







🌈据说,看我文章时 关注、点赞、收藏 的 帅哥美女们 心情都会不自觉的好起来。
前言:
🧡作者简介:大家好我是 user_from_future ,意思是 “ 来自未来的用户 ” ,寓意着未来的自己一定很棒~
✨个人主页:点我直达,在这里肯定能找到你想要的~
👍专栏介绍:猿人学WEB题目专解 ,提供猿人学WEB题目总计20题的解题思路与方法,如有讲述错误,请不吝赐教。
想看往期历史文章,可以浏览此博文: 历史文章目录,后续所有文章发布都会同步更新此博文~

题目网址
题目详情
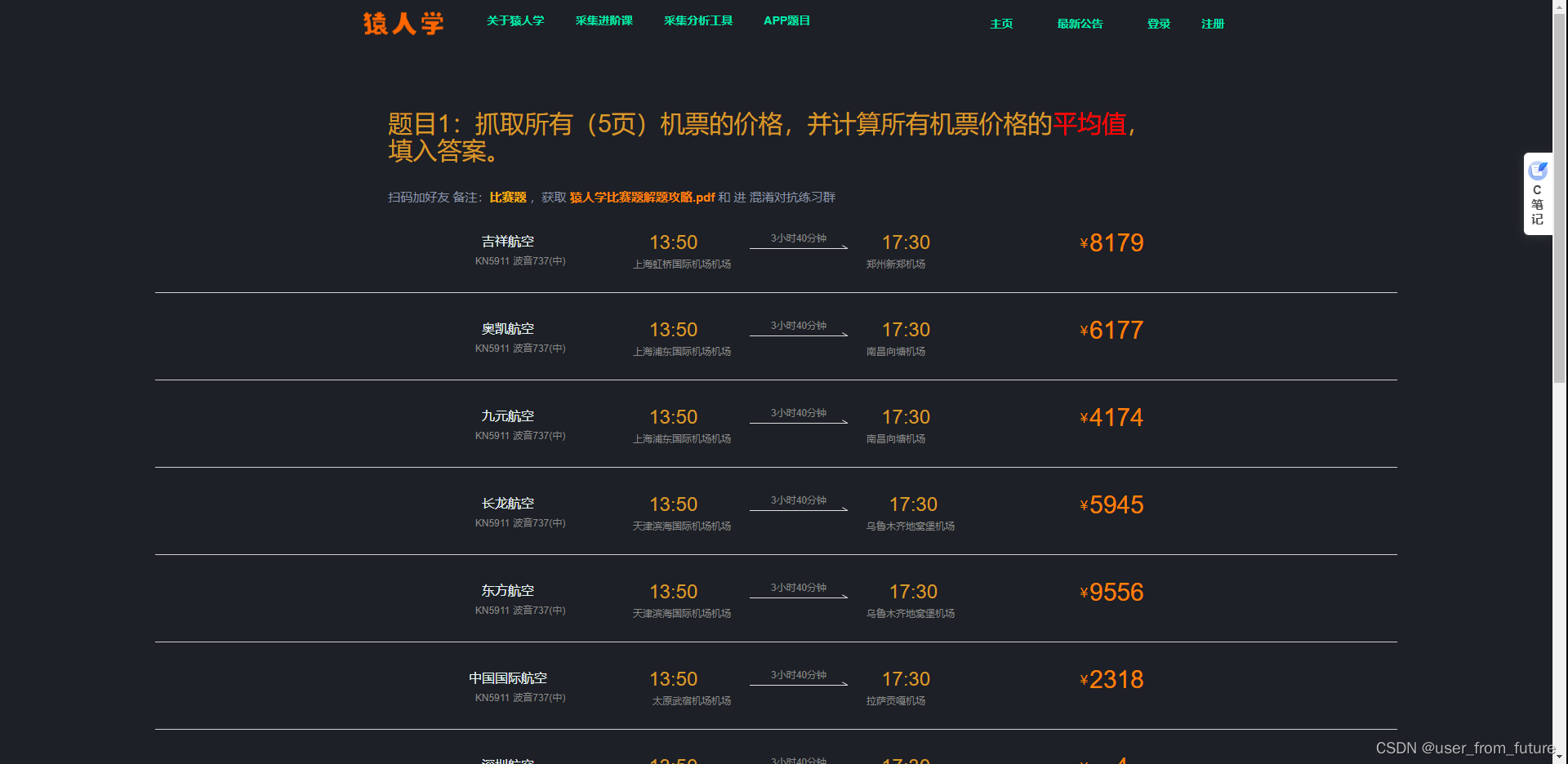
让我们计算计算所有机票价格的 平均值 。
题目思路
首先肯定要打开开发者工具,刚上来就给了我们一个下马威,我们先不管他,刷新一下,加载出这个网页的资源:
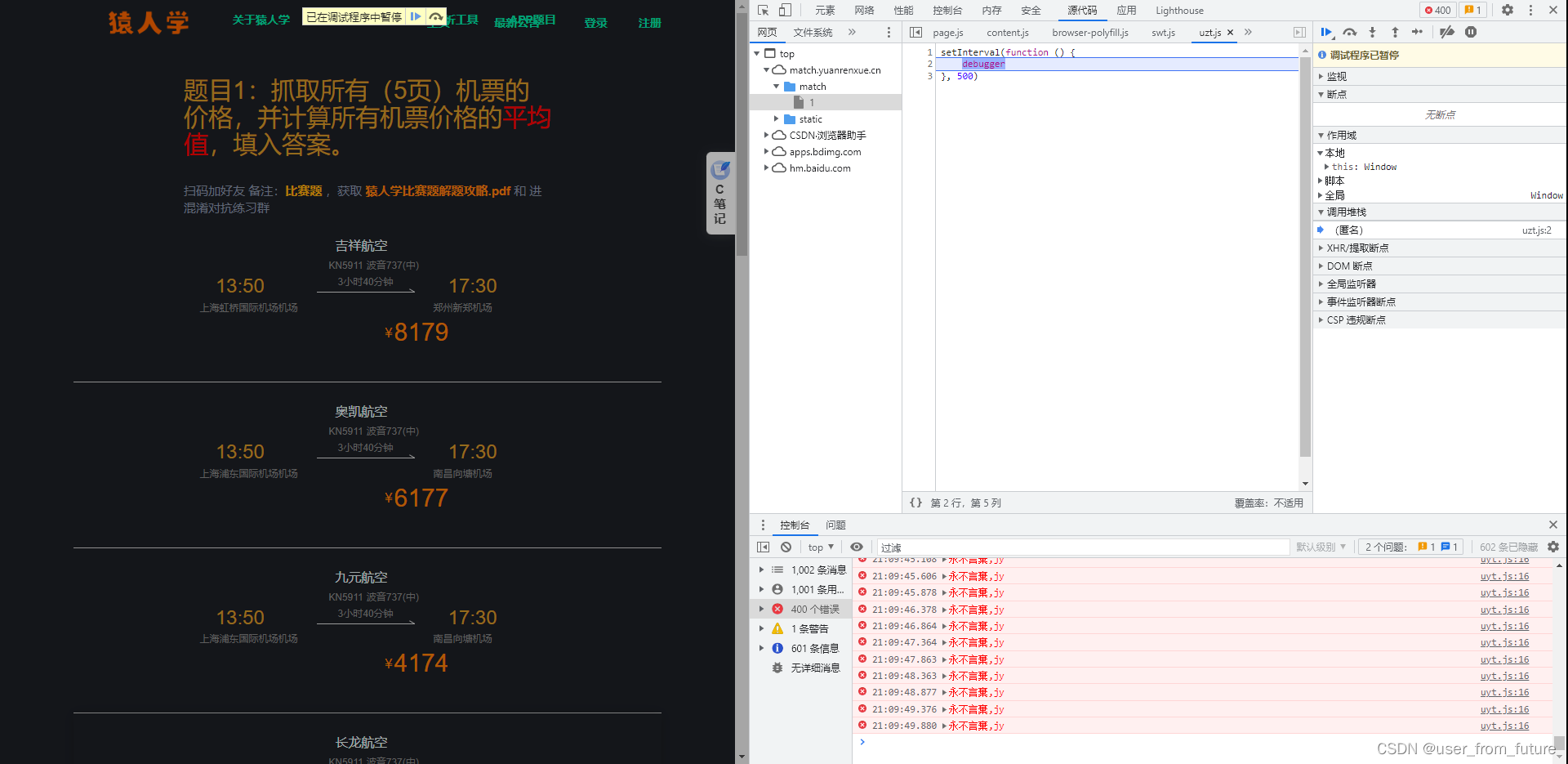
然后再看这个下马威:无限 Debug + 控制台输出污染,然后每次点下蓝色小箭头,控制台就会输出一次错误。

先尝试选择一律不在此暂停,然后点蓝色小箭头,发现 Debug 虽然不会弹出了,然下方依旧会有错误输出:
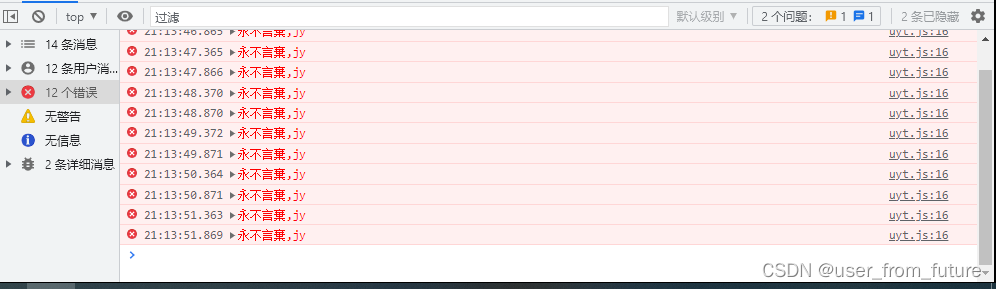
这时候为了我们干净的控制台,我们选择直接把 console.error 给屏蔽了,加上这行代码:console.error = function(){},瞬间他就不输出了,我们可以安安静静的开始继续分析了。
在网络一栏中,可以很明显的看到第一页是 https://match.yuanrenxue.cn/api/match/1?m=XXX,点击第二页出现 https://match.yuanrenxue.cn/api/match/1?page=2&m=XXX ,这下可以明白需要 page 页数和加密的参数 m 了,再看看载荷,m 是由两段参数组成的,左边未知,右边疑似时间戳,每次请求两边都会变,说明左边的很可能是由时间戳控制的,也有可能有随机数在里面。
点开启动器,查看请求调用堆栈:
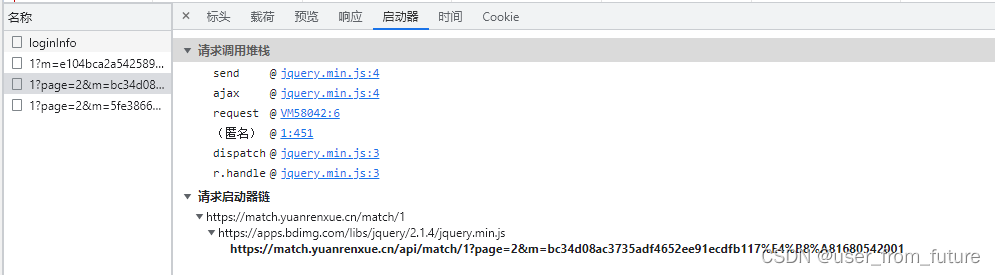
很明显是由那个 request 方法发起的请求,点进去就看到了让人想放弃的代码:

很明显这段代码经过了Obfuscator混淆,正常人根本就难以看懂,一看给他的难度定义居然是简单,大家这里不要对自己的能力产生怀疑,看着难的,说明是第一次接触这个,多接触接触,就习惯了。
其实看到这已经可以猜出来了,这用的是 jQuery 框架,$['\x61\x6a\x61\x78'] 这里就应该是 $['get'] 方法,window['\x75\x72\x6c'] 这里是请求的 url地址,猜都猜出来是 /api/match/1 了。![] 可能很少遇到,但是到了混淆这里,经常遇到,![] 就是 false 的意思(因为在JavaScript,[] 代表 true),看这三元表达式就能看出来:

所以 _0xb89747 = _0x5d83a3 就是上面那个字典是请求的两个参数,第一个参数一看大致是当前时间戳 + 100000000,但是我们搜索第二个参数的方法名称 oo0O0 的时候,发现搜不到定义的地方!解个题变成侦探了,想找到函数的蛛丝马迹。
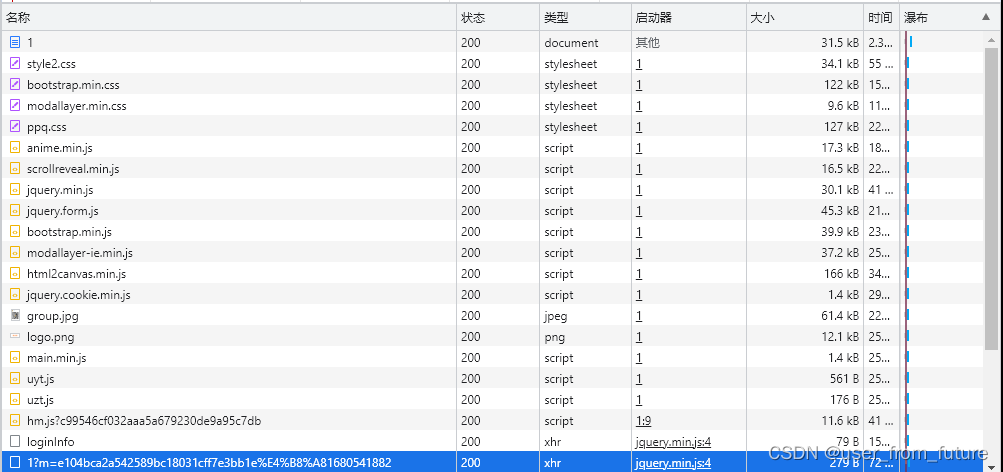
看一眼请求列表,经过排除,发现在请求前,唯一可以提供函数方法就是在页面本身,于是我们打开当前页面源代码,搜索这个函数,发现确实找的到:
function oo0O0(mw) {
window.b = '';
for (var i = 0, len = window.a.length; i < len; i++) {
console.log(window.a[i]);
window.b += String[document.e + document.g](window.a[i][document.f + document.h]() - i - window.c)
}
var U = ['W5r5W6VdIHZcT8kU', 'WQ8CWRaxWQirAW=='];
var J = function(o, E) {
o = o - 0x0;
var N = U[o];
if (J['bSSGte'] === undefined) {
var Y = function(w) {
var m = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789+/=',
T = String(w)['replace'](/=+$/, '');
var A = '';
for (var C = 0x0, b, W, l = 0x0; W = T['charAt'](l++); ~W && (b = C % 0x4 ? b * 0x40 + W : W, C++ % 0x4) ? A += String['fromCharCode'](0xff & b >> (-0x2 * C & 0x6)) : 0x0) {
W = m['indexOf'](W)
}
return A
};
var t = function(w, m) {
var T = [],
A = 0x0,
C, b = '',
W = '';
w = Y(w);
for (var R = 0x0, v = w['length']; R < v; R++) {
W += '%' + ('00' + w['charCodeAt'](R)['toString'](0x10))['slice'](-0x2)
}
w = decodeURIComponent(W);
var l;
for (l = 0x0; l < 0x100; l++) {
T[l] = l
}
for (l = 0x0; l < 0x100; l++) {
A = (A + T[l] + m['charCodeAt'](l % m['length'])) % 0x100, C = T[l], T[l] = T[A], T[A] = C
}
l = 0x0, A = 0x0;
for (var L = 0x0; L < w['length']; L++) {
l = (l + 0x1) % 0x100, A = (A + T[l]) % 0x100, C = T[l], T[l] = T[A], T[A] = C, b += String['fromCharCode'](w['charCodeAt'](L) ^ T[(T[l] + T[A]) % 0x100])
}
return b
};
J['luAabU'] = t, J['qlVPZg'] = {}, J['bSSGte'] = !![]
}
var H = J['qlVPZg'][o];
return H === undefined ? (J['TUDBIJ'] === undefined && (J['TUDBIJ'] = !![]), N = J['luAabU'](N, E), J['qlVPZg'][o] = N) : N = H, N
};
eval(atob(window['b'])[J('0x0', ']dQW')](J('0x1', 'GTu!'), '\x27' + mw + '\x27'));
return ''
}
看到 return 后居然没有返回值,那问题一定是出在那个 eval 函数里了,可以看到肯定和 window['b'] 有关,我们打印一下 window['b'] ,刷新几次,发现 window['b'] 是一个固定的值,是被 base64 加密了,所以我们直接去控制台获取一下 window['b'] 这个值,太长了自己去复制吧。
用 Python 手动处理 atob 函数,对 window['b'] 进行 bae64 解码操作:base64.b64decode('[window.b]').decode() ,可以在浏览器里输入 atob(window['b']) 预览一下:

发现是经过一段处理,最后处理成 md5 的十六进制数据,赋值给了 window.f 这个变量,猜测这个 window.f 就是我们最终想要的结果,打印一看,标标准准:
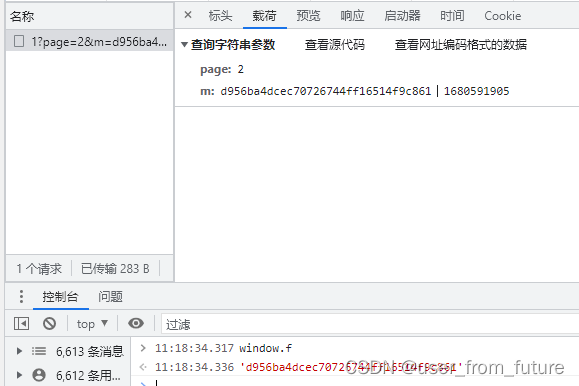
那我们就直接执行这段 base64 加密的代码,最终取出 window.f 就可以了:
t = int(time.time()) * 1000 + 100000000
js = f"function main(mwqqppz) {{window = this; {base64.b64decode('[window.b]').decode()}; return window.f}}"
m = execjs.compile(js).eval(f"main('{t}')")
url = f"https://match.yuanrenxue.com/api/match/1?page={index}&m={m}丨{t // 1000}"
这样就获取到了我们的 url 地址,接下来的请求就简单了,直接看最后的源码就可以。
解题源码
import os
import time
import base64
import execjs
import requests
import jsonpath
os.environ["EXECJS_RUNTIME"] = "Node"
headers = {
'cookie': 'sessionid=htsmcpjmxxml7f7q1g8fwticn5verjit',
'User-Agent': 'yuanrenxue.project'
}
js = f"function main(mwqqppz) {{window = this; {base64.b64decode('[window.b]').decode()}; return window.f}}"
value = 0
for index in range(1, 6):
# 趁爬虫没有反应过来写死 m 的参数直接访问
# url = f"https://match.yuanrenxue.com/api/match/1?page={index}&m=c7c34cd9971e286bb60664eb3ca5b73c丨1680087702"
# 通过 js 生成 m 参数
t = int(time.time()) * 1000 + 100000000
m = execjs.compile(js).eval(f"main('{t}')")
url = f"https://match.yuanrenxue.com/api/match/1?page={index}&m={m}丨{t // 1000}"
# value += sum(v['value'] for v in requests.get(url, headers=headers).json()['data'])
value += sum(jsonpath.jsonpath(requests.get(url, headers=headers).json(), '$..value'))
print(value / 50)















 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









