







第三章 用Python从零实现横向联邦图像分类
3.1 环境配置
在开始本章后面的学习之前,我们先简单介绍本章必要的软件安装与配置,主要包括下面的软件包安装。
- 安装Python环境:本书的代码已在Python 3.7中编译通过,读者可以在Anaconda官网中,根据自己的操作系统平台选择对应的安装版本,参见图3-1。

- GPU环境配置(可选):如果训练中使用的模型是深度学习模型,建议读者使用带有GPU的设备来提升模型训练的速度。为了使深度学习框架支持GPU编程,需要首先安装CUDA和cuDNN。

-
安装PyTorch:在安装Anaconda后,我们可以直接使用pip来安装PyTorch。使用pip的好处是,系统能够自动检测出合适的PyTorch版本,并自动安装依赖库。直接在命令行中输入下面的命令即可。
pip install torch
实际上会遇到很多问题,csdn上博客有很多解决办法,多多尝试
3.2 PyTorch基础
本章使用的机器学习库是基于PyTorch的。PyTorch是由Facebook开源的基于Python的机器学习库[。本节我们简要介绍PyTorch的相关基础知识,包括Tensor的创建、操作、以及自动求导。如果读者想更深入了解PyTorch的使用,请参考PyTorch官方文档。
3.2.1 创建Tensor
Tensor是PyTorch的基础数据结构,是一个高维的数组,可以在跨设备(CPU、GPU等)中存储,其作用类似于Numpy中的ndarray。PyTorch中内置了多种创建Tensor的方式,我们首先导入torch模块。
import torch
- 仅指定形状大小:可以仅仅通过指定形状大小,自动生成没有初始化的任意值,包括empty、IntTensor、FloatTensor等接口。

- 通过随机化函数(PyTorch内置了很多随机化函数)创建具有某种初始分布的值,比如服从标准正态分布的randn、服从均匀分布的rand、服从高斯分布的normal等,一般我们只需要指定输出tensor值的形状。

- 通过填充特定的元素值来创建,比如通过ones函数构建一个全1矩阵,通过zeros函数构建全0矩阵,通过full函数指定其他特征值。

3.2.2 Tensor与Python数据结构的转换
除了上一小节提到的创建方式,PyTorch还可以将已有Python数据结构(如list,numpy.ndarray等)转换为Tensor的接口。PyTorch的运算都以Tensor为单位进行,在运算时都需要将非Tensor的数据格式转化为Tensor,主要的转换函数包括tensor、as_tensor、from_numpy。用户只需要将list或者ndarray数值作为参数传入,即可自动转换为PyTorch的Tensor数据结构。

需要注意的是,as_tensor和from_numpy会复用原数据的内存空间,也就是说,原数据或者Tensor的任意一方改变,都会导致另一方的数据改变。

3.2.3 数据操作
Tensor支持多种数据运算,例如四则运算、数学运算(如指数运算、对数运算等)等。并且,对于每一种数据的操作,PyTorch提供了多种不同的方式来完成。我们以加法运算为例,PyTorch有三种实现加法运算的方式。
- 方式一:直接使用符号“+”来完成。

- 方式二:使用add函数。

- 方式三:PyTorch对数据的操作还提供了一种独特的inplace模式,即运算后的结果直接替换原来的值,而不需要额外的临时空间。这种inplace版本一般在操作函数后面都有后缀“_”。

对于其他的张量四则运算操作,也可以仿照上面的三种方法来完成。Tensor的另一种常见操作是改变形状。PyTorch使用view()来改变Tensor中的形状,如下所示。

Tensor的创建默认是存储在CPU上的。如果设备中有GPU,为了提高数据操作的速度,我们可以将数据放置在GPU中。PyTorch提供了方便的接口将数据在两者之间切换。

如果想将数据重新放置在CPU中,只需要执行下面的操作即可。

3.2.4 自动求导
自动求导功能是PyTorch进行模型训练的核心模块。当前,PyTorch的自动求导功能通过autograd包实现。autograd包求导时,首先要求Tensor将requires_grad属性设置为True;随后,PyTorch将自动跟踪该Tensor的所有操作;当调用backward()进行反向计算时,将自动计算梯度值并保存在grad属性中。下面我们可以通过一个例子来查看自动求导的过程,计算过程如下。

这是一个比较简单的数学运算求解,上面的代码块所要求解的计算公式可以表示为
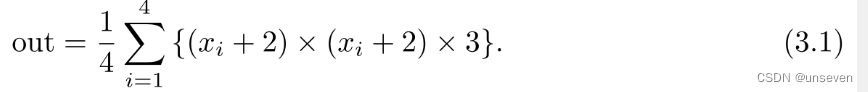
PyTorch采用的是动态图机制,也就是说,在训练模型时候,每迭代一次都会构建一个新的计算图。计算图代表的是程序中变量之间的相互关系,因此,我们可以将式(3.1),表示为如图3-4所示的计算图。
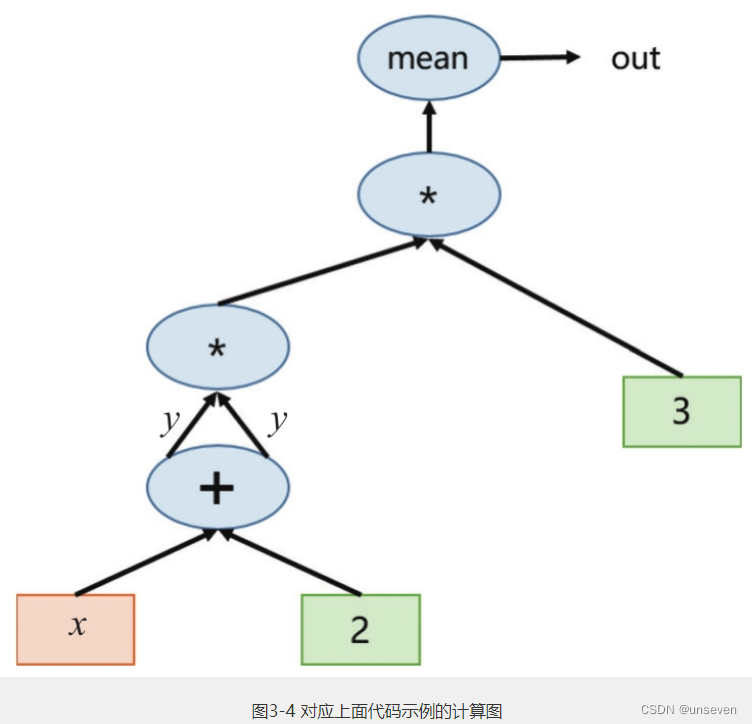
当对out变量执行backward操作后,系统将自动求取所有叶子变量对应的梯度,这里的叶子节点,就是我们的输入变量x:

但应该注意的是,PyTorch在设计时为了节省内存,没有保留中间节点的梯度值,因此,如果用户需要使用中间节点的梯度,或者自定义反向传播算法(比如Guided Backpropagation,GBP),就需要用到PyTorch的Hooks机制,包括register_hook和register_backward_hook。这个技巧在卷积神经网络可视化中经常使用。
通过对式(3.1)进行求导,得到out变量关于x的导数结果如下:
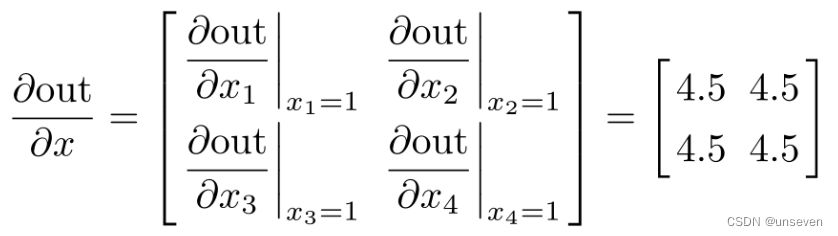
3.3 用Python实现横向联邦图像分类
本节我们使用Python从零开始实现一个简单的横向联邦学习模型。具体来说,我们将用横向联邦来实现对cifar10图像数据集的分类,模型使用的是ResNet-18。我们将分别从服务端、客户端和配置文件三个角度详细讲解设计一个横向联邦所需要的基本操作。
需要注意的是,为了方便实现,本章没有采用网络通信的方式来模拟客户端和服务端的通信,而是在本地以循环的方式来模拟。
3.3.1 配置信息
联邦学习在开发过程中会涉及大量的参数配置,其中比较常用的参数设置包括以下几个。
- 训练的客户端数量:每一轮的迭代,服务端会首先从所有的客户端中挑选部分客户端进行本地训练。每一次迭代只选取部分客户端参与,并不会影响全局收敛的效果,且能够提升训练的效率。
- 全局迭代次数:即服务端和客户端的通信次数。通常会设置一个最大的全局迭代次数,但在训练过程中,只要模型满足收敛的条件,那么训练也可以提前终止。
- 本地模型的迭代次数:即每一个客户端在进行本地模型训练时的迭代次数。每一个客户端的本地模型的迭代次数可以相同,也可以不同。
- 本地训练相关的算法配置:本地模型进行训练时的参数设置,如学习率(lr)、训练样本大小、使用的优化算法等。
- 模型信息:即当前任务我们使用的模型结构。在本案例中,我们使用ResNet-18图像分类模型。
- 数据信息:联邦学习训练的数据。在本案例中,我们将使用cifar10数据集。为了模拟横向建模,数据集将按样本维度,切分为多份不重叠的数据,每一份放置在每一个客户端中作为本地训练数据。
其他的配置信息,比如可能使用到的加密方案、是否使用差分隐私、模型是否需要检查点文件(checkpoint)、模型聚合的策略等,都可以根据实际需要自行添加或者修改。我们将上面的信息以json格式记录在配置文件中以便修改,如下所示。

联邦学习在模型训练之前,会将配置信息分别发送到服务端和客户端中保存,如果配置信息发生改变,也会同时对所有参与方进行同步,以保证各参与方的配置信息一致。
联邦学习在模型训练之前,会将配置信息分别发送到服务端和客户端中保存,如果配置信息发生改变,也会同时对所有参与方进行同步,以保证各参与方的配置信息一致。
3.3.2 训练数据集
按照上述配置文件中的type字段信息,获取数据集。这里我们使用torchvision的datasets模块内置的cifar10数据集。如果要使用其他数据集,可以自行修改。

3.3.3 服务端
横向联邦学习的服务端的主要功能是将被选择的客户端上传的本地模型进行模型聚合。但这里需要特别注意的是,事实上,对于一个功能完善的联邦学习框架,比如我们将在后面介绍的FATE平台,服务端的功能要复杂得多,比如服务端需要对各个客户端节点进行网络监控、对失败节点发出重连信号等。本章由于是在本地模拟的,不涉及网络通信细节和失败故障等处理,因此不讨论这些功能细节,仅涉及模型聚合功能。
下面我们定义一个服务端类Server,类中的主要函数包括以下三种。
- 定义构造函数。在构造函数中,服务端的工作包括:第一,将配置信息拷贝到服务端中;第二,按照配置中的模型信息获取模型,这里我们使用torchvision的models模块内置的ResNet-18模型。torchvision内置了很多常见的模型。模型下载后,令其作为全局初始模型。

- 定义模型聚合函数。前面我们提到服务端的主要功能是进行模型的聚合,因此定义构造函数后,我们需要在类中定义模型聚合函数,通过接收客户端上传的模型,使用聚合函数更新全局模型。聚合方案有很多种,本节我们采用经典的FedAvg算法。FedAvg算法通过使用下面的公式来更新全局模型:

其中,Gt表示第t轮聚合之后的全局模型, L i t + 1 L^{t+1}_i Lit+1表示第i个客户端在第t+1轮本地更新后的模型, G t + 1 G^{t+1} Gt+1表示第t+1轮聚合之后的全局模型。算法代码如下所示。

- 定义模型评估函数。对当前的全局模型,利用评估数据评估当前的全局模型性能。通常情况下,服务端的评估函数主要对当前聚合后的全局模型进行分析,用于判断当前的模型训练是需要进行下一轮迭代、还是提前终止,或者模型是否出现发散退化的现象。根据不同的结果,服务端可以采取不同的措施策略。

3.3.4 客户端
横向联邦学习的客户端主要功能是接收服务端的下发指令和全局模型,并利用本地数据进行局部模型训练。
与前一节一样,对于一个功能完善的联邦学习框架,客户端的功能也相当复杂,比如需要考虑本地的资源(CPU、内存等)是否满足训练需要、当前的网络中断、当前的训练由于受到外界因素影响而中断等。读者如果对这些设计细节感兴趣,可以查看当前流行的联邦学习框架源代码和文档,比如FATE,获取更多的细节。
本节我们仅考虑客户端本地的模型训练细节。我们首先定义客户端类Client,类中的主要函数包括以下两种。
- 定义构造函数。在客户端构造函数中,客户端的主要工作包括:首先,将配置信息拷贝到客户端中;然后,按照配置中的模型信息获取模型,通常由服务端将模型参数传递给客户端,客户端将该全局模型覆盖掉本地模型;最后,配置本地训练数据,在本案例中,我们通过torchvision的datasets模块获取cifar10数据集后按客户端ID进行切分,不同的客户端拥有不同的子数据集,相互之间没有交集。

- 定义模型本地训练函数。本例是一个图像分类的例子,因此,我们使用交叉熵作为本地模型的损失函数,利用梯度下降来求解并更新参数值,实现细节如下面代码块所示。
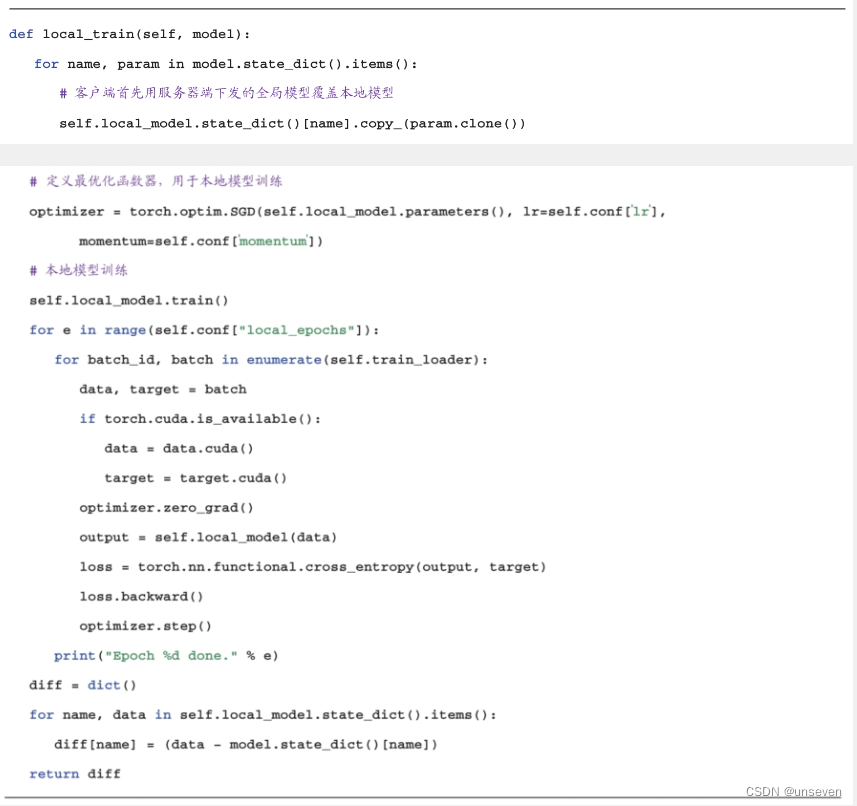
3.3.5 整合
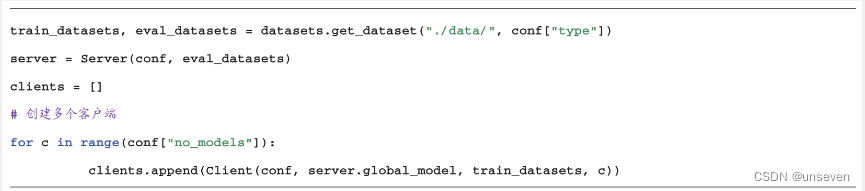
当配置文件、服务端类和客户端类都定义完毕后,我们将这些信息组合起来。首先,读取配置文件信息。

接下来,我们将分别定义一个服务端对象和多个客户端对象,用来模拟横向联邦训练场景。
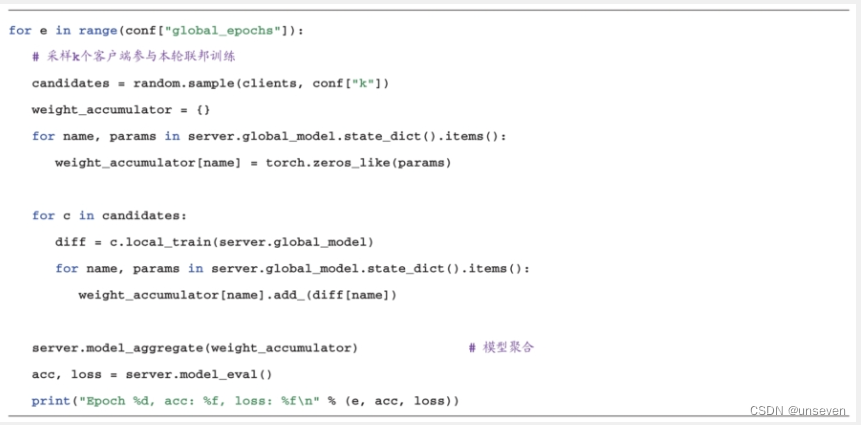
每一轮的迭代,服务端会从当前的客户端集合中随机挑选一部分参与本轮迭代训练,被选中的客户端调用本地训练接口local_train进行本地训练,最后服务端调用模型聚合函数model_aggregate来更新全局模型,代码如下所示。
3.4 联邦训练的模型效果
3.4.1 联邦训练与集中式训练的效果对比
为了对比联邦训练和集中式训练的效果,我们分别按照下面的参数来设置配置文件。
- 联邦训练配置:一共10台客户端设备(no_models=10),每一轮任意挑选其中的5台参与训练(k=5),每一次本地训练迭代次数为3次(local_epochs=3),全局迭代次数为20次(global_epochs=20)。
- 集中式训练配置:不需要单独编写集中式训练代码,只需要修改联邦学习配置便可使其等价于集中式训练。具体来说,将客户端设备no_models和每一轮挑选的参与训练设备数k都设为1即可。这样,只有1台设备参与的联邦训练等价于集中式训练。同时,将本地迭代次数设置为1(local_epochs=1)。其余参数配置信息与联邦学习训练一致。
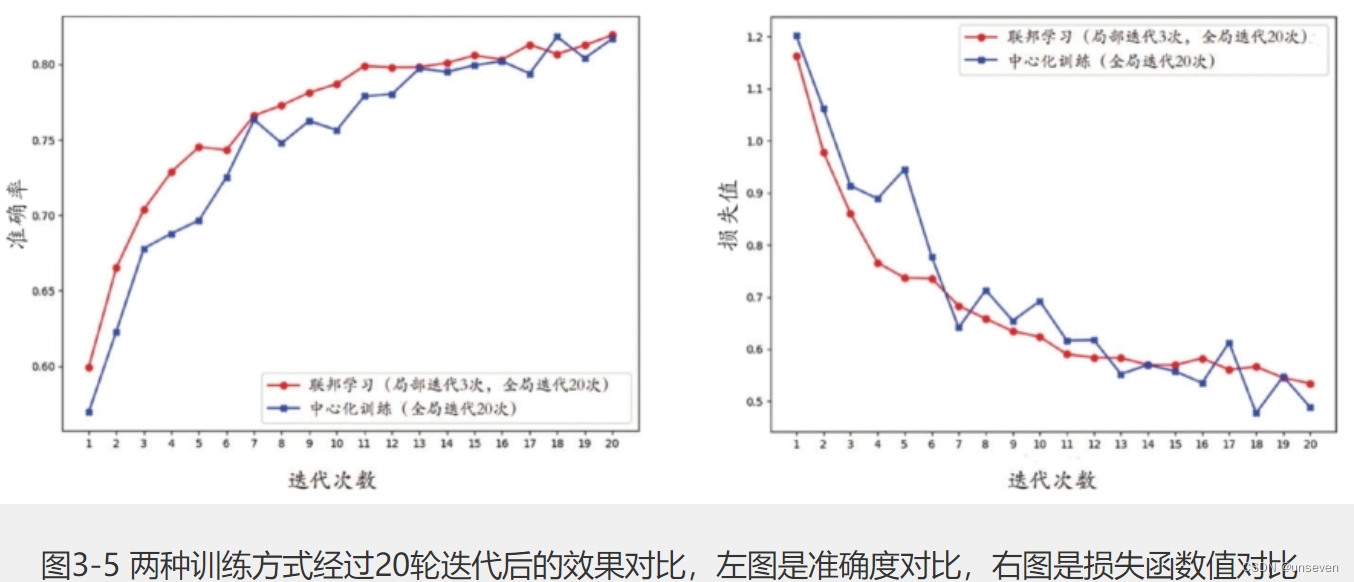
图3-5展示了两种不同的训练方式在cifar10图像分类上的效果对比,可以看到,联邦学习的训练效果与中心化训练的效果基本一样。
3.4.2 联邦模型与单点训练模型的对比
比较模型在推断阶段的性能,如图3-6所示:单点训练模型指的是在某一个单一客户端Ci,利用其本地数据Di进行本地迭代训练的模型,我们分别任意挑选其中的五个客户端来单独训练;联邦训练中分别设置不同的k值,表示每一次本地迭代训练,我们会从所有客户端中挑选k个客户端来进行。在本实验中,分别设置了k=3和k=6两个值。
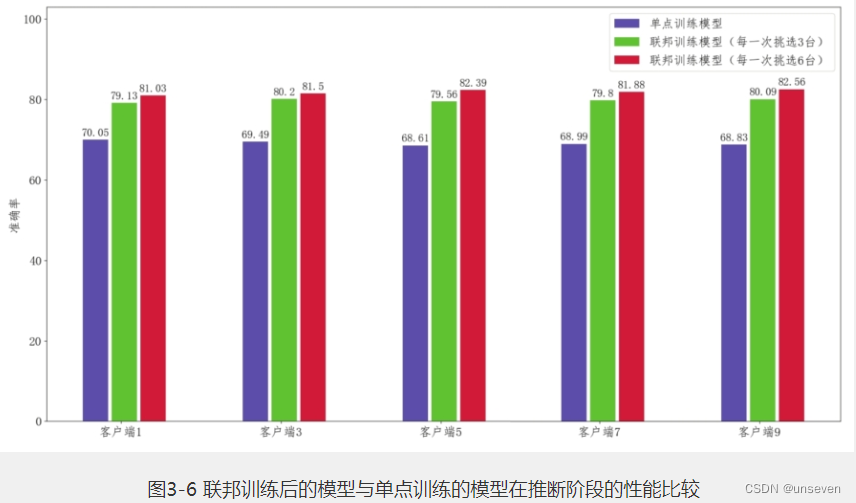
在图3-6中,我们看到单点训练的模型效果(蓝色条)明显要低于联邦训练的模型效果(绿色条和红色条),这说明仅通过单个客户端的数据,不能很好地学习到数据的全局分布特性,模型的泛化能力较差。此外,每一轮参与联邦训练的客户端数目(k值)不同,其性能也会有一定的差别,k值越大,每一轮参与训练的客户端数目越多,性能越好,但每一轮的完成时间也会相对较长。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











