






ZFS 作为 Solaris 10 和 OpenSolaris 的新特性,吸引了开源社区里很多人的关注, Linux 之父 Linus Torvalds 公开表示对 Solaris 软件的 ZFS ( Zettabyte 文件系统)特别感兴趣,认为该系统管理档案在硬盘的存储方式,具有横跨多个硬盘,同时保持数据完整性的内建功能。但根据他“悲观的”预测, Sun 会想办法阻止 Linux 得到 ZFS 。在这篇文章里面,我想谈谈自己对 ZFS 的认识。
什么是 ZFS
ZFS 文件系统是一个革命性的全新的文件系统,它从根本上改变了文件系统的管理方式,这个文件系统的特色和其带来的好处至今没有其他文件系统可以与之媲美,ZFS 被设计成强大的、可升级并易于管理的。Solaris ZFS 可以说是对传统的磁盘和文件系统管理的革新。操作系统设计在刚刚开始的时候,将磁盘划分为不同的分区( partition ),在每个分区上建立管理数据的文件系统,操作系统通过 read/write 系 统调用,提供对文件系统上的文件的读写访问。随着技术的发展,人们发现这种文件管理方法存在很多问题,其中有两点最为突出,首先,由于文件系统的大小实在 创建文件系统的时候指定的,同时文件系统的大小又受分区大小的限制,而在使用中如果某个文件系统的空间被用满,那除了重新配置系统,别无选择;另外,文件 系统中有一部分空间被文件系统本身有占有,用来存放文件系统的相关信息,比如文件系统的其实块号,大小,根目录节点的 block 号,文件系统的属性等等。这些信息是在创建文件系统的时候,产生的,这就是为什么在一个空文件系统下 du 的时候,仍然发现文件系统空间不是 100 % free 的原因。如果说第二个问题还可以被忍受(毕竟知识一小部分而已)的话,那第一个弊端足驱动人们寻找好的解决方法。 RAID 是很好的解决问题的方法。
RAID ( Redundant Array of Inexpensive Disks ),顾名思义是用多个磁盘组成的磁盘阵列来存储数据,文件系统可以建立在多个磁盘上,这样就可以天马行空了。为了增强数据的安全性,防止阵列中一个硬盘损坏,导致所有数据的丢失, RAID 还提供了冗余信息,使阵列中损坏的磁盘可以被其他磁盘所代替。目前,比较流行的 RAID 包括 RAID0 , RAID1 , RAID5 和它们的复合。
RAID0 提供了 stripe 的功能,及简单的将阵列中的磁盘拼凑在一起,当中的任何一个磁盘的损坏都导致全军覆没; RAID0 提供了 mirror 的功能,即两个相同的磁盘保存同样的内容,这样任意的磁盘坏了,还有另一个顶着,不过成本上升两倍; RAID5 则在多个磁盘(至少 3 个)上同时建立 stripe 和冗余的特性,使磁盘的空间得以扩展,同时通过冗余信息来保证任何一个磁盘的可更换性。
目前, RAID 有 3 种实现方法。第一种, RAID 的功能由硬件来实现,通过购买昂贵的硬件板卡,来搭建 RAID 系统,目前市场上 RAID 控制卡由 LSI , Intel , Qlogic 所瓜分;第二种,在系统的南桥芯片和 BIOS 中加入对 RAID 的功能支持, Intel 的服务器平台上几乎都支持这个功能,这种方法比第一种要便宜很多;第三种,所有 RAID 的功能由操作系统软件来完成,普通的 UNIX/Linux 系统种都通过称为 Volume Manager 的工具对 RAID 功能提供支持,这种方法是最便宜,最容易获得,也是最符合 RAID 名字所包含的含义:便宜。
然而,便宜没好货在这里并没有成为例外。 Volume Manager 工具存在两个缺点,首先,工具使用起来比较复杂。笔者曾经用了一个礼拜的时间去学习 FreeBSD 下面的 Volume Manger 工具,深深的感到其配置文件的晦涩;其次,也是致命的,那就是 RAID5 的 write hole 缺陷。 RAID5 在写数据的时候,是分为两步的,首先将数据写到磁盘阵列上,然后将该 stripe 上数据的校验码记录到阵列上,如果在刚写完数据的时候,系统断电,那么该数据对应的校验码就没有机会再恢复了,长期以往,可以想象。
说了这么多, ZFS 是如何解决这个问题的呢?如下图所示,
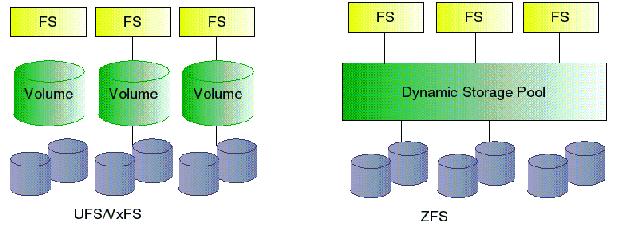
传统的 Volume Manager 不管是用硬件, firmware 还是操作系统的软件实现, volume 都是预先设定好的,文件系统建立在单个 volume 上,不同的 volume 之间的空间不能动态共享,这样文件系统就局限于一个设备,因此文件系统自身会受到该 volume 大小的限制。而 ZFS 文件系统不限于任何特定的设备或 volume ,而是将所有可能的设备都放入一个存储池中,文件系统的大小根据其实际需要在这个池中进行分配,这有点类似于系统对 system memory 的管理方法,基于这样的管理方法, ZFS 文件系统可以充分的利用存储池中的所有存储设备。更可贵的是,所有这一切对用户是透明的,用户可以像创建和删除目录一样,来动态的管理 ZFS 文件系统,当一个文件系统被创建的时候,它会自动的 mount 到系统的文件目录树下,这大大简化了 ZFS 管理的难度。同时,存储池中的设备可以动态的加入,删除或替换,同一个 ZFS 文件系统还可以在不同的系统之间移植。
说了这么多,我们来试试自己创建并管理一个 ZFS ,从而体验一下 ZFS 轻松的管理和强大的功能。
ZFS 的管理
下面的一行命令创建一个 ZFS 存储池:
bash-3.00# zpool create test raidz2 c0t1d0s0 c0t1d0s1 c0t1d0s2 c0t1d0s3
其中 raid2 参数指定在其后的设备上建立一个 RAID - Z 的 RAID ,它类似 RAID5 ,但解决了 RAID 5 软件实现的 write hole 问题。 ZFS 可以提供 4 种 RAID 级别,分别称为 stripe (默认), mirror , RAIDZ1 和 RAIDZ2 。将 raidz2 换为 mirror 或 raidz1 将会创建其他类型的 RAID 。创建好的存储池可以通过下面的命令来查看:
bash-3.00# zpool list
NAME SIZE USED AVAIL CAP HEALTH ALTROOT
test 15.9G 274K 15.9G 0% ONLINE -
bash-3.00# zpool status -v test
pool: test
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
test ONLINE 0 0 0
raidz2 ONLINE 0 0 0
c0t1d0s0 ONLINE 0 0 0
c0t1d0s1 ONLINE 0 0 0
c0t1d0s2 ONLINE 0 0 0
c0t1d0s3 ONLINE 0 0 0
errors: No known data errors
创建完存储池后, ZFS 会在根目录下创建一个和存储池名字相同的目录,并将 ZFS 根文件系统 mount 在该目录下,所有基于该 ZFS 的文件系统都会 mount 在该 ZFS 根文件系统之下,可以通过 -m 参数,将该根目录 mount 在系统目录树的其他位置:
bash-3.00#zpool create -m /export/zfs home c1t0d0
删除一个 ZFS 存储池也比较简单:
bash-3.00# zpool destroy test
如果当前设备正在使用,从而导致该命令不成功,可以使用 -f 参数强行销毁(这里默认你知道这样做的后果)。
创建和删除一个 ZFS 文件系统和创建删除一个目录那么简单:
bash-3.00# zfs create test/home
bash-3.00# zfs destroy test/home
bash-3.00# zfs rename test/home/user test/home/user2
bash-3.00# zfs list
NAME USED AVAIL REFER MOUNTPOINT
test 210K 7.78G 29.9K /test
test/home 56.8K 7.78G 29.9K /test/home
test/home/user2 26.9K 7.78G 26.9K /test/home/user2
这些文件系统一旦被创建,系统自动将他们 mount 在 ZFS 的根目录下,管理员不需要去修改 /etc/vfstab 文件。另外 zfs 命令还可以使用 quota 和 reservation 属性来规定 zfs 文件系统的配额和预留空间。
ZFS 文件系统还提供了快照( snapshot )和克隆( clone )的功能,由于本文章不准备成为一个完整的 ZFS 的 administration guide ,感兴趣的话,可以到 docs.sun.com 上下载相应的文章。
总结
这篇文章简单介绍了 Solaris 10/OpenSolaris 下面 ZFS 相关的背景知识,同时简单介绍了如何创建并管理一个 ZFS 文件系统。关键字: ZFS , OpenSolaris , Volume Manager , ZPOOL.
OpenSolaris使用了一种全新的文件系统zfs,zfs文件系统可以创建快照,对当前文件系统的状态进行记录,从创建快照的时间起,对文 件系统中的内容进行的修改将完全被记录,如删除了一个文件,会在snapshot中保存该文件的一个备份,以备rollback时用。具体操作如下:
1.查看一下当前有哪些文件系统和snapshot:
dguo@opensolaris:~# zfs list
NAME USED AVAIL REFER MOUNTPOINT
rpool 2.62G 4.70G 55K /rpool
rpool@install 16K - 55K -
rpool/ROOT 2.46G 4.70G 18K /rpool/ROOT
rpool/ROOT@install 15K - 18K -
rpool/ROOT/opensolaris 2.46G 4.70G 2.40G legacy
rpool/ROOT/opensolaris@install 61.6M - 2.22G -
rpool/ROOT/opensolaris/opt 3.64M 4.70G 3.60M /opt
rpool/ROOT/opensolaris/opt@install 31K - 3.60M -
rpool/export 162M 4.70G 19K /export
rpool/export@install 15K - 19K -
rpool/export/home 162M 4.70G 162M /export/home
rpool/export/home@install 19K - 21K -
由 于我没有手动创建过文件系统和pool,所以只有一个pool:rpool,在rpool中,系统自动创建了一些文件系统,并创建了相应的 snapshot,如rpool/export/home@install,意思是在rpool中创建了一个export/home的文件系统,zfs文 件系统的特点是创建之后会自动mount,@install的意思是给该文件系统创建了一个snapshot,下面,我们来看一下如何创建自己的 snapshot:
2.创建一个snapshot:
dguo@opensolaris:~# ls
core Desktop test zfs_note
将文件系统rpool/export/home创建了一个snapshot,名为july11。
dguo@opensolaris:~# zfs snapshot -r rpool/export/home@july11
dguo@opensolaris:~# ls
core Desktop test zfs_note
将export/home文件夹下的test目录和zfs_note文件删除
dguo@opensolaris:~# rm -r test/ zfs_note
可以看见相应文件已经没有了。
dguo@opensolaris:~# ls
core Desktop
3.从一个snapshot中恢复:
dguo@opensolaris:~# zfs list
NAME USED AVAIL REFER MOUNTPOINT
rpool 2.62G 4.70G 55K /rpool
……………………………………………………
rpool/export/home@july11 134K - 162M -
可以看出现在多了一个134K的rpool/export/home@july11,该项在删除操作之前的大小为0K,
从该snapshot中恢复:
dguo@opensolaris:~# zfs rollback -r rpool/export/home@july11
可以看出删除的文件都回来了。
dguo@opensolaris:~# ls -l
total 145011
-rw------- 1 dguo staff 148260388 2008-08-06 14:21 core
drwxr-xr-x 2 dguo staff 4 2008-08-09 15:57 Desktop
drwxr-xr-x 2 root root 5 2008-08-01 16:51 test
-rw-r--r-- 1 dguo staff 160 2008-08-11 14:49 zfs_note
4。如果对一个文件系统创建多个snapshot,则恢复到较前的snapshot时,较后的snapshot会丢失,如:
dguo@opensolaris:~# zfs snapshot -r rpool/export/home@july12
dguo@opensolaris:~# zfs list
NAME USED AVAIL REFER MOUNTPOINT
rpool 2.62G 4.70G 55K /
……………………………………………………………………………………………………………
rpool/export/home@july11 92.5K - 162M -
rpool/export/home@july12 0 - 162M -
dguo@opensolaris:~# zfs rollback -r rpool/export/home@july11
dguo@opensolaris:~# zfs list
NAME USED AVAIL REFER MOUNTPOINT
rpool 2.62G 4.70G 55K /rpool
………………………………………………………………………………………………………
rpool/export/home@july11 0 - 162M -
结 论:zfs号称是一个全新的文件系统,与以往的所有文件系统都不同,没有了卷(volume)的概念,所有物理的磁盘组成一个pool,采用类似内存管理 中malloc和free的方法来分配空间,文件系统的大小不必是固定的,而是可以动态增长的。这样可以方便的增加物理磁盘,在服务器上还是很有用的。而 snapshot给普通用户也提供了一个方便的备份系统的工具,看来还真是有些用处的。
zpool create [-fn] [-R root] [-m mountpoint] pool vdev ...
-f 强制执行创建池操作,甚至正在被其他的文件系统所占用
-n 显示配置信息。注:用该参数,该操作并不真正执行
-R 指定整个pool的根目录。也就是所以在这个pool之上的zfs文件系统的mount目录前缀。默认值:/
-m mount点
pool 所要建立的pool的名字
vdev "virtual device".具体说包括三类:disk,file和keywords
disk:就是位于/dev/dsk下的设备文件
file:普通的文件
keywords:包括mirror, raidz, raidz1, raidz2 和 spare
下来我们看几个个例子,
1. 创建一个无冗余的pool。
# zpool create tank c1t4d0
2. 创建一个两路mirror
# zpool create mypool mirror c1t3d0 c1t4d0
3. 创建一个raidz池
# zpool create -f tank raidz2 c2t5d0 c2t4d0 c2t2d0
4. 创建一个带hot spare的池
# zpool create tank c2t5d0 spare c2t4d0
5. 创建一个pool并指定根目录和mount点
# zpool create -f -R /zfsdir -m /root tank c2t4d0# zfs listNAME USED AVAIL REFER MOUNTPOINTtank 91K 16.5G 24.5K /zfsdir/root
/zfsdir 就是以后所有创建与tank 之上的文件系统mount 点前缀,包括tank本身。/root 是mount点。
6. 查看创建一个pool结果,但不真正执行
# zpool create -n -R /zfsdir -m /root tank c2t5d0would create 'tank' with the following layout:tankc2t5d0
相对应于create,自然就有destroy。destroy的语法如下
zpool destroy [-f] pool
-f 强行删除
例如
# zpool destroy tank# zpool create tank c2t5d0# zfs mounttank /tank# cd /tank# zpool destroy tankcannot unmount '/tank': Device busycould not destroy 'tank': could not unmount datasets# zpool destroy -f tank
通过zfs mount查出tank的mount点,然后进入并占用mount目录,这样当试图删除时系统就会报错。用参数-f,系统将删除tank而忽略警告信息。















 2994
2994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









