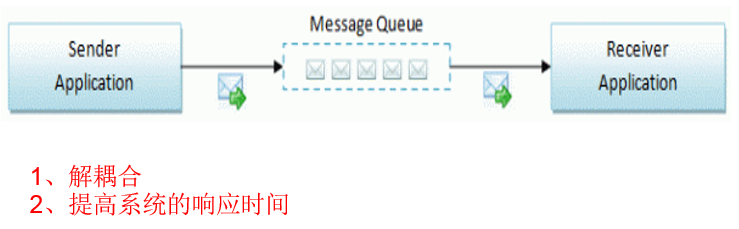
3个核心概念:
Sender Application:消息队列的发送者,也叫生产者producer
Message Queue
Receiver Application:消息接受者,也叫消费者comsumer
消息队列:消息排队,消息就是数据。通过消息模型可以完成一个系统和另一个系统的交互,系统的通信也就是系统与系统的调用。
消息队列容易和SOA混淆
SOA系统是直接的调用,通过代理对另个系统调用,也叫RPC的解决方案。
作为消息的架构和作为SOA的RPC最大的区别:不是直接的调用关系,消息作为异构系统的整合是通过消息的传递完成彼此之间的交互解耦合,彼此之间协调的处理。
消息队列的好处:1.解耦合 没有系统的侵入性 2.提高系统的响应时间
比如订单支付本来是需要完成123,这样会响应等待时间较长。
订单支付成功的方法(){
1、修改订单状态
2、计算会员积分
3、通知物流进行配送
}
改进 :把用户最需要得到的响应操作放在订单支付成功的方法()中
订单支付成功的方法(){
1、修改订单状态
}
另外2个非主要功能可以借用消息系统发送到消息队列中,由消费者来消费。
2、计算会员积分
3、通知物流进行配送
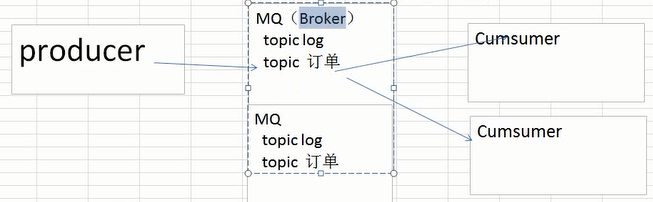
3.消息队列的分类
两种:点对点和发布订阅

点对点问题:
1.如果消息被某个系统消费,但是其他系统就不能再消费
2.为了性能的提高我们还是希望有多点来消费,因为只能有一个消费者,所以这样就无法实现。
所以点对点用的很少。
kafka也属于发布订阅。
4.其他常见消息队列
RabbitMQ:支持的协议多,非常重量级消息队列,对路由(Routing),负载均衡(Load balance)或者数据持久化都有很好的支持。
负载和路由:系统设计中,消息队列也许是要集群,集群就会消息在生产之后往哪个集群中的节点去发送数据。
持久化:有些消息队列可以文件等形式存储消息,目的是以防意外消息丢失。保证消息安全,但是由于其有IO所以性能有损失。
ZeroMQ:号称最快的消息队列系统,尤其针对大吞吐量的需求场景,擅长的高级/复杂的队列,但是技术也复杂,并且只提供非持久性的队列。
不支持持久化。
ActiveMQ:很早出现了,Apache下的一个子项,类似ZeroMQ,能够以代理人和点对点的技术实现队列 。JMS的一个实现者。EJB可以对其访问。
Redis:本质上不是消息队列而是一个key-Value的NoSql数据库,但也支持MQ功能,数据量较小,性能优于RabbitMQ,数据超过10K就很慢,10K之内效率在上面三者之上。
5.Kafka简介
Kafka是伴随大数据产生的,只要处理大数据,主要是内存计算,实时计算。Kafka作为一个非常重要的缓冲者完成内存计算或者实时计算的数据支持。
Kafka 是分布式发布-订阅消息系统,LinkedIn开源,Scala语言编写。
Kafka 是分布式发布-订阅消息系统。是一个分布式的,可划分的(对消息进行分区),多订阅者,冗余备份的持久性的日志服务(消息从生产者发送到kafka之后会存到其日志中)。它主要用于处理活跃的流式数据(几分钟左右,区别有mapreduce的几个小时)。
6.Kafka的特点
1.同时为发布和订阅提供高吞吐量。据了解,Kafka 每秒可以生产约 25 万消息(50 MB),每秒处理 55 万消息(110 MB)。
2.可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费,例如 ETL,以及实时应用程序。通过将数据持久化到硬盘以及 replication 防止数据丢失。
3.分布式系统,易于向外扩展。所有的 producer、broker(对于MQ的表达,消息服务器叫broker) 和 consumer 都会有多个,均为分布式的。无需停机即可扩展机器。扩展需要依赖于zookeeper做节点负载均衡和master节点选举。
4.消息被处理的状态是在 consumer 端维护,而不是由 server 端维护。当失败时能自动平衡。
由哪个 consumer消费,消费了多少Broker不管。Broker只管存消息,删消息,不维护消息状态,是无状态服务。consumer需要zookeeper配合完成,消息来了,需要 consumer 去watch到zookeeper中的变化,zookeeper会记录消费的内容。
5.支持 online 和 offline 的场景。
7.性能测试
结论
参考:http://www.aboutyun.com/thread-9942-1-1.html
8.Kafka的逻辑架构
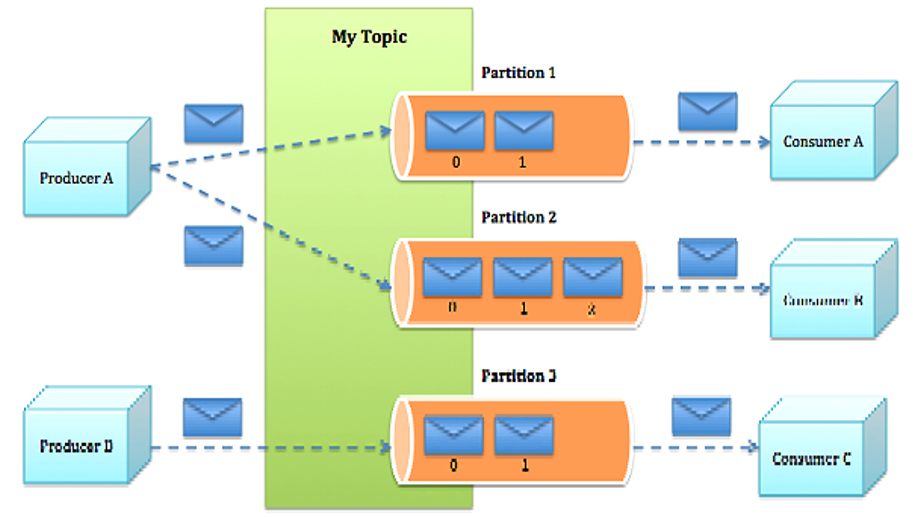
Produces生产消息放到topic中,会有多个topic,消息有分类,不同的消息对应不同的topic。















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









