






根据历年《中国检察年鉴》,整理形成2007-2016年各省级层面犯罪率数据,之前购买的别人的数据,但是发现自己买错了,不需要这个数据,现在分享给大家,为了防止大家和我一样买错,部分数据信息请看附件,请注意没有分年龄阶段的犯罪率!!!有需要的可自取。
目前经管之家的犯罪率数据 基本都是这个数据,大家别买错了。(我就是买错了)
犯罪率指的是犯罪者所占人口比。如每万人中有5人犯罪,则其犯罪率为万分之五。犯罪率是犯罪统计中的重要内容之一,对犯罪问题的研究工作有重要作用。主要分类有犯罪率、少年犯罪率、妇女犯罪率、老年人犯罪率、罪犯重新犯罪率、学生犯罪率等。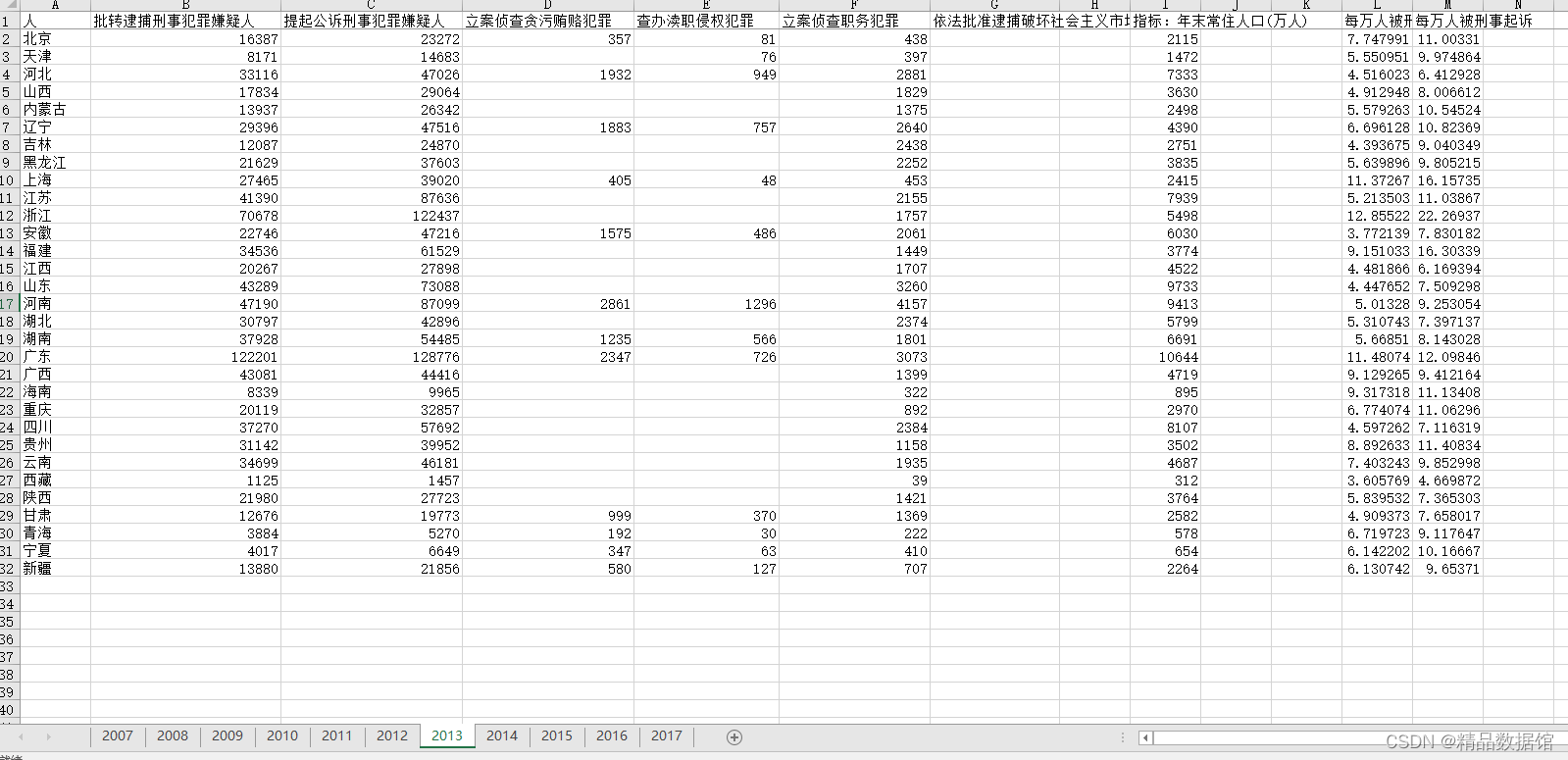
















 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











