







原文说明
为不破坏原文结构,因此功能优化不在原文中维护了。关于这款工具原文请通过下面链接访问。Python制作简易PDF查看工具PDFViewerV1.0
这款小工具基本功能已经可以作为一款文档浏览器使用,但还有一些美中不足的地方,本文将介绍对文本查找功能的优化调整。
查找功能优化
我们先来看一下优化前后的功能对比图片:
1.优化前
查询方式
通过在查找文本框中输入查找内容按回车或者单击工具栏查找按钮完成查找;或者从菜单栏中单击查找工具,在弹出的窗口中输入要查找的内容完成查找。
查询结果展示
查询到的结果在PDF文档下方的文本框中显示,显示查询结果所在的页码、行号和上下文内容,同时PDF页面中对查找结果进行高亮显示。
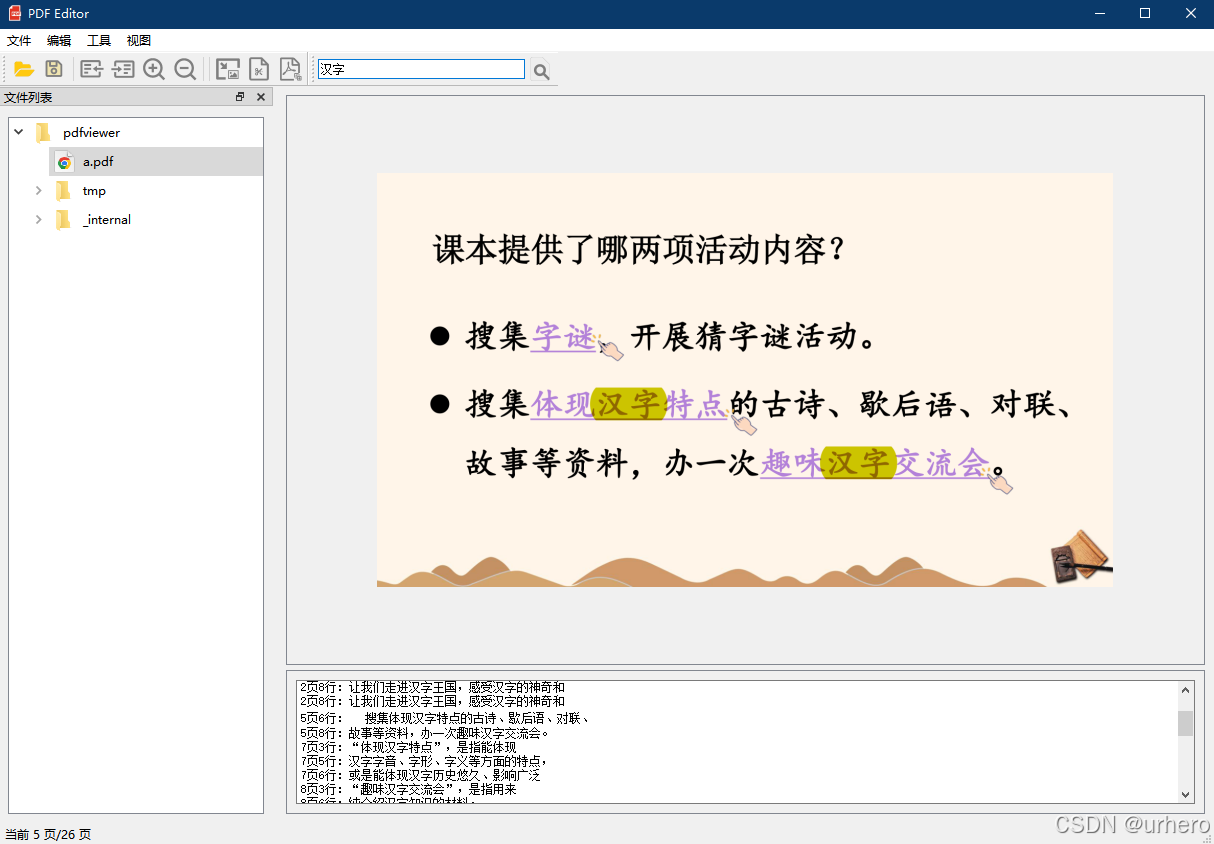
2.优化后
查询方式
查询方式基本不变,可以通过在查找文本框中输入查找内容按回车或者单击工具栏查找按钮完成查找;或者从菜单栏中单击查找工具,在弹出的窗口中输入要查找的内容完成查找。默认将查找工具栏设置为显示,更加便捷。
查询结果展示
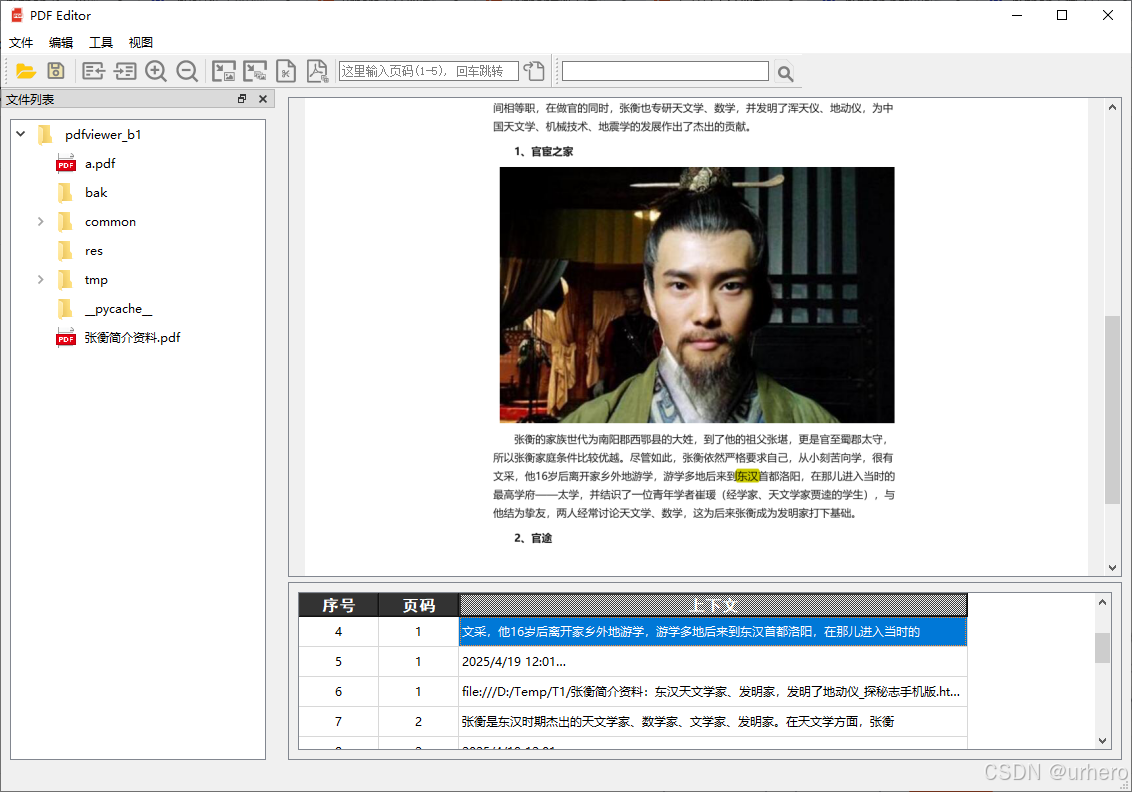
查询到的结果在PDF文档下方的表格中显示,显示查询结果所在的页码和上下文内容(目前行号定位不够准确,将行号去掉了),同时PDF页面中对查找结果进行高亮显示。可以通过单击表格中的结果,PDF页面显示区跳转到文档相应的位置显示,使查看查找结果更加快捷。
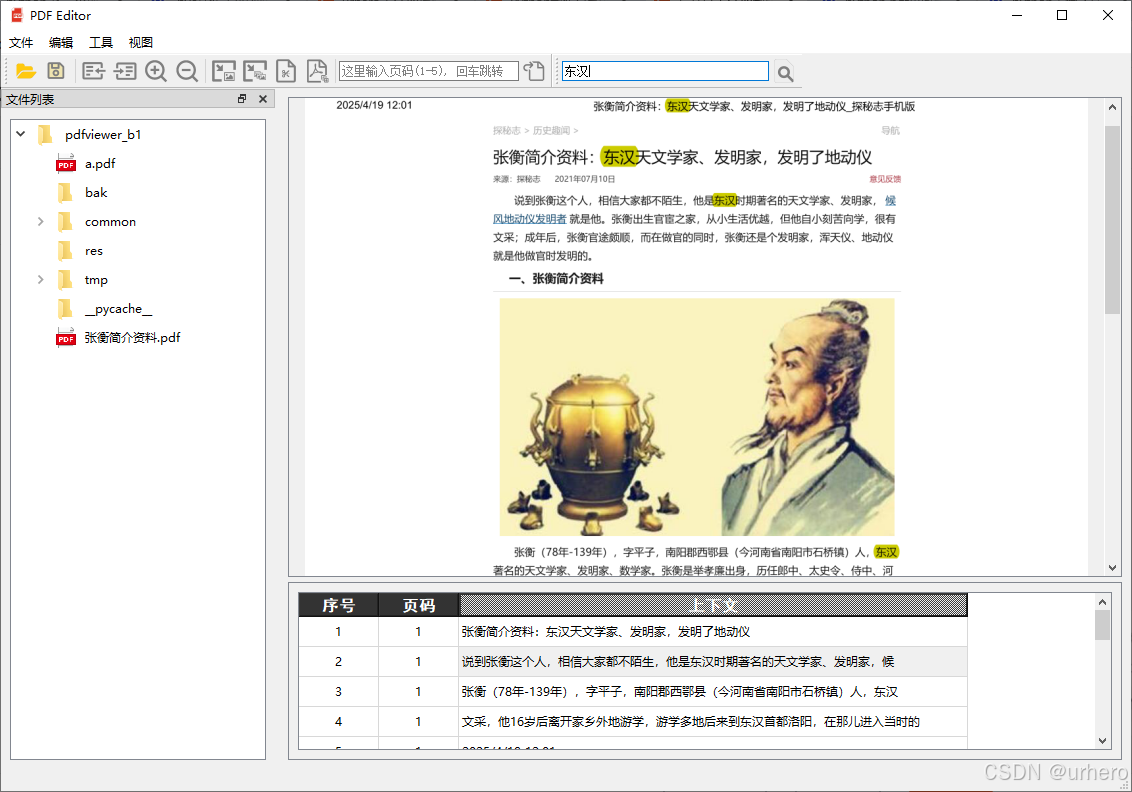
下图是单击第4条查找结果后跳转的效果。
至此本工具的文档查看功能基本完善,目前没有添加导航窗口,只实现了简单的文档浏览,没有对文档进行解析和页面渲染,因此也没有标签窗口,无法通过PDF自身的文档标签实现页面跳转。只能通过翻页及输入页码方式在页面之间跳转,略显不足,后续可能会有完善。
今天就分享到这里,欢迎大家使用,多提宝贵意见。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











