







 本文通过实例探讨了MySQL中四种事务隔离级别——Read Uncommitted、Read Committed、Repeatable Read和Serializable在防止订单超卖中的应用。重点分析了Read Committed和Repeatable Read如何通过适当的条件避免并发问题,以及Serializable如何确保数据一致性但可能影响性能。结论指出,合理设置事务隔离级别和使用正确的更新条件是防止超卖的关键。
本文通过实例探讨了MySQL中四种事务隔离级别——Read Uncommitted、Read Committed、Repeatable Read和Serializable在防止订单超卖中的应用。重点分析了Read Committed和Repeatable Read如何通过适当的条件避免并发问题,以及Serializable如何确保数据一致性但可能影响性能。结论指出,合理设置事务隔离级别和使用正确的更新条件是防止超卖的关键。
事务的隔离机制是指:
Read Uncommitted(读取未提交内容)
Read Committed(读取提交内容)
Repeatable Read(可重读)
Serializable(可串行化)
具体的解释最经典的MySQL书《高性能MySQL(第3版)》已经有了就不在其他地方再引用了:

隔离机制的比较

其实也有人喜欢用锁来控制并发,书中还提到了“隐式”和“显示锁定”,是这么建议的:

虽然这样,但是其实如果不经过实际的演练还是很难理解上面说的事务隔离机制到底怎么样可以防止并发。
1.查看MySQL版本
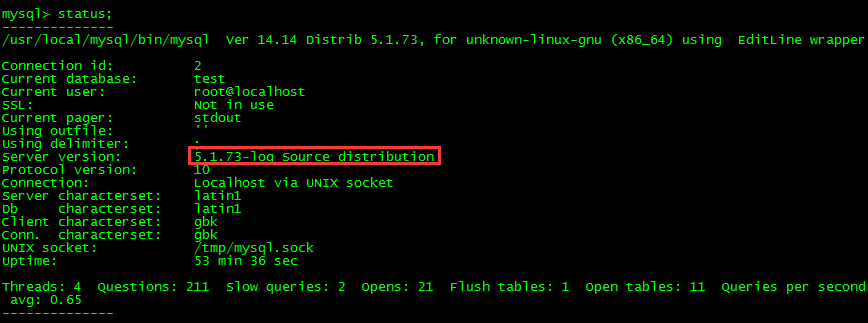
我们的版本是5.1.7
2.查看存储引擎
>show engines;

存储引擎是:InnoDB
3.实验表
假设有个商品表g,关键字段num表示库存,name表示商品名称
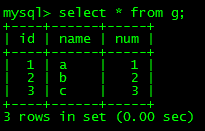
主要就是看不同事务隔离机制下并发修改库存是否会出现超卖。
假设我们的程序需要先查询库存,如果库存>0都可以卖,update扣库存,否则rollback。
为了制造并发肯定需要2个事务,假设是A和B。
4.确认事务隔离机制
修改会话的事务隔离级别
set session transaction isol
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 453
453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









