







 本文是关于Spark-Streaming的demo,介绍了如何添加依赖、设置IP和端口参数、使用nc发送数据,以及官方代码的调整。注意需要指定vm options为-Dspark.master=local,否则启动会失败。
本文是关于Spark-Streaming的demo,介绍了如何添加依赖、设置IP和端口参数、使用nc发送数据,以及官方代码的调整。注意需要指定vm options为-Dspark.master=local,否则启动会失败。
Spark-Streaming demo
添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>2.0.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>2.0.2</version>
</dependency>
note:上述版本调试通过,其他版本可能存在jar包依赖冲突问题。
Code
import java.util.Arrays;
import java.util.Iterator;
import java.util.regex.Pattern;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.streaming.Duration;
import scala.Tuple2;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.StorageLevels;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
public class JavaNetworkWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
if (args.length < 2) {
System.err.println("Usage: JavaNetworkWordCount <hostname> <port>");
System.exit(1);
}
// Create the context with a 1 second batch size
/* SparkConf sparkConf = new SparkConf().setAppName("JavaNetworkWordCount");
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.seconds(1));*/
JavaStreamingContext ssc = new JavaStreamingContext("local[2]",
"JavaNetworkWordCount", new Duration(10000));
// Create a JavaReceiverInputDStream on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by 'nc')
// Note that no duplication in storage level only for running locally.
// Replication necessary in distributed scenario for fault tolerance.
JavaReceiverInputDStream<String> lines = ssc.socketTextStream(
args[0], Integer.parseInt(args[1]), StorageLevels.MEMORY_AND_DISK_SER);
System.out.println(lines);
JavaDStream<String> words = lines.flatMap(
new FlatMapFunction<String, String>() {
@Override public Iterator<String> call(String x) {
System.out.println(x);
return Arrays.asList(x.split(" ")).iterator();
}
});
JavaPairDStream<String, Integer> wordCounts = words.mapToPair(
new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
System.out.println(s);
return new Tuple2<>(s, 1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
wordCounts.print();
ssc.start();
ssc.awaitTermination();
}
}
指定IP和端口作为main函数的参数
localhost 1111
note:这里尤其要注意的是,必须指定vm options为-Dspark.master=local,否则不能正常启动spark任务,会报没有指定maser URL 错误。
nc 启动端口并发送数据
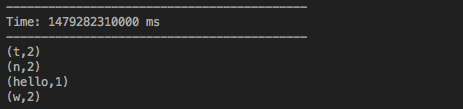
在控制台输入 nc lk 1111 然后输入一串文本回车,就能看到我们统计好的各个单词的个数。
如下图所示:

附官方code
note:官方code是有问题的,需要调整
https://github.com/apache/spark/blob/v2.0.2/examples/src/main/java/org/apache/spark/examples/streaming/JavaNetworkWordCount.java















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









