






代码类工具的创建#
依次点击创建新工具、通过代码创建,进入代码类工具的创建流程。您可以一步步依照后文指引,创建一个网页浏览器工具。
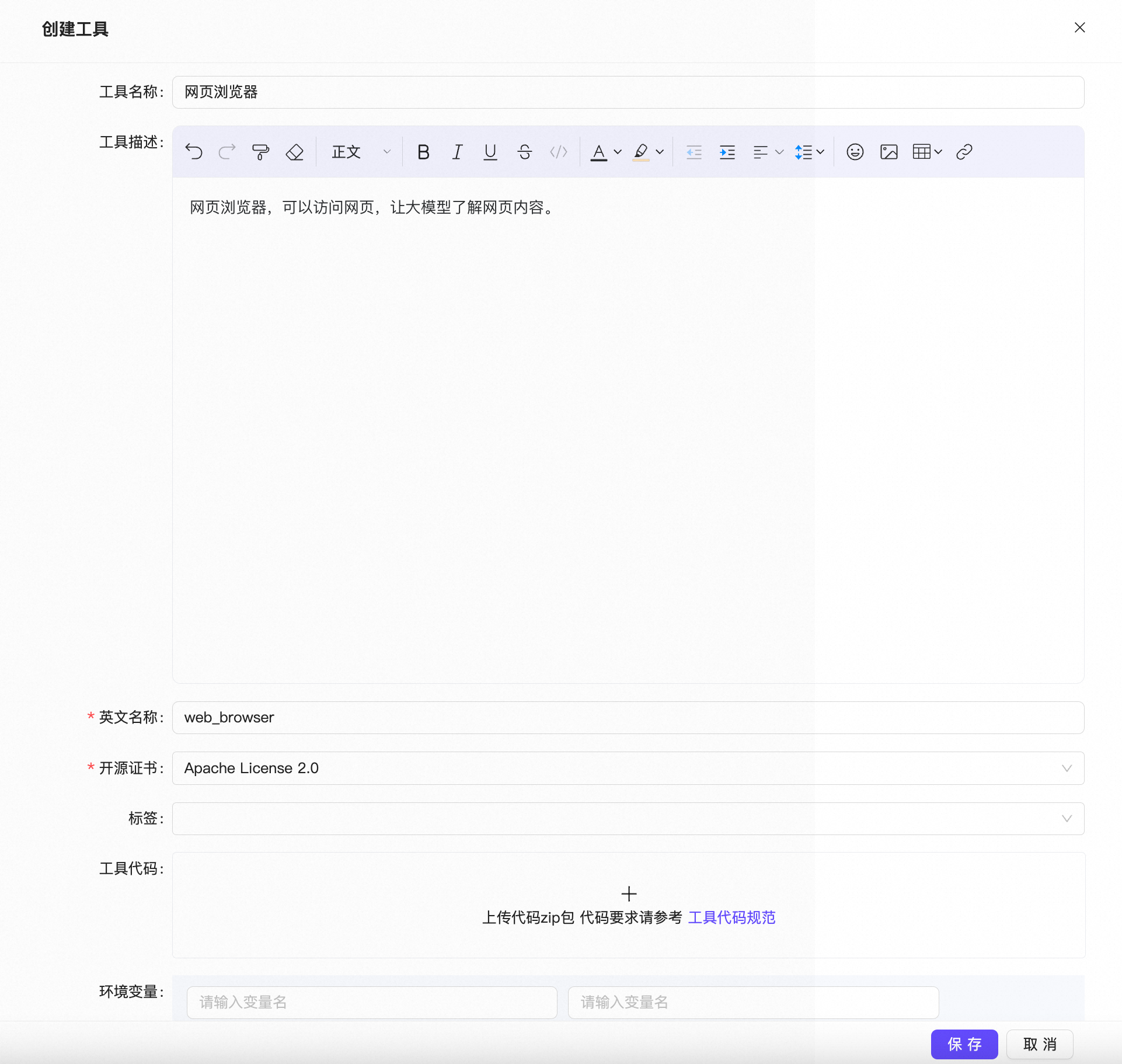
基本信息#
中文名称、封面、开源证书、标签等信息,请按实际情况填写,用于展示在工具列表页面。
英文名称需要与下文代码包中的名字严格对应。
在本示例中,网页浏览器工具的英文名是web_browser。
工具描述#
请介绍该工具的功能,以便用户能在调用的时候能够快速了解该工具的功能以及参数,也可附上作为开发者的信息,可以参考如下的格式进行编写。
网页浏览器,能根据网页url浏览网页并返回网页内容。
输入参数:
`{"urls": "https://blog.sina.com.cn/zhangwuchang"}`
输出结果节选:
`首页 (http://blog.sina.com.cn/u/1199839991) 博文目录 (//blog.sina.com.cn/s/articlelist_1199839991_0_1.html) 各位同学, 今年(二〇二一)是王安石出生的一千周年,我见同学们在网上提及,也要在这里跟同学们热闹一下。说实话,尽管荆公跟我崇拜的苏学士曾经有点过节,我还是敬仰这个人,更欣赏他写下的绝妙好词《桂枝香》。`
具体代码参考:https://github.com/modelscope/modelscope-agent/blob/master/modelscope_agent/tools/web_browser.py
环境变量#
若不希望在代码中展示的信息,可以通过环境变量的方式传入,例如API_KEY等信息。
在本示例中,网页浏览器不需要配置环境变量。
代码Zip包示例#
以下代码可以点击 链接 下载Zip包。
总的来说,用户需要注意的文件有两个:
- 代码本身的入口文件,在本例中为
web_browser.py - 项目层面入口文件
__init__.py
所需的文件的文档结构如下所示:
├── README.md
├── __init__.py
└── web_browser.py
入口代码#
入口文件的代码,与在主库中新增一个tool的流程完全一样,值得注意的是工具的英文名与register_tool注册名必须对齐统一。
web_browser.py代码如下(您也可以到GitHub查看最新代码):
import base64 import httpx from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.document_loaders import (AsyncChromiumLoader, AsyncHtmlLoader) from langchain_community.document_transformers import BeautifulSoupTransformer from modelscope_agent.tools.base import BaseTool, register_tool @register_tool('web_browser') class WebBrowser(BaseTool): description = '网页浏览器,能根据网页url浏览网页并返回网页内容。' name = 'web_browser' parameters: list = [{ 'name': 'urls', 'type': 'string', 'description': 'the urls that the user wants to browse', 'required': True }] def __init__(self, cfg={}): super().__init__(cfg) self.headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)' } self.client = httpx.Client( headers=self.headers, verify=False, timeout=30.0) self.cfg = cfg.get(self.name, {}) self.use_advantage = self.cfg.get('use_adv', False) def call(self, params: str, **kwargs) -> str: params = self._verify_args(params) if isinstance(params, str): return 'Parameter Error' urls = params['urls'] print(urls) if urls is None: return '' if self.use_advantage: text_result, image_result = self.advantage_https_get( urls, **kwargs) else: text_result = self.simple_https_get(urls, **kwargs) return text_result def advantage_https_get(self, urls, **kwargs): try: from playwright.sync_api import sync_playwright except ImportError: return ( 'Please install playwright with chromium kernel by running `pip install playwright` and ' '`playwright install --with-deps chromium`') if isinstance(urls, list): urls = urls[0] with sync_playwright() as p: browser = p.chromium.launch() page = browser.new_page() page.goto(urls) text_result = page.evaluate('() => document.body.innerText') screenshot_bytes = page.screenshot(full_page=True) screenshot_base64 = base64.b64encode(screenshot_bytes).decode( 'utf-8') browser.close() return text_result, screenshot_base64 def simple_https_get(self, urls, **kwargs): # load html and get docs loader = AsyncHtmlLoader(urls) docs = loader.load() result = self._post_process(docs, **kwargs) return result def _post_process(self, docs, **kwargs): # make sure parameters could be initialized in runtime max_browser_length = kwargs.get('max_browser_length', 2000) split_url_into_chunk = kwargs.get('split_url_into_chunk', False) # Transform bs_transformer = BeautifulSoupTransformer() docs_transformed = bs_transformer.transform_documents( docs, tags_to_extract=['span']) # split url content into chunk in order to get fine-grained results if split_url_into_chunk: # Grab the first 1000 tokens of the site splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( chunk_size=1000, chunk_overlap=0) splits = splitter.split_documents(docs_transformed) else: splits = docs_transformed search_results = '' for item in splits: search_results += item.page_content + '\n' return search_results[0:max_browser_length]
解读:
-
line10:
@register_tool('web_browser')用于将该工具类注册到注册中心以便后续调用, 并取名为web_browser。注意:为了能够正确调用,该名字需要与工具的英文名对齐统一,也同时需要与代码中的name = 'web_browser'统一。 -
line 12-19: 工具在被大模型调用的时候,所有需要的信息都会被定义在这部分,不同的工具对应的
name,description必须要描述清晰,以便大模型能够正确的使用该工具。 与此同时,parameters需要严格按照上述格式进行定义,以便模型能够正确生成调用该工具的参数,参数需要包括:name,description,required和type。 -
line 21:
__init__()方法可以把,一些非运行时相关的配置加在这里。 -
line 22:
self.cfg = cfg.get(self.name, {})对于一些配置较多,或者需要配置来自于文件的场景,可以使用该方法来初始化一个工具。 -
line 31:
call()方法定义了该工具使用参数进行任务执行的具体方法,注意入参即为上一步中大模型生成的parameters,并且以string的方式传入。 -
line 33:
params = self._verify_args(params)该方法用parse,stringify的 parameters成为dict,我们已经有默认方法得以实现。 针对一些模型生成效果不好的场景,或者需要有特殊解析逻辑的场景,用户可以自行实现该类。
其余文件#
项目文件的__init__.py方法需要将上述代码注册入口文件引入进来,以便能够正确注册tool到系统中。 在本代码例子中需要添加如下代码到, __init__.py
from .web_browser import WebBrowser
代码类工具的修改#
您可以在工具的列表页中,在需要修改的工具上依次点击更多、编辑,进入代码类工具的修改。
您可以直接修改表单的信息。可以通过git或者上传新的zip包两种方式修改具体代码。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









